談?wù)勱P(guān)于NVMe和NVMe-oF的那些事
NVMe傳輸是一種抽象協(xié)議層,旨在提供可靠的NVMe命令和數(shù)據(jù)傳輸。為了支持?jǐn)?shù)據(jù)中心的網(wǎng)絡(luò)存儲,通過NVMe over Fabric實現(xiàn)NVMe標(biāo)準(zhǔn)在PCIe總線上的擴展,以此來挑戰(zhàn)SCSI在SAN中的統(tǒng)治地位。NVMe over Fabric支持把NVMe映射到多個Fabrics傳輸選項,主要包括FC、InfiniBand、RoCE v2、iWARP和TCP。
然而,在這些Fabrics選項協(xié)議中,我們常常認(rèn)為InfiniBand、RoCE v2(可路由的RoCE)、iWARP是理想的Fabric,其原因在于它們支持RDMA。
- InfiniBand(IB):從一開始就支持RDMA的新一代網(wǎng)絡(luò)協(xié)議。由于這是一種新的網(wǎng)絡(luò)技術(shù),因此需要支持該技術(shù)的網(wǎng)卡和交換機。
- RDMA融合以太網(wǎng)(RoCE):一種允許通過以太網(wǎng)進行RDMA的網(wǎng)絡(luò)協(xié)議。其較低的網(wǎng)絡(luò)頭是以太網(wǎng)頭,其上網(wǎng)絡(luò)頭(包括數(shù)據(jù))是InfiniBand頭。這允許在標(biāo)準(zhǔn)以太網(wǎng)基礎(chǔ)架構(gòu)(交換機)上使用RDMA。只有NIC應(yīng)該是特殊的,并支持RoCE。
- 互聯(lián)網(wǎng)廣域RDMA協(xié)議(iWARP):允許通過TCP執(zhí)行RDMA的網(wǎng)絡(luò)協(xié)議。在IB和RoCE中存在功能,iWARP不支持這些功能。這允許在標(biāo)準(zhǔn)以太網(wǎng)基礎(chǔ)架構(gòu)(交換機)上使用RDMA。只有NIC應(yīng)該是特殊的,并支持iWARP(如果使用CPU卸載),否則所有iWARP堆棧都可以在SW中實現(xiàn),并且丟失了大部分的RDMA性能優(yōu)勢。
那么為什么支持RDMA在選擇NVMe over Fabric時就具有先天優(yōu)勢?這要從RDMA的功能和優(yōu)勢說起。
RDMA是一種新的內(nèi)存訪問技術(shù),RDMA讓計算機可以直接存取其他計算機的內(nèi)存,而不需要經(jīng)過處理器耗時的處理。RDMA將數(shù)據(jù)從一個系統(tǒng)快速移動到遠(yuǎn)程系統(tǒng)存儲器中,而不對操作系統(tǒng)造成任何影響。RDMA技術(shù)的原理及其與TCP/IP架構(gòu)的對比如下圖所示。
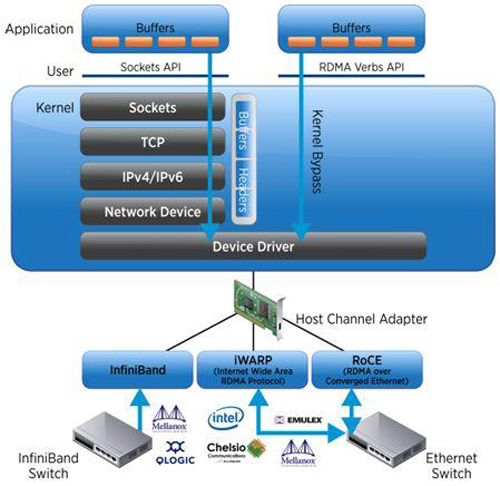
因此,RDMA可以簡單理解為利用相關(guān)的硬件和網(wǎng)絡(luò)技術(shù),服務(wù)器1的網(wǎng)卡可以直接讀寫服務(wù)器2的內(nèi)存,最終達(dá)到高帶寬、低延遲和低資源利用率的效果。如下圖所示,應(yīng)用程序不需要參與數(shù)據(jù)傳輸過程,只需要指定內(nèi)存讀寫地址,開啟傳輸并等待傳輸完成即可。RDMA的主要優(yōu)勢總結(jié)如下:
1) Zero-Copy:數(shù)據(jù)不需要在網(wǎng)絡(luò)協(xié)議棧的各個層之間來回拷貝,這縮短了數(shù)據(jù)流路徑。
2) Kernel-Bypass:應(yīng)用直接操作設(shè)備接口,不再經(jīng)過系統(tǒng)調(diào)用切換到內(nèi)核態(tài),沒有內(nèi)核切換開銷。
3) None-CPU:數(shù)據(jù)傳輸無須CPU參與,完全由網(wǎng)卡搞定,無需再做發(fā)包收包中斷處理,不耗費CPU資源。
這么多優(yōu)勢總結(jié)起來就是提高處理效率,減低時延。那如果其他網(wǎng)絡(luò)Fabric可以通過類似RDMA的技術(shù)滿足NVMe over Fabric的效率和時延等要求,是否也可以作為NVMe overFabric的Fabric呢?下面再看看NVMe-oF和NVMe的區(qū)別。
NVMe-oF和NVMe之間的主要區(qū)別是傳輸命令的機制。NVMe通過外圍組件互連Express(PCIe)接口協(xié)議將請求和響應(yīng)映射到主機中的共享內(nèi)存。NVMe-oF使用基于消息的模型通過網(wǎng)絡(luò)在主機和目標(biāo)存儲設(shè)備之間發(fā)送請求和響應(yīng)。
NVMe-oF替代PCIe來擴展NVMe主機和NVMe存儲子系統(tǒng)進行通信的距離。與使用本地主機的PCIe 總線的NVMe存儲設(shè)備的延遲相比,NVMe-oF的最初設(shè)計目標(biāo)是在通過合適的網(wǎng)絡(luò)結(jié)構(gòu)連接的NVMe主機和NVMe存儲目標(biāo)之間添加不超過10 微秒的延遲。
此外,在技術(shù)細(xì)節(jié)和工作機制上兩者有很大不同,NVMe-oF是在NVMe(NVMe over PCIe)的基礎(chǔ)上擴展和完善起來的,具體差異點如下:
- 命名機制在兼容NVMe over PCIe的基礎(chǔ)上做了擴展,例如:引入了SUBNQN等。
- 術(shù)語上的變化,使用Capsule、Response Capsule來表示傳輸?shù)膱笪?/li>
- 擴展了Scatter Gather Lists (SGLs)支持In Capsule Data傳輸。此前NVMe over PCIe中的SGL不支持In Capsule Data傳輸。
- 增加了Discovery和Connect機制,用于發(fā)現(xiàn)和連接拓?fù)浣Y(jié)構(gòu)中的NVM Subsystem
- 在Connection機制中增加了創(chuàng)建Queue的機制,刪除了NVMe over PCIe中的創(chuàng)建和刪除Queue的命令。
- 在NVMe-oF中不存在PCIe架構(gòu)下的中斷機制。
- NVMe-oF不支持CQ的流控,所以每個隊列的OutStanding Capsule數(shù)量不能大于對應(yīng)CQ的Entry的數(shù)量,從而避免CQ被OverRun
- NVMe-oF僅支持SGL,NVMe over PCIe 支持SGL/PRP
先談?wù)劜┛埔恢蓖瞥绲腇C Fabric,F(xiàn)C-NVMe將NVMe命令集簡化為基本的FCP指令。由于光纖通道專為存儲流量而設(shè)計,因此系統(tǒng)中內(nèi)置了諸如發(fā)現(xiàn),管理和設(shè)備端到端驗證等功能。
光纖通道是面向NVMe overFabrics(NVMe-oF)的Fabric傳輸選項,由NVMExpress Inc.(一家擁有100多家成員技術(shù)公司的非營利組織)開發(fā)的規(guī)范。其他NVMe傳輸選項包括以太網(wǎng)和InfiniBand上的遠(yuǎn)程直接內(nèi)存訪問(RDMA)。NVM Express Inc.于2016年6月5日發(fā)布了1.0版NVMe-oF。
國際信息技術(shù)標(biāo)準(zhǔn)委員會(INCITS)的T11委員會定義了一種幀格式和映射協(xié)議,將NVMe-oF應(yīng)用到光纖通道。T11委員會于2017年8月完成了FC-NVMe標(biāo)準(zhǔn)的***版,并將其提交給INCITS出版。
FC協(xié)議(FCP)允許上層傳輸協(xié)議,如NVMe,小型計算機系統(tǒng)接口(SCSI)和IBM專有光纖連接(FICON)的映射,以實現(xiàn)主機和外圍目標(biāo)存儲設(shè)備或系統(tǒng)之間的數(shù)據(jù)和命令傳輸。
在大規(guī)模基于塊閃存的存儲環(huán)境最有可能采用NVMeover FC。FC-NVMe光纖通道提供NVMe-oF結(jié)構(gòu)、可預(yù)測性和可靠性特性等與給SCSI提供的相同,另外,NVMe-oF流量和傳統(tǒng)的基于SCSI的流量可以在同一FC結(jié)構(gòu)上同時運行。
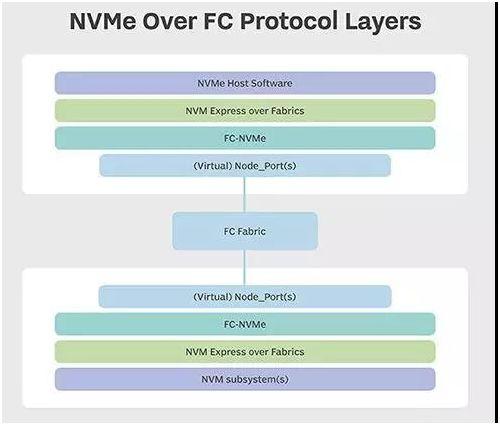
基于FC標(biāo)準(zhǔn)的NVMe定義了FC-NVMe協(xié)議層。NVMe over Fabrics規(guī)范定義了NVMe-oF協(xié)議層。NVMe規(guī)范定義了NVMe主機軟件和NVM子系統(tǒng)協(xié)議層。
要求必須支持基于光纖通道的NVMe才能發(fā)揮潛在優(yōu)勢的基礎(chǔ)架構(gòu)組件,包括存儲操作系統(tǒng)(OS)和網(wǎng)絡(luò)適配器卡。FC存儲系統(tǒng)供應(yīng)商必須讓其產(chǎn)品符合FC-NVMe的要求。目前支持FC-NVMe的主機總線適配器(HBA)的供應(yīng)商包括Broadcom和Cavium。Broadcom和思科是主要的FC交換機供應(yīng)商,目前博科的Gen 6代FC交換機已經(jīng)支持NVMe-oF協(xié)議。
NVMe over fabric白皮書明確列出了光纖通道作為一個NVMeover Fabrics選擇,也描述了理想的Fabrics需要具備可靠的、以Credit為基礎(chǔ)的流量控制和交付機制。然而,基于Credit的流程控制機制是FC、PCIe傳輸原生能力。在NVMe的白皮書中并沒有把RDMA列為“理想”NVMe overFabric的重要屬性,也就是說RDMA除了只是一種實現(xiàn)NVMeFabric的方法外,沒有什么特別的。
FC也提供零拷貝(Zero-Copy)技術(shù)支持DMA數(shù)據(jù)傳輸。RDMA通過從本地服務(wù)器傳遞Scatter-Gather List到遠(yuǎn)程服務(wù)器有效地將本地內(nèi)存與遠(yuǎn)程服務(wù)器共享,使遠(yuǎn)程服務(wù)器可以直接讀取或?qū)懭氡镜胤?wù)器的內(nèi)存。更多關(guān)于NVMe over FC的內(nèi)容,請參考“基于FC的NVMe或FC-NVMe標(biāo)準(zhǔn)”和“Brocade為何認(rèn)為FC是***的Fabric”。
接下來,談?wù)劵赗DMA技術(shù)實現(xiàn)NVMe over fabric的Fabric技術(shù),RDMA技術(shù)最早出現(xiàn)在Infiniband網(wǎng)絡(luò),用于HPC高性能計算集群的互聯(lián)。基于InfiniBand的NVMe傾向于吸引需要極高帶寬和低延遲的高性能計算工作負(fù)載。InfiniBand網(wǎng)絡(luò)通常用于后端存儲系統(tǒng)內(nèi)的通信,而不是主機到存儲器的通信。與FC一樣,InfiniBand是一個需要特殊硬件的無損網(wǎng)絡(luò),它具有諸如流量和擁塞控制以及服務(wù)質(zhì)量(QoS)等優(yōu)點。但與FC不同的是,InfiniBand缺少發(fā)現(xiàn)服務(wù)自動將節(jié)點添加到結(jié)構(gòu)中。關(guān)于更多RDMA知識,請讀者參考文章“RDMA技術(shù)原理分析、主流實現(xiàn)對比和解析”。
***,談?wù)凬VMe/TCP協(xié)議選項(暫記為NVMe over TCP),在幾年前,NVMe Express組織計劃支持傳輸控制協(xié)議(TCP)的傳輸選項(不同于基于TCP的iWARP)。近日NVM Express Inc.歷時16個月發(fā)布了NVMe over TCP***個版本。該Fabric標(biāo)準(zhǔn)的出現(xiàn)已經(jīng)回答了是否滿足承載NVMe協(xié)議標(biāo)準(zhǔn)的Fabric即可作為NVMe over fabric的Fabric的問題。
但是TCP 協(xié)議會帶來遠(yuǎn)高于本地PCIe訪問的網(wǎng)絡(luò)延遲,使得NVMe協(xié)議低延遲的目標(biāo)遭到破壞。在沒有采用RDMA技術(shù)的前提下,NVMe/TCP是采用什么技術(shù)達(dá)到類似RDMA技術(shù)的傳輸效果呢?下面引用楊子夜(Intel存儲軟件工程師)觀點,談?wù)劥偈沽薔VMe/TCP的誕生幾個技術(shù)原因:
1. NVMe虛擬化的出現(xiàn):在NVMe虛擬化實現(xiàn)的前提下,NVMe-oF target那端并不一定需要真實的NVMe 設(shè)備,可以是由分布式系統(tǒng)抽象虛擬出來的一個虛擬NVMe 設(shè)備,為此未必繼承了物理NVMe設(shè)備的高性能的屬性 。那么在這一前提下,使用低速的TCP協(xié)議也未嘗不可。
2. 向后兼容性:NVMe-oF協(xié)議,在某種程度上希望替換掉iSCSI 協(xié)議(iSCSI最初的協(xié)議是RFC3720,有很多擴展)。iSCSI協(xié)議只可以在以太網(wǎng)上運行,對于網(wǎng)卡沒有太多需求,并不需要網(wǎng)卡一定支持RDMA。當(dāng)然如果能支持RDMA, 則可以使用iSER協(xié)議,進行數(shù)據(jù)傳輸?shù)腃PU 資源卸載。 但是NVMe-oF協(xié)議一開始沒有TCP的支持。于是當(dāng)用戶從iSCSI向NVMe-oF 轉(zhuǎn)型的時候,很多已有的網(wǎng)絡(luò)設(shè)備無法使用。這樣會導(dǎo)致NVMe-oF協(xié)議的接受度下降。在用戶不以性能為首要考量的前提下,顯然已有NVMe-oF協(xié)議對硬件的要求,會給客戶的轉(zhuǎn)型造成障礙,使得用戶數(shù)據(jù)中心的更新?lián)Q代不能順滑地進行。
3. TCP OffLoading:雖然TCP協(xié)議在很大程度上會降低性能,但是TCP也可以使用OffLoading,或者使用Smart NIC或者FPGA。那么潛在的性能損失可得到一定的彌補。總的來說短期有性能損失,長期來講協(xié)議對硬件的要求降低,性能可以改進。為此總的來講,接受度會得到提升。
4. 相比Software RoCE:在沒有TCP Transport的時候,用戶在不具備RDMA網(wǎng)卡設(shè)備的時候。如果要進行NVMe-oF的測試,需要通過Software RoCE,把網(wǎng)絡(luò)設(shè)備模擬成一個具有RDMA功能的設(shè)備,然后進行相應(yīng)的測試。其真實實現(xiàn)是通過內(nèi)核的相應(yīng)模塊,實際UDP 包來封裝模擬RDMA協(xié)議。有了TCP transport協(xié)議,則沒有這么復(fù)雜,用戶可以采用更可靠的TCP協(xié)議來進行NVMe-oF的一些相關(guān)測試。 從測試部署來講更加簡單有效。
NVMe/TCP(NVMe over TCP)的協(xié)議,在一定程度上借鑒了iSCSI的協(xié)議,例如iSCSI數(shù)據(jù)讀寫的傳輸協(xié)議。這個不太意外,因為有些協(xié)議的指定參與者,也是iSCSI協(xié)議的指定參與者。另外iSCSI協(xié)議的某些部分確實寫得很好。 但是NVMe/TCP相比iSCSI協(xié)議更加簡單,可以說是取其精華。