99%的人都能看懂的“熔斷”以及最佳實踐
當我們工作所在的系統處于分布式系統初期,往往這時候每個服務都只部署了一個節點。
在這樣的背景下,如果某個服務 A 需要發布一個新版本,往往會對正在運行的其他依賴服務 A 的程序產生影響。
甚至,一旦服務 A 的啟動預熱過程耗時過長,問題會更嚴重,大量請求會阻塞,產生級聯影響,導致整個系統卡慢。
舉個夸張的例子來形容:一幢樓的下水管是從最高樓直通到最低樓的,這個時候如果你家樓下的管道口堵住了,那么所有樓上的污水就會倒灌到你家;如果這導致你家的管道口也堵住了,之后又會倒灌到樓上一層,以此類推。
然而實際生活中一旦你發現了這個問題,必然會想辦法先避免影響到自己家,然后跑到樓下讓他們趕緊疏通管道。此時,避免影響自己家的辦法就可被稱之為「熔斷」。
熔斷是什么
熔斷本質上是一個過載保護機制。這一概念來源于電子工程中的斷路器,可能你曾經被這個東西的“跳閘”保護過。
在互聯網系統中的熔斷機制是指:當下游服務因訪問壓力過大而響應變慢或失敗,上游服務為了保護自己以及系統整體的可用性,可以暫時切斷對下游服務的調用。
做熔斷的思路大體上就是:一個中心思想,分四步走。
熔斷怎么做
熔斷怎么做?首先,你需秉持的一個中心思想是:量力而行。因為軟件和人不同,沒有奇跡會發生,什么樣的性能支撐多少流量是固定的,這是根本。
然后,這四步走分別是:
- 定義一個識別是否處于“不可用”狀態的策略
- 切斷聯系
- 定義一個識別是否處于“可用”狀態的策略,并嘗試探測
- 重新恢復正常
定義一個識別是否處于“不正常”狀態的策略
相信軟件開發經驗豐富的你也知道,識別一個系統是否正常,無非是兩個點:
- 是不是能調通。
- 如果能調通,耗時是不是超過預期時長。
但是,由于分布式系統被建立在一個并不是 100% 可靠的網絡上,所以上述的情況總有發生,因此我們不能將偶發的瞬時異常等同于系統“不可用”(避免以偏概全)。
由此我們需要引入一個「時間窗口」的概念,這個時間窗口用來“放寬”判定“不可用”的區間,也意味著多給了系統幾次證明自己“可用”機會。
但是,如果系統還是在這個時間窗口內達到了你定義“不可用”標準,那么我們就要“斷臂求生”了。
這個標準可以有兩種方式來指定:
- 閾值。比如,在 10 秒內出現 100 次“無法連接”或者出現 100 次大于 5 秒的請求。
- 百分比。比如,在 10 秒內有 30% 請求“無法連接”或者 30% 的請求大于5秒。
最終會形成這樣的一段代碼:
- 全局變量 errorcount = 0; //有個獨立的線程每隔10秒(時間窗口)重置為0。
- 全局變量 isOpenCircuitBreaker = false;
- //do some thing...
- if(success){
- return success;
- }
- else{
- errorcount++;
- if(errorcount == 不可用閾值){
- isOpenCircuitBreaker = true;
- }
- }
切斷聯系
切斷聯系要盡可能的“果斷”,既然已經認定了對方“不可用”,那么索性就默認“失敗”,避免做無用功,也順帶能緩解對方的壓力。
分布式系統中的程序間調用,一般都會通過一些 RPC 框架進行。
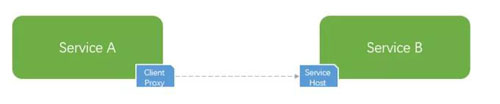
那么,這個時候作為客戶端一方,在自己進程內通過代理發起調用之前就可以直接返回失敗,不走網絡。
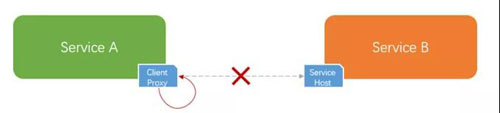
這就是常說的「fail fast」機制。就是在前面提到的代碼段之前增加下面的這段代碼:
- if(isOpenCircuitBreaker == true){
- return fail;
- }
- //do some thing...
定義一個識別是否處于“可用”狀態的策略,并嘗試探測
切斷聯系后,功能的完整性必然會受影響,所以還是需要盡快恢復回來,以提供完整的服務能力。這事肯定不能人為去干預,及時性必然會受到影響。
那么如何能夠自動的識別依賴系統是否“可用”呢?這也需要你來定義一個策略。
一般來說這個策略與識別“不可用”的策略類似,只是這里是一個反向指標:
-
閾值。比如,在 10 秒內出現 100 次“調用成功”并且耗時都小于 1 秒。
-
百分比。比如,在 10 秒內有 95% 請求“調用成功”并且 98% 的請求小于1秒。
同樣包含「時間窗口」、「閾值」以及「百分比」。稍微不同的地方在于,大多數情況下,一個系統“不可用”的狀態往往會持續一段時間,不會那么快就恢復過來。
所以我們不需要像第一步中識別“不可用”那樣,無時無刻的記錄請求狀況,而只需要在每隔一段時間之后去進行探測即可。
所以,這里多了一個「間隔時間」的概念。這個間隔幅度可以是固定的,比如 30 秒。也可以是動態增加的,通過線性增長或者指數增長等方式。
這個用代碼表述大致是這樣:
- 全局變量 successCount = 0;
- //有個獨立的線程每隔10秒(時間窗口)重置為0。
- //并且將下面的isHalfOpen設為false。
- 全局變量 isHalfOpen = true;
- //有個獨立的線程每隔30秒(間隔時間)重置為true。
- //do some thing...
- if(success){
- if(isHalfOpen){
- successCount ++;
- if(successCount = 可用閾值){
- isOpenCircuitBreaker = false;
- }
- }
- return success;
- }
- else{
- errorcount++;
- if(errorcount == 不可用閾值){
- isOpenCircuitBreaker = true;
- }
- }
另外,嘗試探測本質上是一個“試錯”,要控制下“試錯成本”。所以我們不可能拿 100% 的流量去驗證,一般會有以下兩種方式:
-
放行一定比例的流量去驗證。
-
如果在整個通信框架都是統一的情況下,還可以統一給每個系統增加一個專門用于驗證程序健康狀態檢測的獨立接口。
這個接口額外可以多返回一些系統負載信息用于判斷健康狀態,如 CPU、I/O 的情況等。
重新恢復正常
一旦通過了衡量是否“可用”的驗證,整個系統就恢復到了“正常”狀態,此時需要重新開啟識別“不可用”的策略。
就這樣,系統會形成一個循環,如下圖:
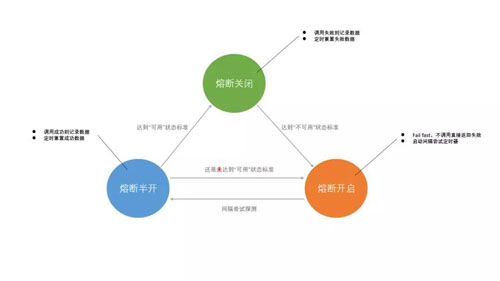
這就是一個完整的熔斷機制的面貌。了解了這些核心思想,用什么框架去實施就變得不是那么重要了,因為大部分都是換湯不換藥。
上面聊到的這些可以說是主干部分,還有一些最佳實踐可以讓你在實施熔斷的時候拿捏的更到位。
做熔斷的最佳實踐
什么場景最適合做熔斷
一個事物在不同的場景里會發揮出不同的效果。以下是我能想到最適合熔斷發揮更大優勢的幾個場景:
-
所依賴的系統本身是一個共享系統,當前客戶端只是其中的一個客戶端。這是因為,如果其他客戶端進行胡亂調用也會影響到你的調用。
-
所有依賴的系統被部署在一個共享環境中(資源未做隔離),并不獨占使用。比如,和某個高負荷的數據庫在同一臺服務器上。
-
所依賴的系統是一個經常會迭代更新的服務。這點也意味著,越“敏捷”的系統越需要“熔斷”。
-
當前所在的系統流量大小是不確定的。比如,一個電商網站的流量波動會很大,你能抗住突增的流量不代表所依賴的后端系統也能抗住。這點也反映出了我們在軟件設計中帶著“面向懷疑”的心態的重要性。
做熔斷時還要注意的一些地方
與所有事物一樣,熔斷也不是一個完美的事物,我們特別需要注意兩個問題。
首先,如果所依賴的系統是多副本或者做了分區的,那么要注意其中個別節點的異常并不等于所有節點都存在異常,需要區別對待。
其次,熔斷往往應作為最后的選擇,我們應優先使用一些「降級」或者「限流」方案。
因為“部分勝于無”,雖然無法提供完整的服務,但盡可能的降低影響是要持續去努力的。
比如,拋棄非核心業務、給出友好提示等等,這部分內容我們會在后續的文章中展開。
總結
本文主要聊了熔斷的作用以及做法,并且總結了一些我自己的最佳實踐。
從上面的這些代碼示例中也可以看到,熔斷代碼所在的位置要么在實際方法之前,要么在實際方法之后。
它非常適合 AOP 編程思想的發揮,所以我們平常用到的熔斷框架都會基于 AOP 去做。
熔斷只是一個保護殼,在周圍出現異常的時候保全自身。但是從長遠來看平時定期做好壓力測試才能更好的防范于未然,降低觸發熔斷的次數。
如果清楚的知道每個系統有幾斤幾兩,在這個基礎上再把「限流」和「降級」做好,這基本就將“高壓”下觸發熔斷的概率降到最低了。