Apache Flink靠什么征服阿里工程師?
伴隨著海量增長的數據,數字化時代的未來感撲面而至。不論是結繩記事的小數據時代,還是我們正在經歷的大數據時代,計算的邊界正在被***拓寬,而數據的價值再也難以被計算。
時下,談及大數據,不得不提到熱門的下一代大數據計算引擎 Apache Flink(以下簡稱 Flink)。
本文將結合 Flink 的前世今生,從業務角度出發,向大家娓娓道來:為什么阿里選擇了 Flink?
為什么阿里選擇了 Flink
隨著人工智能時代的降臨,數據量的爆發,在典型的大數據的業務場景下數據業務最通用的做法是:選用批處理的技術處理全量數據,采用流式計算處理實時增量數據。
在絕大多數的業務場景之下,用戶的業務邏輯在批處理和流處理之中往往是相同的。
但是,用戶用于批處理和流處理的兩套計算引擎是不同的。因此,用戶通常需要寫兩套代碼。毫無疑問,這帶來了一些額外的負擔和成本。
阿里巴巴的商品數據處理就經常需要面對增量和全量兩套不同的業務流程問題,所以阿里就在想,我們能不能有一套統一的大數據引擎技術,用戶只需要根據自己的業務邏輯開發一套代碼。
這樣在各種不同的場景下,不管是全量數據還是增量數據,亦或者實時處理,一套方案即可全部支持,這就是阿里選擇 Flink 的背景和初衷。
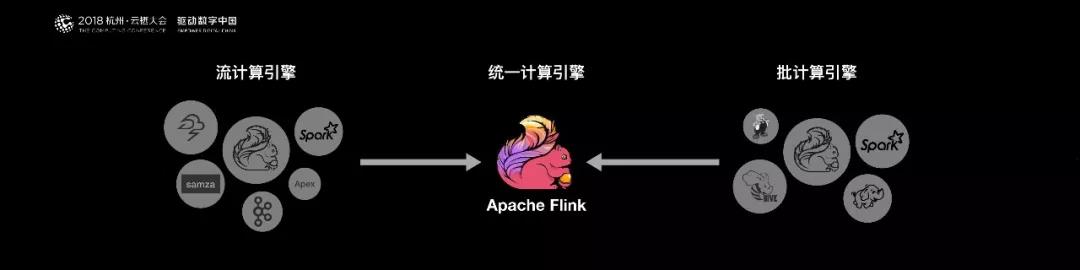
目前開源大數據計算引擎有很多選擇,流計算如 Storm、Samza、Flink、Kafka Stream 等,批處理如 Spark、Hive、Pig、Flink 等。
而同時支持流處理和批處理的計算引擎,只有兩種選擇:
- Apache Spark。
- Apache Flink。
從技術,生態等各方面的綜合考慮。首先,Spark 的技術理念是基于批來模擬流的計算。而 Flink 則完全相反,它采用的是基于流計算來模擬批計算。
從技術發展方向看,用批來模擬流有一定的技術局限性,并且這個局限性可能很難突破。
而 Flink 基于流來模擬批計算,在技術上有更好的擴展性。從長遠來看,阿里決定用 Flink 做一個統一的、通用的大數據引擎作為未來的選型。
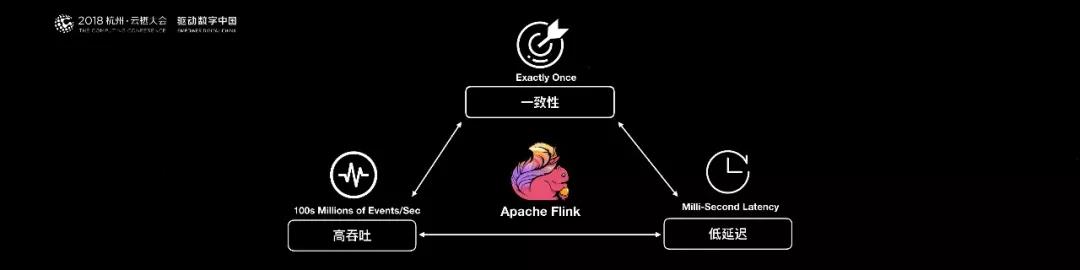
Flink 是一個低延遲、高吞吐、統一的大數據計算引擎。在阿里巴巴的生產環境中,Flink 的計算平臺可以實現毫秒級的延遲情況下,每秒鐘處理上億次的消息或者事件。
同時 Flink 提供了一個 Exactly-once 的一致性語義,保證了數據的正確性。這樣就使得 Flink 大數據引擎可以提供金融級的數據處理能力。
Flink 在阿里的現狀
基于 Apache Flink 在阿里巴巴搭建的平臺于 2016 年正式上線,并從阿里巴巴的搜索和推薦這兩大場景開始實現。
目前阿里巴巴所有的業務,包括阿里巴巴所有子公司都采用了基于 Flink 搭建的實時計算平臺。同時 Flink 計算平臺運行在開源的 Hadoop 集群之上。
采用 Hadoop 的 YARN 做為資源管理調度,以 HDFS 作為數據存儲。因此,Flink 可以和開源大數據軟件 Hadoop 無縫對接。
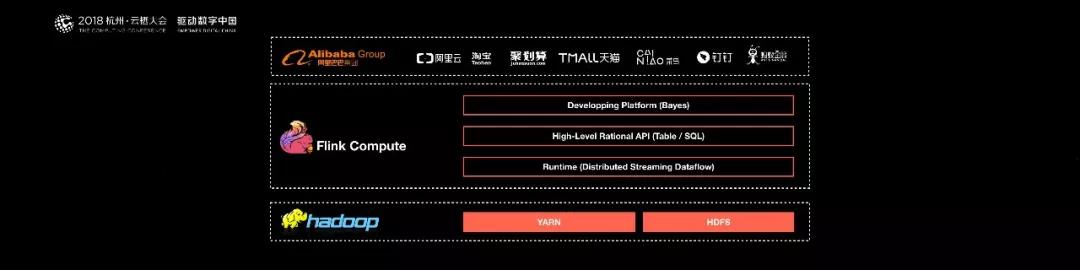
目前,這套基于 Flink 搭建的實時計算平臺不僅服務于阿里巴巴集團內部,而且通過阿里云的云產品 API 向整個開發者生態提供基于 Flink 的云產品支持。

Flink 在阿里巴巴的大規模應用,表現如何?具體如下:
- 規模:一個系統是否成熟,規模是重要指標。Flink 最初上線時,阿里巴巴只有數百臺服務器,目前規模已達上萬臺,此等規模在全球范圍內也是***。
- 狀態數據:基于 Flink,內部積累起來的狀態數據已經是 PB 級別規模。
- Events:如今每天在 Flink 的計算平臺上,處理的數據已經超過萬億條。
PS:在峰值期間可以承擔每秒超過 4.72 億次的訪問,最典型的應用場景是阿里巴巴雙 11 大屏。
Flink 的發展之路
接下來從開源技術的角度,來談一談 Apache Flink 是如何誕生的,它是如何成長的?以及在成長的這個關鍵的時間點阿里是如何進入的?并對它做出了那些貢獻和支持?
Flink 誕生于歐洲的一個大數據研究項目 StratoSphere。該項目是柏林工業大學的一個研究性項目。
早期,Flink 是做 Batch 計算的,但是在 2014 年,StratoSphere 里面的核心成員孵化出 Flink,同年將 Flink 捐贈 Apache,并在后來成為 Apache 的***大數據項目。
同時 Flink 計算的主流方向被定位為 Streaming,即用流式計算來做所有大數據的計算,這就是 Flink 技術誕生的背景。

2014 年 Flink 作為主攻流計算的大數據引擎開始在開源大數據行業內嶄露頭角。
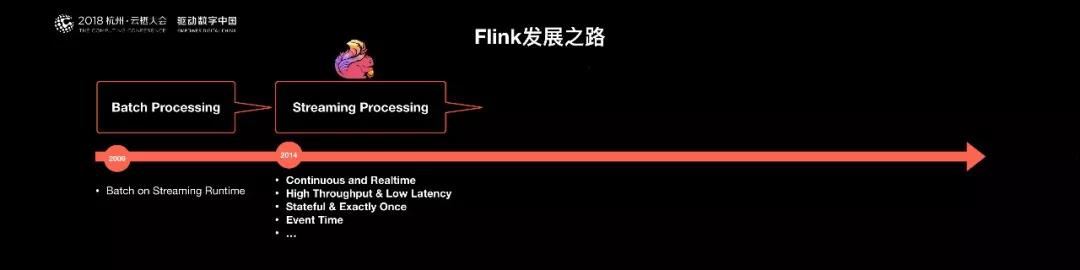
區別于 Storm,Spark Streaming 以及其他流式計算引擎的是:它不僅是一個高吞吐、低延遲的計算引擎,同時還提供很多高級的功能。
比如它提供了有狀態的計算,支持狀態管理,支持強一致性的數據語義以及支持 Event Time,WaterMark 對消息亂序的處理。
Flink 核心概念以及基本理念
Flink 最區別于其他流計算引擎的,其實就是狀態管理。什么是狀態?
例如開發一套流計算的系統或者任務做數據處理,可能經常要對數據進行統計,如 Sum、Count、Min、Max 這些值是需要存儲的。
因為要不斷更新,這些值或者變量就可以理解為一種狀態。如果數據源是在讀取 Kafka,RocketMQ,可能要記錄讀取到什么位置,并記錄 Offset,這些 Offset 變量都是要計算的狀態。
Flink 提供了內置的狀態管理,可以把這些狀態存儲在 Flink 內部,而不需要把它存儲在外部系統。
這樣做有兩大好處:
- 降低了計算引擎對外部系統的依賴以及部署,使運維更加簡單。
- 對性能帶來了極大的提升:如果通過外部去訪問,如 Redis、HBase 它一定是通過網絡及 RPC。如果通過 Flink 內部去訪問,它只通過自身的進程去訪問這些變量。
同時 Flink 會定期將這些狀態做 Checkpoint 持久化,把 Checkpoint 存儲到一個分布式的持久化系統中,比如 HDFS。
這樣的話,當 Flink 的任務出現任何故障時,它都會從最近的一次 Checkpoint 將整個流的狀態進行恢復,然后繼續運行它的流處理。對用戶沒有任何數據上的影響。
Flink 是如何做到在 Checkpoint 恢復過程中沒有任何數據的丟失和數據的冗余?來保證精準計算的?
這其中原因是 Flink 利用了一套非常經典的 Chandy-Lamport 算法,它的核心思想是把這個流計算看成一個流式的拓撲,定期從這個拓撲的頭部 Source 點開始插入特殊的 Barries,從上游開始不斷的向下游廣播這個 Barries。
每一個節點收到所有的 Barries,會將 State 做一次 Snapshot,當每個節點都做完 Snapshot 之后,整個拓撲就算完整的做完了一次 Checkpoint。接下來不管出現任何故障,都會從最近的 Checkpoint 進行恢復。
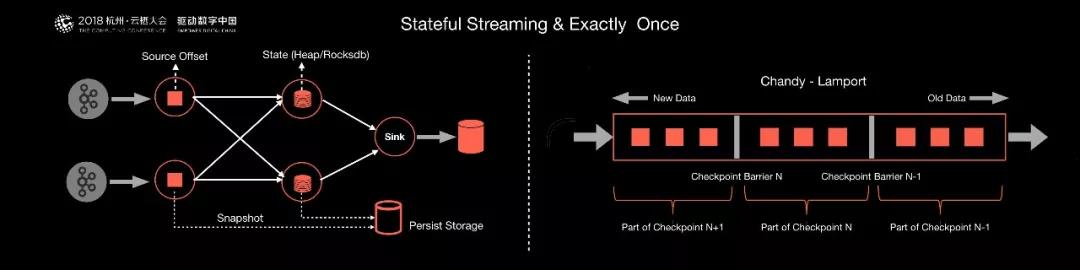
Flink 利用這套經典的算法,保證了強一致性的語義。這也是 Flink 與其他無狀態流計算引擎的核心區別。
下面介紹 Flink 是如何解決亂序問題的。比如星球大戰的播放順序,如果按照上映的時間觀看,可能會發現故事在跳躍。
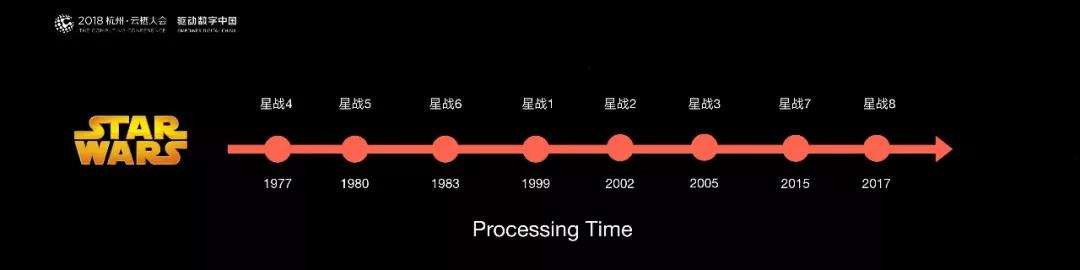
在流計算中,與這個例子是非常類似的。所有消息到來的時間,和它真正發生在源頭,在線系統 Log 當中的時間是不一致的。
在流處理當中,希望是按消息真正發生在源頭的順序進行處理,不希望是真正到達程序里的時間來處理。
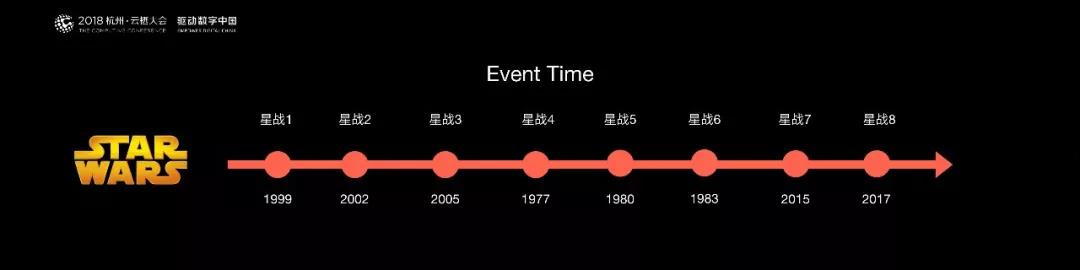
Flink 提供了 Event Time 和 Water Mark 的一些先進技術來解決亂序的問題,使得用戶可以有序的處理這個消息。這是 Flink 一個很重要的特點。
接下來要介紹的是 Flink 啟動時的核心理念和核心概念,這是 Flink 發展的***個階段;第二個階段時間是 2015 年和 2017 年,這個階段也是 Flink 發展以及阿里巴巴介入的時間。
故事源于 2015 年年中,我們在搜索事業部的一次調研。當時阿里有自己的批處理技術和流計算技術,有自研的,也有開源的。
但是,為了思考下一代大數據引擎的方向以及未來趨勢,我們做了很多新技術的調研。
結合大量調研結果,我們***得出的結論是:解決通用大數據計算需求,批流融合的計算引擎,才是大數據技術的發展方向,并且最終我們選擇了 Flink。
但 2015 年的 Flink 還不夠成熟,不管是規模還是穩定性尚未經歷實踐。***我們決定在阿里內部建立一個 Flink 分支,對 Flink 做大量的修改和完善,讓其適應阿里巴巴這種超大規模的業務場景。
在這個過程當中,我們團隊不僅對 Flink 在性能和穩定性上做出了很多改進和優化,同時在核心架構和功能上也進行了大量創新和改進,并將其貢獻給社區。
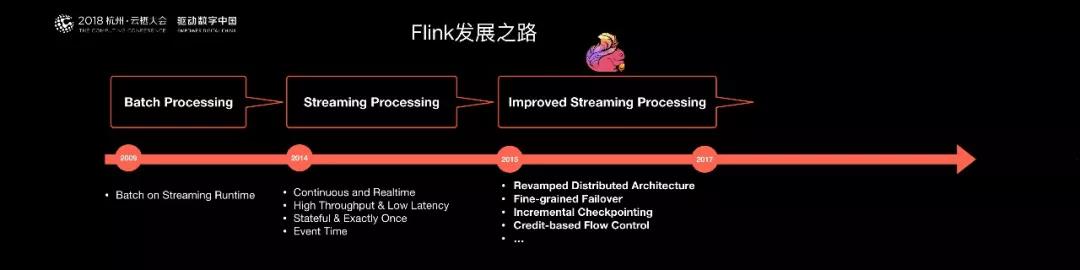
例如:Flink 新的分布式架構,增量 Checkpoint 機制,基于 Credit-based 的網絡流控機制和 Streaming SQL 等。
阿里巴巴對 Flink 社區的貢獻
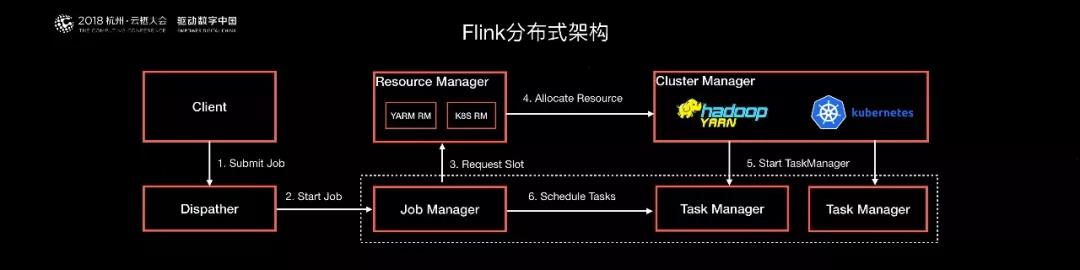
我們舉兩個設計案例,***個是阿里巴巴重構了 Flink 的分布式架構,將 Flink 的 Job 調度和資源管理做了一個清晰的分層和解耦。這樣做的首要好處是 Flink 可以原生的跑在各種不同的開源資源管理器上。
經過這套分布式架構的改進,Flink 可以原生地跑在 Hadoop Yarn 和 Kubernetes 這兩個最常見的資源管理系統之上。
同時將 Flink 的任務調度從集中式調度改為了分布式調度,這樣 Flink 就可以支持更大規模的集群,以及得到更好的資源隔離。
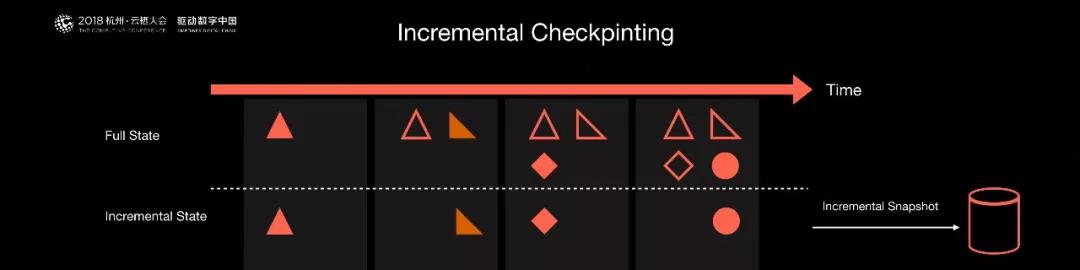
另一個是實現了增量的 Checkpoint 機制,因為 Flink 提供了有狀態的計算和定期的 Checkpoint 機制,如果內部的數據越來越多,不停地做 Checkpoint,Checkpoint 會越來越大,***可能導致做不出來。
提供了增量的 Checkpoint 后,Flink 會自動地發現哪些數據是增量變化,哪些數據是被修改了。同時只將這些修改的數據進行持久化。
這樣 Checkpoint 不會隨著時間的運行而越來越難做,整個系統的性能會非常地平穩,這也是我們貢獻給社區的一個很重大的特性。
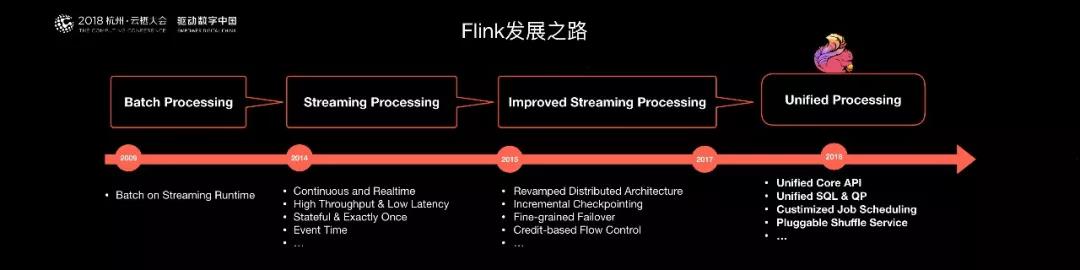
經過 2015 年到 2017 年對 Flink Streaming 的能力完善,Flink 社區也逐漸成熟起來。
Flink 也成為在 Streaming 領域最主流的計算引擎。因為 Flink 最早期想做一個流批統一的大數據引擎,2018 年已經啟動這項工作。
為了實現這個目標,阿里巴巴提出了新的統一 API 架構,統一 SQL 解決方案,同時流計算的各種功能得到完善后,我們認為批計算也需要各種各樣的完善。
無論在任務調度層,還是在數據 Shuffle 層,在容錯性,易用性上,都需要完善很多工作。
下面主要和大家分享兩點:
- 統一 API Stack
- 統一 SQL 方案
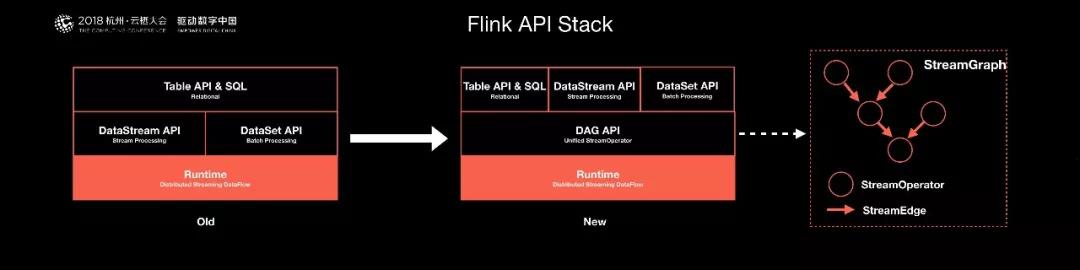
先來看下目前 Flink API Stack 的一個現狀,調研過 Flink 或者使用過 Flink 的開發者應該知道。Flink 有 2 套基礎的 API,一套是 DataStream,一套是 DataSet。
DataStream API 是針對流式處理的用戶提供,DataSet API 是針對批處理用戶提供,但是這兩套 API 的執行路徑是完全不一樣的,甚至需要生成不同的 Task 去執行。
所以這跟得到統一的 API 是有沖突的,而且這個也是不完善的,不是最終的解法。
在 Runtime 之上首先是要有一個批流統一融合的基礎 API 層,我們希望可以統一 API 層。
因此,我們在新架構中將采用一個 DAG(有限無環圖)API,作為一個批流統一的 API 層。
對于這個有限無環圖,批計算和流計算不需要涇渭分明的表達出來。只需要讓開發者在不同的節點,不同的邊上定義不同的屬性,來規劃數據是流屬性還是批屬性。
整個拓撲是可以融合批流統一的語義表達,整個計算無需區分是流計算還是批計算,只需要表達自己的需求。有了這套 API 后,Flink 的 API Stack 將得到統一。
除了統一的基礎 API 層和統一的 API Stack 外,同樣在上層統一 SQL 的解決方案。
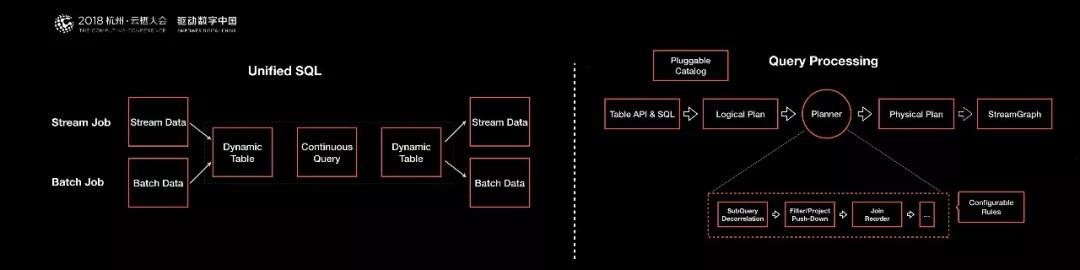
流和批的 SQL,可以認為流計算有數據源,批計算也有數據源,我們可以將這兩種源都模擬成數據表。
可以認為流數據的數據源是一張不斷更新的數據表,對于批處理的數據源可以認為是一張相對靜止的表,沒有更新的數據表。
整個數據處理可以當做 SQL 的一個 Query,最終產生的結果也可以模擬成一個結果表。
對于流計算而言,它的結果表是一張不斷更新的結果表。對于批處理而言,它的結果表是相當于一次更新完成的結果表。
從整個 SOL 語義上表達,流和批是可以統一的。此外,不管是流式 SQL,還是批處理 SQL,都可以用同一個 Query 來表達復用。
這樣以來流批都可以用同一個 Query 優化或者解析。甚至很多流和批的算子都是可以復用的。
Flink 的未來方向

首先,阿里巴巴還是要立足于 Flink 的本質,去做一個全能的統一大數據計算引擎。將它在生態和場景上進行落地。
目前 Flink 已經是一個主流的流計算引擎,很多互聯網公司已經達成了共識:Flink 是大數據的未來,是***的流計算引擎。
下一步很重要的工作是讓 Flink 在批計算上有所突破。在更多的場景下落地,成為一種主流的批計算引擎。
然后進一步在流和批之間進行無縫的切換,流和批的界限越來越模糊。用 Flink,在一個計算中,既可以有流計算,又可以有批計算。
第二個方向就是 Flink 的生態上有更多語言的支持,不僅僅是 Java,Scala 語言,甚至是機器學習下用的 Python,Go 語言。
未來我們希望能用更多豐富的語言來開發 Flink 計算的任務,來描述計算邏輯,并和更多的生態進行對接。
***不得不說 AI,因為現在很多大數據計算的需求和數據量都是在支持很火爆的 AI 場景。
所以在 Flink 流批生態完善的基礎上,將繼續往上走,完善上層 Flink 的 Machine Learning 算法庫,同時 Flink 往上層也會向成熟的機器學習,深度學習去集成。
比如可以做 Tensorflow On Flink,讓大數據的 ETL 數據處理和機器學習的 Feature 計算和特征計算,訓練的計算等進行集成,讓開發者能夠同時享受到多種生態給大家帶來的好處。