10步帶你認識大數據和云計算,走出懵逼圈
***步:大數據
“大數據”這個概念是近幾年開始火起來的,現在可謂是無處不在了。在了解什么是大數據之前,我們先了解一下什么是傳統數據?
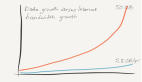
傳統數據就是IT業務系統里面的數據,如客戶資料、財務數據等。這些數據是結構化的,量也不是特別大,一般只是TB級。對比傳統數據,還有一種叫“新數據”,是來源于社區網絡、互聯網等渠道,包括文本、圖片、音頻、視頻等非結構化的數據。目前全世界75%以上都是非結構化數據,而且還一直呈現爆炸性的增長。我們看看下面的圖就更好理解了:

大數據就是:結構化的傳統數據+非結構化的新數據。
因而,大數據還具有以下特點,簡稱“4V”:
- Volume(大量):數據體量巨大,從TB級別,躍升到PB級別;
- Variety(多樣):數據類型繁多,有網絡日志、視頻、圖片、地理位置信息等;
- Velocity(高速):處理速度快,可從各種類型的數據中快速獲得高價值的信息,這一點也是和傳統的數據挖掘技術有著本質的不同;
- Value(價值):只要合理利用數據并對其進行正確、準確的分析,將會帶來很高的價值回報。
第二步:大數據組成
大數據系統由基礎設施、平臺和應用組成。對比我們平時使用的電腦,基礎設施就是電腦這臺硬件,平臺就是裝在里面的操作系統,應用就是操作系統上面的各種應用程序。

大數據的應用五花八門,但總體上可分為“業務應用”和“數據分析”兩大類。
前者包括ERP、CRM等業務系統,后者指的是各種分析應用,包括經營分析、價值分析、人流分析等等。分析系統從業務系統獲取源數據,經過分析后可以反哺業務系統,對其進行賦能(注智),讓其具有智慧。說到這里,大家是不是覺得有點熟悉了?跟我們的BI是不是有某些聯系呢?沒錯了,“大數據平臺”和“數據分析系統”加在一起就是BI的升級版啊!既然是升級版,它與傳統BI有什么區別呢?請看下面就知道啦。
成本更低廉
去IOE,硬件采用廉價的X86,軟件更多使用開源,節省成本
容災性好
平臺部署在X86集群上,機器出問題可隨時切換
擴展性好
X86集群可根據需要隨時進行擴展,提高靈活性
處理效率高
當數據達到TB級別,處理效率顯著提高
處理類型多
可以處理結構化、半結構化、非結構化數據
進一步挖掘價值
處理的數據量大,類型多,因而可進一步挖掘數據的價值。
是不是有很多升級的地方呢?為了支持這些升級,大數據系統需要具備哪些功能呢?這就涉及到架構問題了,跟著小麥繼續往下看吧。
第三步:大數據架構
我們已經知道大數據系統由基礎設施、平臺和應用組成,我們現在進一步細分,請看下圖:

基礎設施由通過局域網或互聯網連接的X86集群組成,為大數據平臺提供最基本的硬件支持。
大數據平臺由基礎架構、數據處理和數據服務三部分組成:
基礎架構負責對基礎設施進行系統管理,為數據處理提供分布式底層服務;數據處理負責數據的采集、存儲、計算;數據服務負責將處理后的數據提供給上層應用使用。大數據應用是面向用戶的各種應用系統,包括業務應用和數據分析。大數據系統的總體架構就是這樣子,是不是跟我們平時見到的BI架構很像呢? 通過這個表格對比我們就更清楚了:

下面我們將圍繞這個架構展開說明。理解了這個架構,小麥的目的也就達到啦。
第四步:虛擬化
基礎設施提供計算、存儲、網絡三種能力,是大數據平臺的根基。但是如何解決以下問題:
大量的機器如何管理
當集群的狀態改變,也即增加或者減少一些機器的時候,難道要去修改平臺的配置嗎?
如何充分利用系統資源
當集群的能力只使用了一部分,而這個時候需要一部新的機器用來部署其它系統,難道是從集群上拆下一部機器來提供嗎?
如何解決彈性問題
當高峰期的時候,系統可能需要20部機器,平時只需要10部。那么我們是提供多少部合適呢?如果提供20部,平時空閑下來的10部如何處理?
這些問題有一種解決方法:虛擬化。就是把集群作為一個整體進行管理,可以根據需要從某些機器中調配相關資源,快速組成一部“新的機器”。例如可以用機器A的CPU1/2性能、1/3的內存,和機器B的1/5硬盤組成。
當集群的狀態改變時,我們只需要修改虛擬化軟件的配置,減少對平臺的影響。當集群有多余的資源時,可以虛擬出一些新的機器給其它系統使用,充分利用了系統資源。
虛擬化的主流商業軟件是Vmware,開源的軟件有Xen、KVM等。
第五步:云化
虛擬化雖然帶來資源配置的靈活性,但也有明顯的缺陷。配置一部“新的機器”需要人工操作,配置非常麻煩,最多只能管理幾百臺電腦的規模,作為企業內部的應用是可以的。但對于提供公眾服務的互聯網公司來說,需要上萬部電腦的規模,通過虛擬化的方式是行不通的。所以又有了新技術的出現:云化,也即把基礎設施作為一項服務提供。請看下圖:

最早是亞馬遜基于自身電商業務的發展,傳統的IT架構已經滿足不了需求,所以基于開源的虛擬化軟件開發了AWS(Amazon Web Service),可以支持超大規模的集群應用。在解決自己的業務需求后,亞馬遜發現可以把這項技術作為一項單獨的業務推向市場,這就是現在穩居全球市場頭把交椅的的亞馬遜云服務。同樣的背景,阿里巴巴也基于Xen推出了市場化的阿里云,現成已經成為國內云市場的老大。由此我們也知道為什么云服務做得最早、***的都是互聯網公司了吧?因為他們有自身的業務在驅動。規模上萬部的機器,以資源池(數據中心)的形式分布在不同的地域上(很多建設在廣西、貴州、內蒙等欠發達省份,電費、人工比較便宜,又可以促進當地就業),通過調度中心進行統一管理,這就是公有云平臺。
在亞馬遜開展商業化云服務的同時,美國另一家叫Rackspace的公司也推出OpenStack在跟亞馬遜競爭。無奈競爭不過人家,***決定和NASA(美國國家航空航天局)合作,把OpenStack開源,一起成立了開源云平臺。后來各家傳統的IT巨頭紛紛加入這個開源的社區,經過二次開發和包裝后推出了自己的私有云平臺,和自家的硬件或解決方案打包一起銷售。
不管是公有云,還是私有云,都是實現了基礎設施的時間靈活性和空間靈活性,把基礎設施作為一項服務提供,也即:Infranstracture as a Service(IaaS)
第六步:Hadoop
大數據平臺的基礎架構采用Hadoop,包括HDFS和MapReduce兩部分:
- HDFS在集群上實現分布式文件系統,負責對文件的操作。(類似windows下的文件管理系統NTFS)
- MapReduce在集群上實現分布式計算和任務處理,負責將作業分解成多個任務,分派到多部機器一起執行,同時監控執行情況,保證每個任務都能順利執行,所有任務結束后再將結果匯總。(類似多個人一起數圖書館的書,每個人算一個書架(Map),***把所有結果加在一起(Reduce))
那么,如何把Hadoop安裝到集群下面那么多機器上呢?每部機器的配置、操作系統都可能不一樣。
解決辦法就是采用“容器“技術:先將Hadoop打包到一個封閉的容器中,再統一發布到各部機器上。容器能夠根據機器實際環境做出相應的調整,保證Hadoop的順利安裝。(類似用統一規格的集裝箱來運送貨物)
容器的主流技術是開源的Docker。不僅僅是Hadoop可以通過容器進行安裝,所有的應用都可以使用。
現在已經在集群下每部機器安裝了Hadoop,那么Hadoop是如何運行的呢?請看下圖:

Hadoop把集群下其中一個節點拿來當Master,其它節點當Slave。對于HDFS來說,Master就是NameNode,負責管理文件系統的命名空間和控制客戶端訪問;Slave就是DataNode,負責管理存儲的數據。對于MapReduce來說,Master就是JobTracker,負責調度構成一個作業的所有任務,這些任務分布在不同的TaskTracker上;Slave就是TaskTracker,負責執行由JobTracker指派的任務。
Hadoop已經衍生出很多不同的升級版本,目前應用最成熟、最廣泛的是Spark。
第七步:數據處理
數據處理是對數據的采集、存儲和計算。因為大數據有各種各樣的應用,不同的應用,數據的種類、結構,數據的實時性要求都可能不同。所以要根據實際情況進行數據庫選型,這是大數據平臺設計的關鍵,將影響到整個平臺的整體性能。不同的數據庫類型可以進行混搭,同時采用不同的ETL技術。
目前常見的各種數據庫類型如下:
傳統數據庫
主流數據庫有Oracle、DB2、MySQL,主要應用于小規模應用系統,或者為了利用已有的資源,同時降低系統升級的風險,采用的ETL技術是Datastage、Kettle等。
內存數據庫
主流數據庫有SQLite、HANA,主要應用于對實時性要求高,需要實時處理的數據,如實時指標展示,精準營銷等,采用的ETL技術是流處理技術kafka。
MPP數據庫
MPP是指大規模并行處理,MPP數據庫支持X86集群,常見的有Greanplum、Vertica等,主要應用于大規模結構化數據分析,如信令分析、DPI分析,一般采用Kettle作為ETL工具。
NoSQL數據庫
NoSQL是指半結構化或非結構化數據庫,主流的數據庫有MongoDB、HBase和HDFS等,HBase用來存儲半結構化或結構很稀疏的數據,HDFS用來存儲非結構化數據。HBase和HDFS都不支持SQL,需要使用Hive作為SQL接口執行一些簡單的查詢操作。NoSQL數據庫基于Hadoop平臺,主要應用于大規模半/非結構化離線分析,例如互聯網數據分析、文檔分析等,一般采用網絡爬蟲技術進行ETL。
第八步:數據服務
經過處理后的數據,一般不提供給上層應用直接用SQL訪問,這一點與數據倉庫不同。數據倉庫把采集過來的數據經過處理后存儲在匯總層,上層應用直接用SQL訪問。但大數據平臺把處理后的數據進行封裝和分類,為上層應用提供可靈活調用的數據服務接口,可以保證數據訪問的規范性和安全性。接口的承載方式有:文件、消息、API、SDK、界面集成,其流程如下:

數據格式化
對原始數據進行格式化,過濾字段并進行排序。
數據封裝
對格式化后的數據及其元數據進行封裝,以實現對外一致、標準化的數據訪問接口。
數據分類
根據封裝后的數據,按主題進行接口分類。
數據服務
上層應用可通過數據服務接口調用數據,實現數據的服務功能。
數據服務接口屏蔽掉大數據平臺的所有細節,把平臺作為一項服務提供給應用使用,這種方式稱之為Platform as a service(PaaS)。
在公有云提供商中,一般都會有對應的PaaS服務提供,如阿里云的EDAS(企業級分布式應用服務)。
私有云是企業自建,對數據訪問的控制沒那么嚴格。為了開發效率,應用通常可以通過SQL直接訪問數據。
第九步:大數據應用
前面小麥已經為大家介紹了基礎設施和大數據平臺,也介紹了私有云和公有云的區別。對于大數據應用來說,私有云上的應用,就是我們平時說的企業信息化系統,只不過這些系統是采用大數據的架構。而公有云上的應用,指的是我們平時使用的互聯網服務,如微信、微博、支付寶等。但是,隨著云服務市場的發展,越來越多的傳統IT廠商也通過公有云為公眾提供服務,比如我們熟悉的 MicrosoftOffice 365。這種把軟件作為服務提供的方式稱之為:Software as a Service(SaaS)。
在國際市場,比較常見的企業級SaaS服務有客戶管理服務Saleforce、團隊協同服務Google Apps等等。國內市場的金蝶、微軟、Oracle也都提供多種SaaS產品和服務。我們可以看一下IDC對2017-2022年中國公有云整體市場的預測(單位:百萬美元):

從上表可以看出,整個云服務市場的年復合增長率達到了41%,其中PaaS服務增長最快,達到了55.7%。中國企業級SaaS市場份額全球第二,未來五年依舊呈現快速增長態勢,年復合增長率達到35.7%。到了2022年,整個SaaS市場規模達到400億人民幣。
第十步:云計算
大家有沒有發現,前面說了那么久,還沒提到云計算呢?其實前面都是鋪墊,現在就要給大家介紹云計算了。云計算就是一種IT架構,是一種IT資源的交付和使用模式。前面介紹的IaaS、PaaS、SaaS就是云計算架構下對不同資源的交付模式,分別將基礎設施、平臺、軟件以服務的形式提供給用戶使用。
到目前為止,小麥已經把相關的概念都介紹給大家了。我們把前面的大數據架構圖進一步細化,大家是否看得懂了呢?

如果大家看懂了,那小麥本次的介紹也算功德圓滿了。如果還沒看懂,請跳到***步再看一遍,哈哈。。。。