常見分布式文件存儲介紹、選型比較、架構設計
Hello,我是瓜哥:
之前在進行對接存儲項目的時候,對公司內部使用的文件系統進行了梳理,當前公司內部使用的文件系統有GlusterFS,FastDFS等,由于文件系統在海量小文件和高并發之下性能急劇下降,性能遭遇瓶頸,因此打算建設分布式對象存儲平臺。下面對市面上比較流行的非結構化文件存儲產品進行相關整理和比較。
分布式文件存儲的來源
在這個數據爆炸的時代,產生的數據量不斷地在攀升,從GB,TB,PB,ZB.挖掘其中數據的價值也是企業在不斷地追求的終極目標。但是要想對海量的數據進行挖掘,首先要考慮的就是海量數據的存儲問題,比如Tb量級的數據。
談到數據的存儲,則不得不說的是磁盤的數據讀寫速度問題。早在上個世紀90年代初期,普通硬盤的可以存儲的容量大概是1G左右,硬盤的讀取速度大概為4.4MB/s.讀取一張硬盤大概需要5分鐘時間,但是如今硬盤的容量都在1TB左右了,相比擴展了近千倍。但是硬盤的讀取速度大概是100MB/s。讀完一個硬盤所需要的時間大概是2.5個小時。所以如果是基于TB級別的數據進行分析的話,光硬盤讀取完數據都要好幾天了,更談不上計算分析了。那么該如何處理大數據的存儲,計算分析呢?
常用的分布式文件存儲
常見的分布式文件系統
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自適用于不同的領域。它們都不是系統級的分布式文件系統,而是應用級的分布式文件存 儲服務。
分布式文件存儲選型比較
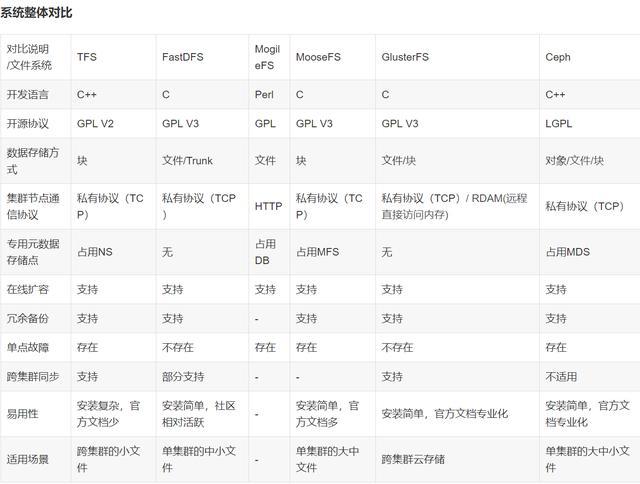
知名開源分布式文件存儲
1.GFS(Google File System)
Google公司為了滿足本公司需求而開發的基于Linux的專有分布式文件系統。盡管Google公布了該系統的一些技術細節,但Google并沒有將該系統的軟件部分作為開源軟件發布。
2.HDFS
Hadoop 實現了一個分布式文件系統(Hadoop Distributed File System),簡稱HDFS。 Hadoop是Apache Lucene創始人Doug Cutting開發的使用廣泛的文本搜索庫。它起源于Apache Nutch,
后者是一個開源的網絡搜索引擎,本身也是Luene項目的一部分。Aapche Hadoop架構是MapReduce算法的一種開源應用,是Google開創其帝國的重要基石。
3.TFS
TFS(Taobao FileSystem)是一個高可擴展、高可用、高性能、面向互聯網服務的分布式文件系統,主要針對海量的非結構化數據,它構筑在普通的Linux機器 集群上,可為外部提供高可靠
和高并發的存儲訪問。TFS為淘寶提供海量小文件存儲,通常文件大小不超過1M,滿足了淘寶對小文件存儲的需求,被廣泛地應用 在淘寶各項應用中。它采用了HA架構和平滑擴容,保證了整個文件系統的可用性和擴展性。同時扁平化的數據組織結構,可將文件名映射到文件的物理地址,簡化 了文件的訪問流程,一定程度上為TFS提供了良好的讀寫性能。
Google學術論文,這是眾多分布式文件系統的起源,HDFS和TFS都是參考Google的GFS設計出來的。
典型的分布式文件存儲的架構設計
我以hadoop的HDFS為例,畢竟開源的分布式文件存儲使用的最多。
Hadoop分布式文件系統(HDFS)被設計成適合運行在通用硬件(commodity hardware)上的分布式文件系統。HDFS是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,非常適合大規模數據集上的應用。HDFS放寬了一部分POSIX約束,來實現流式讀取文件系統數據的目的。
大規模數據集
運行在HDFS上的應用具有很大的數據集。HDFS上的一個典型文件大小一般都在G字節至T字節。因此,HDFS被調節以支持大文件存儲。它應該能提供整體上高的數據傳輸帶寬,能在一個集群里擴展到數百個節點。一個單一的HDFS實例應該能支撐數以千萬計的文件。
簡單的一致性模型
HDFS應用需要一個“一次寫入多次讀取”的文件訪問模型。一個文件經過創建、寫入和關閉之后就不需要改變。這一假設簡化了數據一致性問題,并且使高吞吐量的數據訪問成為可能。Map/Reduce應用或者網絡爬蟲應用都非常適合這個模型。目前還有計劃在將來擴充這個模型,使之支持文件的附加寫操作。
異構軟硬件平臺間的可移植性
HDFS在設計的時候就考慮到平臺的可移植性。這種特性方便了HDFS作為大規模數據應用平臺的推廣。
Namenode 和 Datanode
HDFS采用master/slave架構。一個HDFS集群是由一個Namenode和一定數目的Datanodes組成。
Namenode是一個中心服務器,負責管理文件系統的名字空間(namespace)以及客戶端對文件的訪問。
集群中的Datanode一般是一個節點一個,負責管理它所在節點上的存儲。HDFS暴露了文件系統的名字空間,用戶能夠以文件的形式在上面存儲數據。從內部看,一個文件其實被分成一個或多個數據塊,這些塊存儲在一組Datanode上。
Namenode執行文件系統的名字空間操作,比如打開、關閉、重命名文件或目錄。它也負責確定數據塊到具體Datanode節點的映射。Datanode負責處理文件系統客戶端的讀寫請求。在Namenode的統一調度下進行數據塊的創建、刪除和復制。
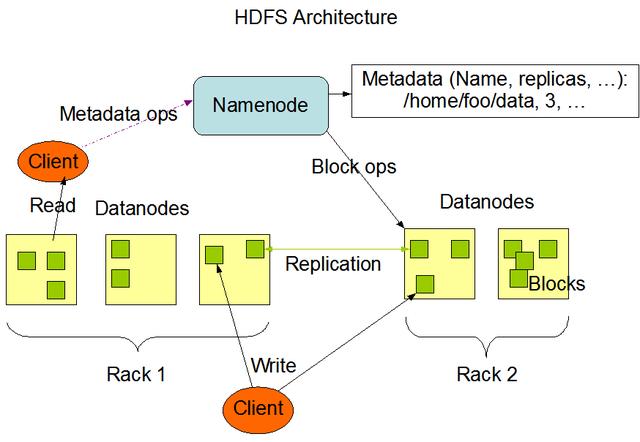
Namenode和Datanode被設計成可以在普通的商用機器上運行。這些機器一般運行著GNU/Linux操作系統(OS)。HDFS采用Java語言開發,因此任何支持Java的機器都可以部署Namenode或Datanode。由于采用了可移植性極強的Java語言,使得HDFS可以部署到多種類型的機器上。一個典型的部署場景是一臺機器上只運行一個Namenode實例,而集群中的其它機器分別運行一個Datanode實例。這種架構并不排斥在一臺機器上運行多個Datanode,只不過這樣的情況比較少見。
分布式存儲的未來
隨著現代社會從工業時代過渡到信息時代,信息技術的發展以及人類生活的智能化帶來數據的爆炸性增長,數據正成為世界上最有價值的資源。
根據物理存儲形態,數據存儲可分為集中式存儲與分布式存儲兩種。集中式存儲以傳統存儲陣列(傳統存儲)為主,分布式存儲(云存儲)以軟件定義存儲為主。
傳統存儲一向以可靠性高、穩定性好,功能豐富而著稱,但與此同時,傳統存儲也暴露出橫向擴展性差、價格昂貴、數據連通困難等不足,容易形成數據孤島,導致數據中心管理和維護成本居高不下。
分布式存儲:將數據分散存儲在網絡上的多臺獨立設備上,一般采用標準x86服務器和網絡互聯,并在其上運行相關存儲軟件,系統對外作為一個整體提供存儲服務。。
總之,分布式文件存儲,不僅提高了存儲空間的利用率,還實現了彈性擴展,降低了運營成本,避免了資源浪費,更適合未來的數據爆炸時代場景。