













深度解析蘋果A12處理器:性能和能耗比令安卓旗艦SoC汗顏
過去的幾年里,蘋果的芯片設計團隊一直在架構設計和制造工藝兩條路線上穩居業界最前沿,此番隨新一代iPhone XS一齊亮相的A12處理器同樣保持了這份優良傳統,它是業界***個實現量產應用的7nm移動SoC芯片。
此前在雷鋒網《詳細解讀7nm制程》一文中我們曾介紹過,一般來說制程的數字越小,晶體管的Metal Pitch和Gate Pitch等特征尺寸就越小。雖然最近幾年制程的命名逐漸脫離了與實際物理尺寸之間的關聯而轉向商業化名稱,但它們仍然代表著晶體管密度的飛躍,供應商能夠在相同的芯片面積中塞入更多晶體管以提升性能。
不久前,外媒TechInsights對iPhone XS進行了拆解并為A12芯片進行了X光掃描,我們可以借由他們分享的透視圖對A12進行一波深入的分析和猜想。

A12的主要性能模塊均位于芯片的右方和下方,其中最右側是占地面積***的GPU集群,4顆核心2*2對稱排列,將一小塊公用電路夾在中間。左側緊挨著GPU集群中腰的是CPU和GPU的共享緩存(L3緩存),下方是低功耗CPU核心集群,左方是的高性能CPU核心集群,最左邊則是8核NPU。
GPU和CPU的共享緩存是整個SoC緩存體系的一部分,層級位于內存控制器和獨占緩存之間。由于處理器訪問內存要消耗掉大量電力,使用片上共享緩存可以節能降耗,且由于數據的局部性,性能還會有所提升。
從圖上可以看出,A12的共享緩存被劃分成了4個區塊,而此前自A7至A11這5代處理器均為2區塊設計。緩存區塊的加倍很有可能代表著緩存性能有了很大提升,這個在稍后的測試中再見分曉。
***, NPU可以說是此次A12中進化幅度***的一個性能模塊,核心數從A11的雙核激增為8核,實際性能更是從A11的0.6TOP暴漲至5TOP,提升近9倍。需要注意的是,有傳言稱此前A11的NPU使用的是CEVA的架構設計,不過直到現在也沒有得到證實,而此次蘋果A12的網頁上明確提到了“Apple-designed”,這意味著這次的NPU架構的確是出自蘋果的自主研發。
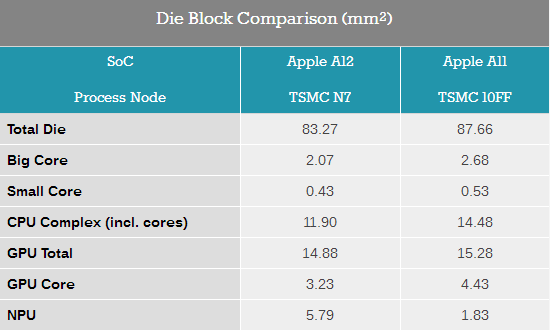
縱觀A11和A12中不同模塊的面積變化,可以清晰的看到臺積電全新7nm制程的優勢。鑒于幾乎所有的模塊架構都有了變化,無法計算出7nm制程的晶體管密度有多大提升,不過若以單個GPU核心作為參考,在A12中相比A11中的面積減小了37%。
更大的CPU和緩存結構
此次A12的大核心代號為“Vortex(旋風)”,相比A11的“Monsoon(季風)”***的改進在于L1數據緩存和指令緩存雙雙翻倍,均從64KB增加到了128KB。人們一直很想搞清楚的一個問題是,蘋果處理器的緩存體系到底具有怎樣的結構,現在我們可以通過使用不同隊列深度測試內存延遲來一窺端倪。

測試結果是,L1緩存的延遲拐點從64KB轉移到了128KB,這很正常,但在L2緩存的延遲在3MB~6MB范圍內會一直持續增加,而這種情況僅在以完全隨機的模式訪問時發生,在較小的訪問窗口中,L2緩存的延遲從3MB到6MB又是一直平坦的。
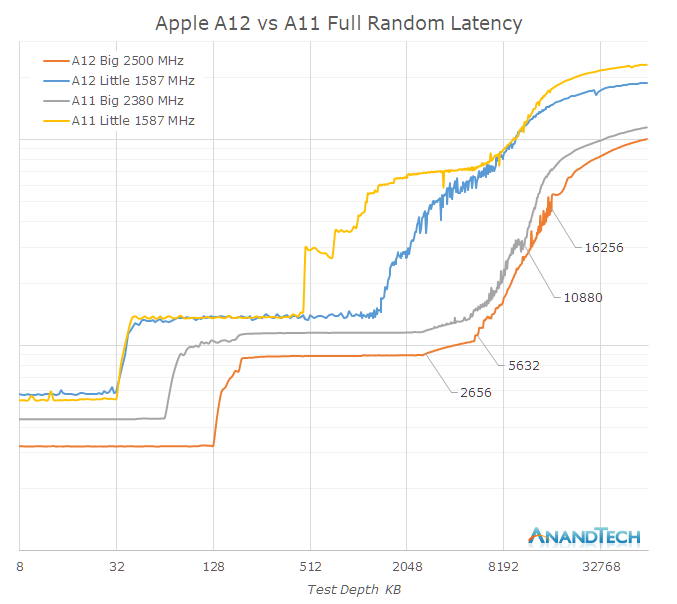
在隊列深度超過L2緩存的容量后,Monsoon核心的延遲曲線會進一步增加4MB左右,Vortex核心的曲線則會一直延續8MB,這便是二者的共享緩存容量范圍,再往后便進入了內存的領域。這與在芯片透視圖上實際看到的情況很相符,A12的共享緩存不僅分區數量加倍,容量也從4MB增加到了8MB。
而代號為“Tempest(暴風)”的小核心這邊情況則稍有些復雜,乍看之下可能會認為A11中代號為“Mistral(干冷的北風)”的小核心只有512KB L2緩存而A12則有1.5MB,但實際上這只是緩存電源管理策略造成的假象。通過延遲圖表可以看出,Mistral核心在768KB和1MB處存在明顯的波動,而Tempest核心的類似波動則發生在2MB處。
綜合以上數據,可以得出下表中的數據:

A12的大核心L2緩存結構相比A11沒有任何變化,兩者都有128個SRAM塊,每個SRAM塊大小為48KB。而A12的小核心L2緩存容量翻倍,意味著SRAM塊數從16個增加到了32個。
不過,蘋果在A11和A12上使用的緩存電源管理策略允許在數據粒度較小時只激活部分緩存電路,在A11上這個粒度應該是256KB,而在A12上這個粒度應該是512KB。這也讓我們更加有理由認為A11的小核心L2緩存容量是1MB,A12則是2MB,這也意味著每個SRAM塊大小為64KB。
然而再回過頭看大核心,雖然我們之前認為其容量為6MB,不過仔細觀察可以發現其曲線在8MB處有一些變化。曲線的變化預示著測試數據的尺寸正在接近緩存容量的邊界,這使我們猜測A11和A12的大核心實際上有8MB L2緩存。
總而言之,蘋果處理器的緩存方面毫不吝惜晶體管的使用,A12在這方面則更進一步,整顆SoC上的各級緩存超過了16MB,這樣不惜血本的規模真的足以讓高通三星等公司同時期的旗艦產品無比汗顏。
進擊的GPU
在GPU方面,業界普遍對A12有著很高的期望,不僅僅是在性能方面,同樣也在架構方面。
去年,Imagination發布了一份新聞稿,稱蘋果計劃在未來15~24個月內不再在新產品中使用其知識產權。
撇去Imagination股票價格的崩潰以及隨后賣身的命運不談,盡管蘋果確實聲稱A11的GPU為自主設計,但它看起來仍然像是從Imagination的Rogue架構衍生而來,依然是基于TBDR(Tile Base Deffered Rendering,Imagination的專利渲染技術),只不過A11 GPU一顆核心的規模就相當于A10的兩顆而已。

而A12代號為“G11P”的GPU仍然與A11的GPU有著非常明顯的相似之處,各個功能塊似乎都位于相同的位置并以類似的方式構造。蘋果表示A12 GPU***的進步是支持顯存壓縮,而這也就意味著蘋果此前使用的GPU都不支持顯存壓縮(喵喵喵???),以及顯存壓縮可以顯著提升GPU性能。
所謂顯存壓縮,指的是從GPU到顯存的透明幀緩沖區壓縮。PC端像NVIDIA和AMD這樣的廠商已經應用這一技術N多年了,即使在內存帶寬沒有增加的情況下,它也能提高GPU的性能。移動SoC的GPU也需要內存壓縮,這是因為移動SoC的帶寬相比桌面級GPU更加有限。
Arm的AFBC是移動領域最公開談論的顯存壓縮方案,高通和Imagination等其他廠商也都有自己的顯存壓縮技術。相比之下蘋果在A12上剛剛引入這一功能似乎太晚了,不過這也意味著A12將從中獲得效率和性能上的顯著提升。
Vortex核心:大規模內存改進
在談及Vortex核心之前,首先需要了解一下蘋果新SoC的頻率。在過去幾代中,蘋果一直在穩步提高其大核心的頻率,同時也提升了微架構的IPC。下表是A12和A11的頻率表:
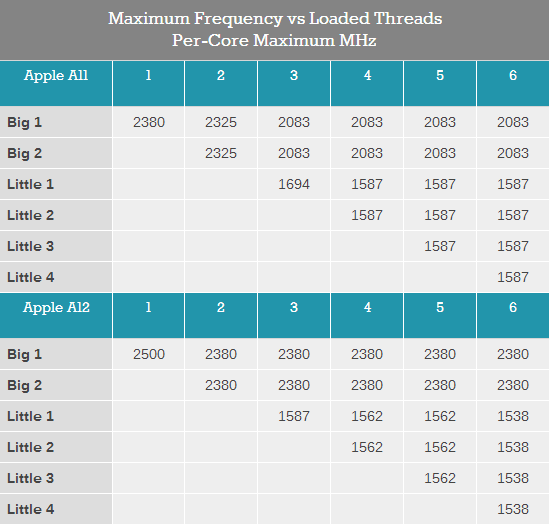
A11和A12在單大核心滿載時的***頻率分別為2380MHz和2500MHz;雙大核心滿載頻率分別為2325MHz和2380MHz。而在小核心加入工作后,A12的大核心頻率仍被設計為穩定在2380MHz,而A11則會進一步下調至2083MHz。
與愈發激進的大核心相比,A12的小核心部分則更顯保守。在只啟動一顆小核心時,A11的頻率為1694MHz,而A12則為1587MHz;啟動兩顆和三顆時A11為1587MHz,A12為1562MHz;而在四顆小核心滿載時,A11仍能保持在1587MHz,而A12則進一步降至1538MHz。
正如之前所提到的,蘋果在A12的緩存結構和內存子系統上投入了大量的工作。回到線性延遲圖上,我們看到以下針對大核和小核的完全隨機延遲的行為:
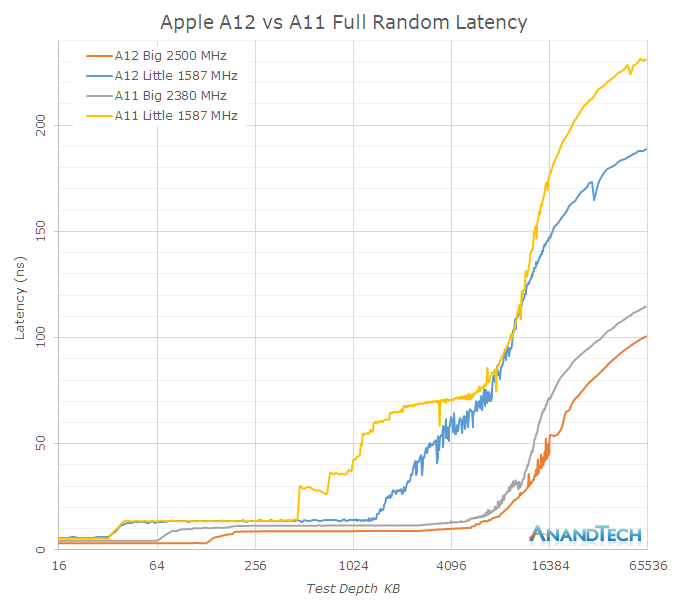
大核心方面,與A11的Monsoon核心相比,A12的Vortex核心僅有5%頻率提升,但L2緩存的絕對延遲從約11.5ns降至約8.8ns,降幅高達29%,這意味著Vortex核心的L2緩存可以在更短的時間內完成讀寫訪問。
小核心方面,A12的Tempest核心與A11的Mistral核心延遲表現相似,但A12在L2分區和電源管理方面又有了很大的變化,允許訪問更大的L2物理區塊。
這里只進行了64MB隊列深度的測試,顯然延遲曲線在這個數據集中并沒有變得平緩,但可以看出內存延遲已經有所改善。當小核心處于活動狀態時,內存控制器DVFS的***頻率會提高,這也是Tempest核心的內存訪問存在較大的差異的原因:當大核心上有高負載時,它們的性能會更好。
A12的共享緩存也發生了巨大的變化,雖然緩存帶寬相比A11有所降低,但訪問延遲得到了很大改善。
指令吞吐量和延遲
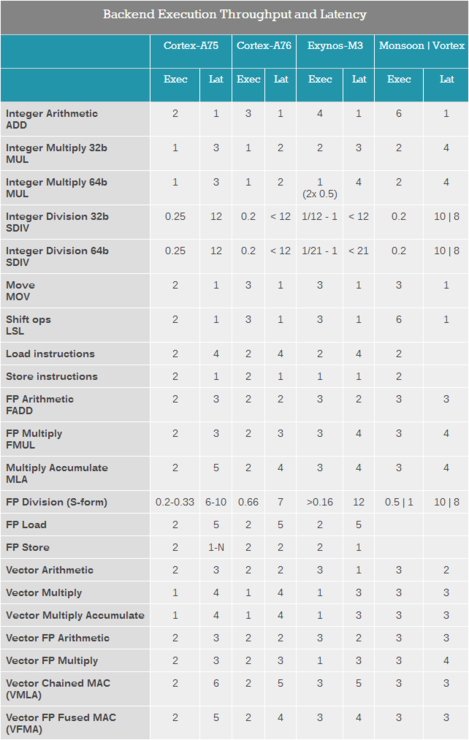
由于蘋果并沒有像Arm和三星一樣公布其架構設計,為了比較Vortex核心的后端特性,我們測試了A12的指令吞吐量,其中后端的性能由其執行單元的數量決定,延遲由其設計質量決定。
Vortex核心與Monsoon核心看起來非常相似,整數除法和浮點除法的執行延遲都減少了2個周期,浮點吞吐量則是翻了一倍。
從架構的中端和后端來看,Monsoon核心是一次重要的更新。此前A10處理器的大核心代號為“Hurricane(颶風)”,其解碼寬度為6,而Monsoon核心解碼寬度增加至7,同時后端的整數ALU單元也從4個增加到了6個。
Monsoon核心和Vortex核心均有6個整數執行單元(包括2個復雜單元)、2個加載/存儲單元、2個分支端口和3個浮點/矢量流水線,這樣寬裕的后端執行單元規模遠遠超過三星M3和Arm即將推出的Cortex A76。
事實上,如果沒有非典型的共享端口情況的話,完全可以說蘋果的微架構在后端單元方面遠遠超過其他任何處理器架構,包括桌面CPU。
CPU性能2倍于安卓旗艦
SPEC2006是一個重要的基準測試軟件,它與其他測試軟件的區別在于所處理的數據集更大更復雜。雖然GeekBench 4已經成為行業中的熱門,但它的測試項目較小,工作負載也較輕。因此使用SPEC2006作為基準測試更有代表性,它可以充分展示微架構的更多細節,特別是在內存子系統性能方面。
性能測試在一個散熱良好的環境中進行,可以保證在1~2小時內完整運行測試套件不會出現問題。
在左側軸上,條形圖表示給定工作負載下的電能消耗情況,越長的條形意味著消耗的電能越多。條形上的文字標注顯示的是消耗電能的具體數值(單位為焦),以及測試期間的平均功耗(單位為瓦)。

在大多數工作負載下,A12的大核心頻率比A11高5%,但實際上頻率并不是鎖死的,因而在SPECint2006中,A12的表現平均比A11好24%。
其中增幅最小的是456.hmmer和464.h264ref這兩項測試,這也是SPECint2006套件中成為瓶頸最多的測試。由于A12架構方面似乎沒有真正的重大變化,小幅增長主要歸功于更高的頻率以及緩存結構的改進。
而在445.gobmk測試項上A12的改進則非常大,相比A11增幅為27%。這項測試的負載特征是存儲地址事件中的瓶頸以及分支錯誤預測。
429.mcf、471.omnetpp、473.Astar、483.xalancbmk以及部分403.gcc測試項對內存子系統很敏感,A12在這幾項上取得了30%~42%不等的性能提升,顯然新的緩存結構和內存子系統在這方面取得了很大的成效。
在能耗比方面,A12相比A11平均提升了12%,但需要注意的是,這里的能耗比指的是***性能時的功耗降低了12%,而A12展示出性能相比A11提高了24%,兩個SoC的性能功耗曲線已經大不相同。
不過,盡管7nm制程可以降低能耗,但在性能提升幅度***的基準測試中,A12的功耗相比A11不降反升,平均功率從3.36瓦增加到了3.64瓦。也就是說,A12花在提升性能上的功耗,要比7nm制程降低的功耗更多一些。

接下來是SPECfp2006測試,由于XCode中沒有Fortran編譯器且它不是NDK的一部分,要讓它在Android上工作非常復雜,因此我們選擇C和C++基準測試。
SPECfp2006有更多的內存密集型測試,在7次測試中,只有444.namd、447.dealII和453.povray在內存子系統達不到標準時才會看到主要的性能回歸。這對A12很有利,其在SPECfp的平均性能增幅為28%,提升***的433.milc一項甚至提升了75%。同樣的分析適用于450.soplex,優秀的緩存結構和內存性能帶來了40%的性能提升。
而470.lbm是一項有趣的測試,它展示了蘋果的架構與Arm和Samsung比起來有哪些性能優勢。470.lbm的特點最代碼中有大量循環,要求架構中有更大的指令循環緩沖區來優化這樣的工作負載,在循環迭代中,核心將繞過decode階段并從緩沖區獲取指令。看起來蘋果的架構恰好有某種類似的機制,也有可能是蘋果處理器內核的矢量執行性能Lbm的熱循環大量使用SIMD,而高達3倍的執行吞吐量優勢最終產生了優秀的性能。
(高通的Kryo架構由于獨特的設計使驍龍820在這一項上的表現仍優于最近的安卓陣營處理器。)
與SPECint測試類似,A12在SPECfp測試中的能耗比有明顯提升,在所有測試中總能量比A11低10%。另一方面A12的功耗也有所增加,平均功耗從3.65瓦上升至4.27瓦,其中433.milc項目的功耗從2.7瓦增至4.2瓦,增加了75%;482.sphinx3項目的功耗則達到了A12所有SPEC測試項中的***值5.35瓦。
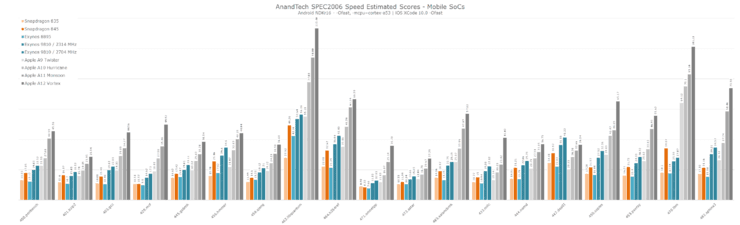
總體而言,蘋果在Vortex核心和內存子系統方面的改進,使A12的實際性能比宣傳中的還要強。與目前***的安卓陣營SoC相比,A12無論在性能上還是在能耗比上都有將近2倍的壓倒性優勢,而如果是在正常使用條件下A12的優勢可能還會更大。
這也讓我們對今年發布的三星M3 架構有了更好的認知,即只有當功耗在可控范圍內時,更高的功耗才能帶來更高的性能(Exynos 9810的功耗是蘋果上代A11的2倍,但其性能卻只有A11的一半)。
GPU能耗比1.8倍于驍龍845
GPU的性能提升是此次A12的***亮點之一,通過 “簡單的”將GPU從3核擴充為4核,以及引入顯存壓縮技術,蘋果表示A12的GPU性能相比A11提升了50%。
在進入基準測試之前必須要知道的是,在最近兩三年里,蘋果開始注重注重峰值性能而忽視長時間運行時的穩定性能,使用中常常出現過熱降頻導致性能下降。因此蘋果***GPU的峰值性能和峰值功耗是一個必須關注的大問題。
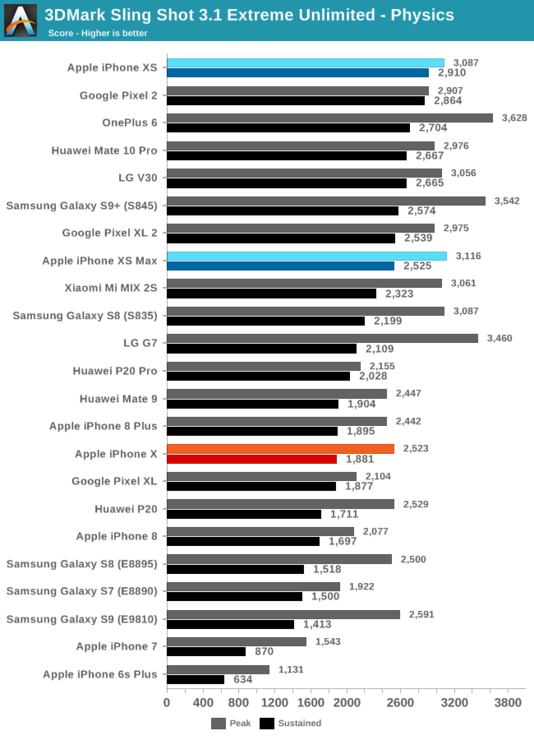
在3DMark物理測試中,iPhone XS和A12相比去年的iPhone X取得了很大的進步。3DMark物理測試此前一直對蘋果的處理器不夠友好,這個境遇在A11上才得到了一定的緩解。A12整體上再次提高了SoC的性能和能耗比,最終在本次測試中勝過了驍龍845。
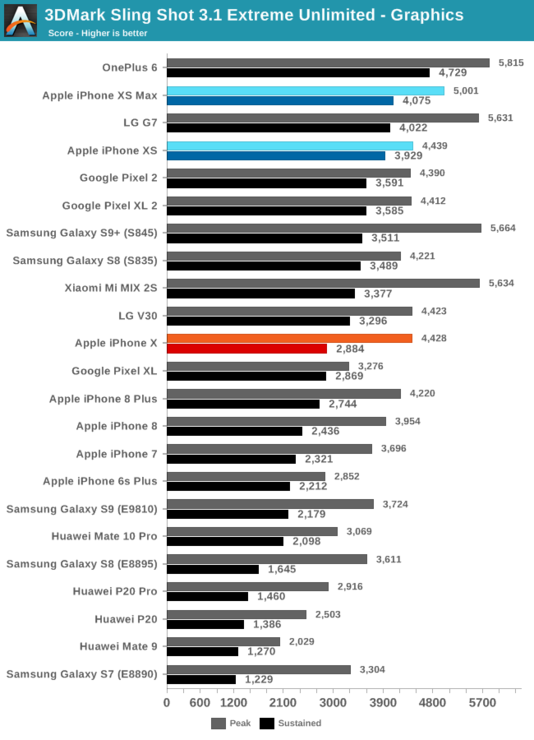
在3DMark測試的圖形部分,iPhone XS的持續性能比去年的iPhone X提高了41%,不過一加6更加奔放的功耗和溫度限制讓其性能仍然更勝一籌。
不過就性能峰值而言,iPhone XS在3DMark測試中遇到了大問題,如果測試時手機的溫度比較低,就會很快在測試中崩潰。監控顯示在低溫時處理器的頻率很高,平臺瞬時峰值功耗可達約7.5瓦,系統無法提供足夠的瞬態電流,會引起電壓下降,甚至損壞GPU。
除了3DMARK之外,Kishonti的GFXBench多年來一直是行業標準,新的Aztec測試給我們帶來了不同的工作量。不久前Kishonti發布了GFXBench的5.0版本,這個版本建立在新的渲染引擎上運行,并引入了High Tier和Normal Tier模式下的全新測試場景Aztec Ruins。新的測試更加考驗著色性能,利用更復雜的效果來強調GPU的算術能力。
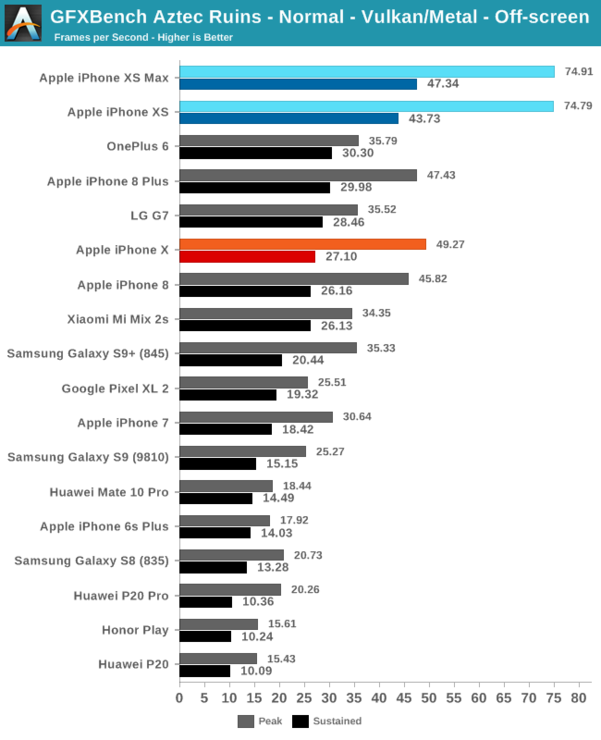
Normal Tier模式下的Aztec Ruins測試要求相對較低,iPhone XS的峰值性能相較于去年的iPhone X提升了51%,持續性能則提升了61%,相比一加6則提升了45%。而在High Tier模式下,iPhone XS的持續性能比iPhone X高出61%,比一加6則高出31%。
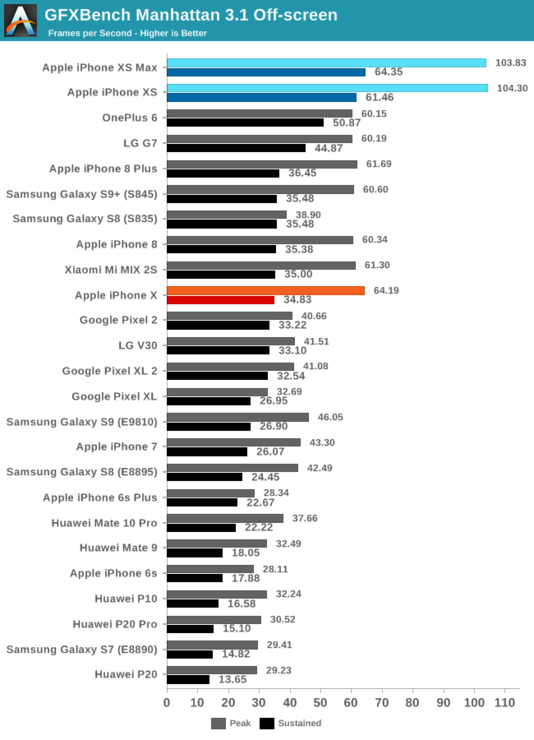
功耗方面,由于沒有時間在各種設備上測量Aztec,所以仍然依賴標準的曼哈頓3.1和T-Rex測試數據。
在曼哈頓3.1中, iPhone XS的性能比iPhone X高出75%。這里的改進不僅要歸功于增加的核心,還有顯存壓縮技術降低RAM功耗的功勞。
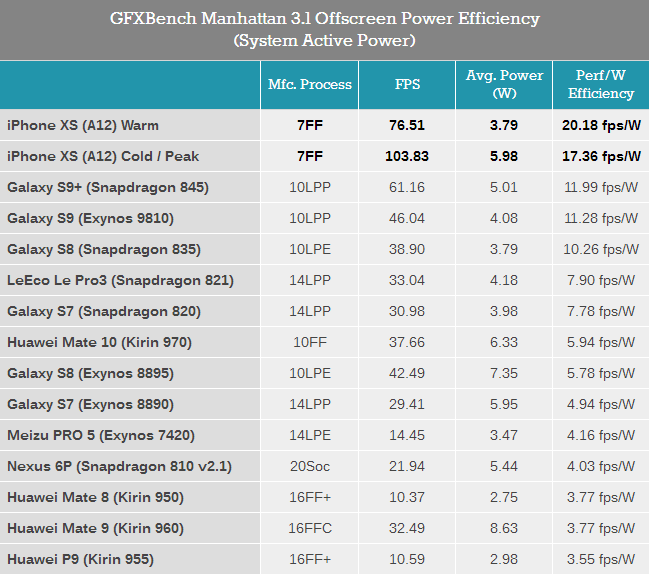
在環境溫度22°C時,A12測試曼哈頓3.1時的峰值功耗達到6瓦。但即使在這樣的峰值功耗下,A12的效率也超過了所有其他SoC,說明蘋果對功耗的控制是非常有效的。在運行測試3分鐘后功率回落至合理的3.79瓦,而此時處理器的能耗比僅相較峰值功耗時提升了16%,證明A12的能耗比曲線非常平坦,6瓦的峰值功耗仍在芯片本身的可控范圍之內,足見蘋果在芯片設計上的功力之強大。
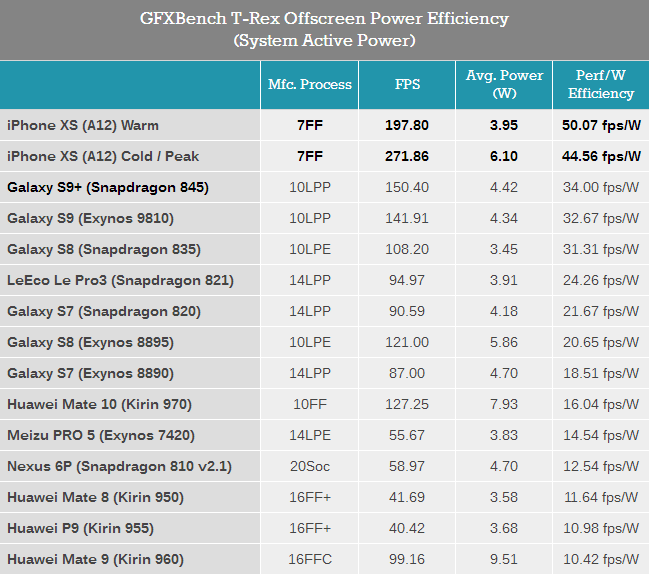
在T-Rex測試中,iPhone XS的持續性能相比iPhone X提升了61%,而功耗與曼哈頓3.1測試時表現相似,峰值功耗略高于6瓦,數分鐘后降至4W以下,能耗比同樣提升不大。
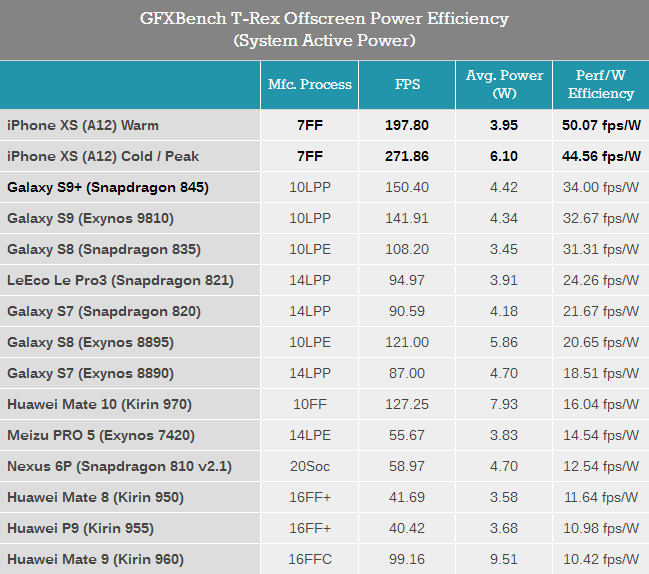
那么為什么近兩三年的蘋果處理器在峰值性能和持續性能之間存在如此大的差異呢?實際上這種變化是由于日常GPU應用場景的變化,以及蘋果將GPU用于非3D相關應用的加速需求。
蘋果對API棧的垂直集成和嚴格控制意味著GPU加速成為現實,而峰值性能是一個重要指標。蘋果大量將GPU用于各種其他用途,例如在應用程序中使用GPU進行相機圖像處理的硬件加速。這些應用場景均為事務性工作負載,需要較高的峰值性能以盡快處理完成。
相比之下,過去幾年里Android在GPU計算方面一直是一場災難,這主要怪沒有在AOSP中支持OpenCL——這使得供應商對OpenCL的支持非常不完善。RenderScript由于無法保證性能而從未獲得太多的關注,Android設備和SoC的碎片化意味著在第三方應用程序基本上無法使用GPU計算。
得益于新的A12處理器,iPhone XS和XS Max展示了業界領先的性能和效率,并且目前是***的游戲移動平臺。不過蘋果還是應該在手機的熱量分布上做一些功課,iPhone XS一如上代iPhone X一樣熱量分布過于集中,非常影響使用體驗。
本文轉自雷鋒網,如需轉載請至雷鋒網官網獲取授權。















