













數據科學家須知的19個機器學習算法
譯文
【51CTO.com快譯】機器學習算法介紹
在機器學習算法的領域,我們一般采用兩種方法來進行分類,它們是:
- 第一種是根據學習的方式,進行算法分類。
- 第二種是根據形式或功能的相似性,進行算法分類。
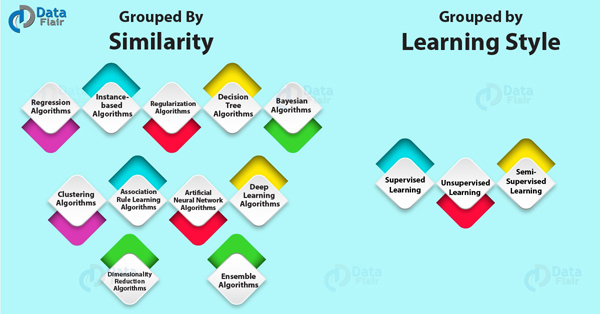
一般情況下,這兩大類不分伯仲。此次,我們主要探究的是根據相似度分類的算法、及其各種不同的類型。
按學習方式進行分類的機器學習算法
一般而言,同一種算法會根據不同的互動體驗,對一個問題采取不同的建模方式。而這并不會影響到我們對于輸入數據的調用。同時,一些算法會經常出現在時下流行的機器學習、和人工智能領域的教科書中。
因此,面對不同的應用場景,人們首先需要考慮的是一個算法所適用的學習方式。在下文中,我們將探討機器學習算法的幾個主要學習方式,以及不同算法所適用的問題場景與用例。通過綜合考慮各種輸入數據所扮演的“角色”、和模型準備的不同流程,您將會根據自己的問題選擇出最適合的一種算法,并最終得到最佳結果。
下面先讓我們來看看三種不同的學習方式:
監督學習
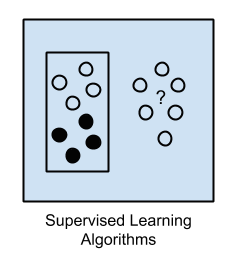
在監督式學習下,輸入數據被稱為“訓練數據”,它們都具有已知的標簽或結果,例如“垃圾郵件”、“非垃圾郵件”、或某個時刻的股票價格等。監督式學習通過一個訓練的過程,來建立一種預測模型。它們通過將預測結果與“訓練數據”的實際結果相比較,來不斷的修正預測結果。因此,該訓練過程會持續下去,直至模型達到了預期的水平。
- 常見應用場景包括:分類問題和回歸問題。
- 常見算法包括:邏輯回歸(Logistic Regression)和反向傳遞神經網絡(Back Propagation Neural Network)
無監督學習
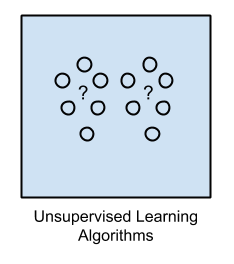
在非監督式學習中,輸入數據并不被標記,也沒有某個已知的結果。我們必須通過推導輸入數據的內在結構,來準備相應的模型。我們可以提取出一些通用的規則,同時也可以通過某個數學過程,來減少冗余。
- 常見的應用場景包括:聚類、降維、和關聯規則學習。
- 常見算法包括:先驗(Apriori)算法和K-均值(k-Means)算法。
半監督學習
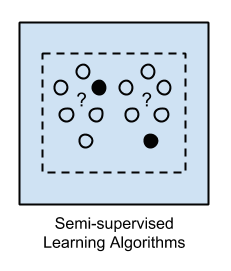
在半監督式學習中,輸入數據是被標記和未標記樣本的混合物。它同樣具有期望的預測目標。該模式必須通過學習不同的結構,來組織各種數據,從而做出預測。
- 常見應用場景包括:分類問題和回歸問題。
- 常見算法包括:一些針對其他靈活的監督式學習算法的延伸,這些算法試圖對未標識數據進行建模。
按相似性進行分類的算法
機器學習算法通常會按照功能的相似性進行分類,其中包括:基于(決策)樹的方法、和神經網絡的啟發方法。我個人認為這是對機器學習算法最有效、最實用的分類方法。當然,也有些算法會橫跨多個類別,例如:學習矢量量化(Learning Vector Quantization)。該算法是神經網絡方法和基于實例方法的結合,常被用來描述回歸與聚類的問題、以及算法的類型。此類算法的特點是不會重復地去調用相同的算法。
1.回歸算法
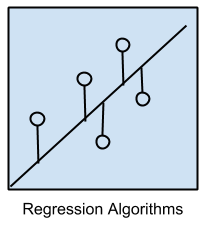
回歸算法關注的是對變量之間的關系進行建模。我們可以使用該模型,來對各種預測中產生的誤差指標予以改善。
這些方法都是統計學方面的“主力軍”,同時也是統計機器學習方面的“利器”。由于“回歸”既可以指問題的類型、也可以指算法的問題,因此在指代上比較容易混淆。最流行的回歸算法包括:
- 普通最小二乘回歸(Ordinary Least Square Regression,OLSR)
- 線性回歸(Linear Regression)
- 邏輯回歸(Logistic Regression)
- 逐步式回歸(Stepwise Regression)
- 多元自適應回歸樣條(Multivariate Adaptive Regression Splines,MARS)
- 本地散點平滑估計(Locally Estimated Scatterplot Smoothing,LOESS)
2.基于實例的算法
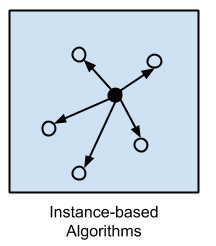
該模型使用各種實例的訓練數據,來處理決策問題。其方法是構建出一個樣本數據的數據庫。它通過將新數據與樣本數據進行比較,采用相似性的方法找到最佳的匹配、并進行預測。我們會存儲不同實例的表現狀態,并在實例之間使用相似性來進行衡量。因此,基于實例的算法也被稱為“贏家通吃的學習”或“基于記憶的學習”。最流行的基于實例的算法包括:
- k-近鄰(k-Nearest Neighbor,kNN)
- 學習矢量量化(Learning Vector Quantization,LVQ)
- 自組織映射(Self-Organizing Map,SOM)
- 局部加權學習(Locally Weighted Learning,LWL)
3.正則化算法
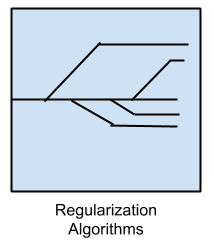
該方法是其他算法(通常指回歸算法)的延伸,它采用的“懲罰”模型與其復雜度有關,即:模型越是簡單、就越容易泛化(generalizing)。我將它在此單獨列舉出來的原因是:它不但廣受歡迎、功能強大,而且只是對其他方法進行了簡單修改。最流行的正則化算法包括:
- 嶺回歸(Ridge Regression)
- Least Absolute Shrinkage and Selection Operator,LASSO
- 彈性網絡(Elastic Net)
- 最小角度回歸(Least-Angle Regression,LARS)
4.決策樹算法
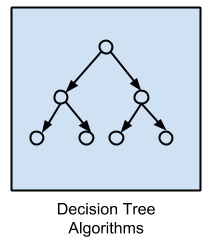
決策樹方法是基于數據屬性的實際值,來構建的決策模型。樹狀的結構會不斷分叉,直到根據給定的記錄作出了預測抉擇。決策樹會對分類和回歸問題的數據進行訓練。由于決策樹具有速度快、結果準的特性,因此它成為最受歡迎的機器學習算法之一。最流行的決策樹算法包括:
- 分類與回歸樹(Classification and Regression Tree,CART)
- Iterative Dichotomiser 3,ID3
- C4.5和C5.0
- 卡方自動交互檢測(Chi-squared Automatic Interaction Detection,CHAID)
- 決策樹樁(單層決策樹,Decision Stump)
- M5
- 條件決策樹(Conditional Decision Trees)
5.貝葉斯算法
此類算法適用于那些貝葉斯定理的問題,例如分類與回歸。最流行的貝葉斯算法包括:
- 樸素貝葉斯(Naive Bayes)
- 高斯樸素貝葉斯(Gaussian Naive Bayes)
- 多項式樸素貝葉斯(Multinomial Naive Bayes)
- Averaged One-Dependence Estimators,AODE
- 貝葉斯信念網絡(Bayesian Belief Network,BBN)
- 貝葉斯網絡(Bayesian Network,BN)
6.聚類算法
聚類跟回歸一樣,既可以用來描述問題的類型,又可以指代方法的類型。此方法采用基于中心點(centroid-based)或分層級(hierarchal)等建模方法,而所有的方法都與數據固有的結構的使用有關。其目標是將數據按照它們之間的最大共性進行分組。最流行的聚類算法包括:
- K-均值(k-Means)
- K-中位數(k-Medians)
- 期望最大化(Expectation Maximisation,EM)
- 分層聚類(Hierarchical Clustering)
7.關聯規則學習算法
關聯規則的學習方法旨在提取各種規則,即:通過觀察,最好地描述出數據變量之間的關系。這些規則能夠從大型多維數據集里,發現可以被組織所利用到的重要的、且實用的各種關聯。最流行的關聯規則學習算法包括:
- 先驗算法(Apriori algorithm)
- Eclat算法
8.人工神經網絡算法
該算法是由生物神經網絡結構所啟發的模型。它們是一類用于解決回歸和分類等問題的模式匹配。由于它結合了數以百計的算法和變量,因此它會包含一個極其龐大的子集。最流行的人工神經網絡算法包括:
- 感知(Perceptron)
- 反向傳播(Back-Propagation)
- Hopfield網絡
- 徑向基函數網絡(Radial Basis Function Network,RBFN)
9.深度學習算法
深度學習算法是人工神經網絡的升級版,它充分利用了廉價的計算力。它們涉及到搭建規模更為龐大、結構更為復雜的神經網絡。最流行的深度學習算法包括:
- 深度玻爾茲曼機(Deep Boltzmann Machine,DBM)
- 深度信念網絡(Deep Belief Networks,DBN)
- 卷積神經網絡(Convolutional Neural Network,CNN)
- 棧式自動編碼器(Stacked Auto-Encoder)
10.降維算法
與聚類方法類似,降維算法尋找數據中的固有結構。一般情況下,它對于可視化的三維數據比較實用。我們可以在監督學習方法中使用它,以實現分類和回歸。最流行的降維算法包括:
- 主成分分析(Principal Component Analysis,PCA)
- 主成分回歸(Principal Component Regression,PCR)
- 偏最小二乘回歸(Partial Least Squares Regression,PLSR)
- Sammon Mapping
- 多維尺度(Multidimensional Scaling,MDS)
- 投影尋蹤(Projection Pursuit)
- 線性判別分析(Linear Discriminant Analysis,LDA)
- 混合判別分析(Mixture Discriminant Analysis,MDA)
- 二次判別分析(Quadratic Discriminant Analysis,QDA)
- 靈活判別分析(Flexible Discriminant Analysis,FDA)
11.模型融合算法
該算法是由多個經過訓練的弱模型所組成。它將單獨的預測以某種方式整合成為一個更好的。可見,模型融合算法是一類非常強大、且備受歡迎的技術。最流行的模型融合算法包括:
- Boosting
- Bootstrapped Aggregation (Bagging)
- AdaBoost
- 堆疊泛化(混合)Stacked Generalization (blending)
- Gradient Boosting Machines (GBM)
- Gradient Boosted Regression Trees (GBRT)
- 隨機森林(Random Forest)
常見的機器學習算法一覽

1.樸素貝葉斯分類器算法
一般情況下,我們很難對某個網頁、文檔、或電子郵件進行準確的分類,特別是那些含有冗長的文字信息、且需要手動分揀的內容。而這恰好是樸素貝葉斯分類器算法的用武之地。而且,其分類器具有為某個元素分配相似度值的功能。
例如,垃圾郵件過濾就是樸素貝葉斯算法的一個普遍的應用。此處的垃圾郵件過濾器就充當了分類器的作用,給所有的郵件分配“垃圾郵件”或“非垃圾郵件”的標簽。大體說來,它是相似度類型機器學習算法中最為流行的一種。其工作基本原理就是基于貝葉斯定理,對各種單詞予以簡單分類,實現對內容的主觀分析。
2.K-均值聚類算法
K-均值是一種使用無監督機器學習的聚類分析算法。同時,它屬于一種非確定性的迭代方法。該算法對于給定數據集里的預設數量類別(如k)進行操作。因此,K-均值算法的輸出是在聚類中,從輸入數據分離出的k個劃分簇。
3.支持向量機算法
該算法是一種使用監督機器學習的算法,可用于分類和回歸分析。SVM(支持向量機,https://data-flair.training/blogs/svm-support-vector-machine-tutorial/)能夠對任何新的數據集進行分類。其工作原理是:通過將訓練數據集分成不同的類別,以發現某個線性特征,并由多個線性構造出一些超平面。因此,SVM需要最大化各種類別之間的距離,即:標識出邊緣的最大化,以增加看不見數據的概率。SVM一般分為兩類:
- 線性SVM – 通過某個超平面,將訓練數據線性分隔出類別。
- 非線性SVM – 無法通過某個超平面,對訓練數據進行分隔。
4.先驗算法
該算法是一種無監督式的機器學習算法。我們使用它從給定的數據集中產生關聯規則。這里的關聯規則是指:“如果A項發生,則B項也會發生”的一定概率,通常以IF_THEN的形式產生。
例如:如果某人買了一個iPad,那么他也會去購買一個iPad外殼來保護它。因此,該算法的基本工作原理是:如果某項經常發生,那么該項的所有子集也會頻繁發生。反之,如果某項只是偶爾發生,那么其所有超集也極少會發生。
5.線性回歸算法
該算法能夠通過兩個變量之間的關系,展示一個變量(自變量)是如何影響另一個變量(因變量)的,即它們之間的依賴關系。縱然自變量不斷變化,因變量卻時常有相似的預測因子。
6.決策樹算法
我們通常用一個圖形來表示決策樹,即:通過使用分支的方法,來說明某個決策的所有可能結果。在決策樹中,每一個分支節點都代表對于某個屬性的測試性結果。同時,葉子節點則代表特定類別的標簽,即:計算了所有屬性之后,所作出的決策。此外,我們可通過從根到葉子節點的路徑來表示某一種分類。
7.隨機森林算法
這是轉向(go-to)類型的機器學習算法。我們使用一種bagging的方法,來創建一組帶有數據的隨機子集的決策樹。我們需要通過隨機森林算法,針對某個模型數據集上的隨機樣本進行多次訓練,綜合所有決策樹的輸出結果,并對每一個決策樹的結果進行輪詢投票(polling),以實現良好的最終預測效果。
8.邏輯回歸算法
此類算法屬于一種廣義的線性回歸,它將邏輯函數應用到了某些特征的線性組合之中,通過各種預測變量,來預測出已分類的因變量結果,同時也描述出自變量的權重概率。
結論
綜上所述,我們討論了機器學習算法、及其不同的分類,其中包括:回歸算法、基于實例的算法、正則化算法、決策樹算法、貝葉斯算法、聚類算法、關聯規則學習算法、人工神經網絡算法、深度學習算法、降維算法、模型融合算法、監督學習、無監督學習、半監督學習、樸素貝葉斯分類器算法、K-均值聚類算法、支持向量機算法、先驗算法、線性回歸和邏輯回歸。相信我們上述圖文并茂的講解方式一定能讓您有所收獲。
原文標題:Top Machine Learning Algorithms You Should Know to Become a Data Scientist ,作者:Rinu Gour
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】
















