為什么你需要開源分布式流存儲Pravega?
工業(yè)物聯(lián)網(wǎng),車聯(lián)網(wǎng)和實時欺詐風(fēng)控的需求正在飛速的發(fā)展。越來越多的企業(yè)新應(yīng)用,需要的是快速響應(yīng)客戶需求,并同時學(xué)習(xí)和適應(yīng)不斷變化的行為模式。同時隨著 5G 網(wǎng)絡(luò)、容器云、高性能存儲硬件水平的不斷提高,讓實時流處理正在擁有越來越廣泛的市場前景。
流處理在短時間內(nèi)就能夠?qū)B續(xù)生成的數(shù)據(jù)進行分析產(chǎn)生價值,而無需等待批處理中累積和處理,從攝取到結(jié)果的低延遲是流處理技術(shù)提供的最為關(guān)鍵的優(yōu)勢。例如對于車載系統(tǒng)的分析反饋,集群性能日志數(shù)據(jù)的分析告警,金融欺詐風(fēng)控的精準定位、物聯(lián)網(wǎng)煤氣泄漏事件處理等應(yīng)用而言,高并發(fā)下的 10ms 級別的低延時意味著最關(guān)鍵的商業(yè)價值。
流式處理看似簡單 : 只需在數(shù)據(jù)到達時以快速、持續(xù)和***的方式對其進行處理和操作。但實際情況是,大多數(shù)企業(yè)并沒有可以支持到 PB 至 EB 數(shù)據(jù)量級,并同時滿足采集速率、故障恢復(fù)能力的實時存儲 / 計算引擎。 隨著適合處理批、實時場景的各種定制化存儲、計算引擎的出現(xiàn),在業(yè)務(wù)不斷擴展的過程中,也就無法避免地在企業(yè)級別的大數(shù)據(jù)系統(tǒng)之上堆積復(fù)雜性,造成了不小的資源浪費以及運維困難。
流式傳輸迫使系統(tǒng)設(shè)計人員重新思考基本的計算和存儲原則。當前的大數(shù)據(jù)處理系統(tǒng)無論是何種架構(gòu)都面臨一個共同的問題,即:“計算是原生的流計算,而存儲卻不是原生的流存儲” 。Pravega 團隊重新思考了這一基本的數(shù)據(jù)處理和存儲規(guī)則,為這一場景重新設(shè)計了一種新的存儲類型,即原生的流存儲,命名為”Pravega”,取梵語中“Good Speed”之意。
在 Pravega 之前的流數(shù)據(jù)處理
在大數(shù)據(jù)繁榮的早期階段,MapReduce 興起,我們可以使用數(shù)千臺服務(wù)器的集群分布式處理大量(TB 至 PB 級別)的數(shù)據(jù)集。在一個或多個大數(shù)據(jù)集上運行的這種類型的分布式計算通常被稱為批處理作業(yè)。批處理作業(yè)使各種應(yīng)用程序能夠從原始數(shù)據(jù)中獲得價值,這對于擁有龐大用戶數(shù)據(jù)的企業(yè)的成長起到了重要的作用。
對于大型數(shù)據(jù)集的批處理作業(yè)通常具有幾分鐘到幾小時的完成時間,如此長的延遲對于許多應(yīng)用程序來說并不理想,例如推薦系統(tǒng),使用***數(shù)據(jù)至關(guān)重要,但與此同時,處理的精準性也需要保證,即使最小程度的推薦失敗也可能最終導(dǎo)致用戶離開。加之硬件水平的提升,很快我們開始有了更高的要求。我們希望能夠跟上數(shù)據(jù)產(chǎn)生的步伐得到數(shù)據(jù)處理的結(jié)果,而不是等待數(shù)據(jù)積累然后才處理。低延遲流處理因此慢慢興起。我們將其稱為流處理,因為傳入的數(shù)據(jù)基本上是事件、消息或樣本的連續(xù)流。
許多對實時分析感興趣的公司并不愿意放棄 MapReduce 模型。為了解決延遲限制,一些應(yīng)用程序開始使用微批 (micro-batch) 處理方法:在較短時間內(nèi)累積的較小塊上運行作業(yè)。以 Apache Spark Streaming 為代表的微批處理會以秒級增量對流進行緩沖,然后在內(nèi)存中進行計算。這種方式的實際效果非常好,它確實使應(yīng)用程序能夠在更短的時間內(nèi)獲得更高價值。
但由于緩沖機制的存在,微批處理仍然有著較高的延遲,為了滿足應(yīng)用的低延遲需求,原生的流處理平臺的研發(fā)在近五年中不斷涌現(xiàn),百花齊放。早期的系統(tǒng)包括 S4 和 Apache Storm。Storm 使用成熟,有社區(qū)基礎(chǔ),至今仍然被許多企業(yè)廣泛使用。Heron 是由 Twitter 研發(fā)的新一代流處理引擎,與 Storm 兼容的同時性能更優(yōu)。Apache Samza 和 Kafka Stream 則基于 Apache Kafka 消息系統(tǒng)來實現(xiàn)高效的流處理。
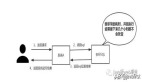
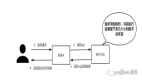
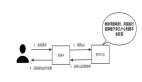
由于批處理和流處理系統(tǒng)使用著不同的框架,企業(yè)為同時滿足實時和批處理的應(yīng)用程序,不得不使用兩套獨立的計算基礎(chǔ)架構(gòu),計算的結(jié)果也同樣進入不同的框架以進行查詢。Storm 的創(chuàng)始人 Nathan Marz 由此提出了 Lambda 的大數(shù)據(jù)處理架構(gòu)(如圖 1),將大數(shù)據(jù)平臺分割成了批處理層、流處理層和應(yīng)用服務(wù)層。Lambda 架構(gòu)遵循讀寫分離,復(fù)雜性隔離的原則,整合了離線計算和實時計算,集成 Hadoop,Kafka,Storm,Spark,Hbase 等各類大數(shù)據(jù)組件,使得兩種處理能夠在高容錯、低延時和可擴展的條件下平穩(wěn)運行。
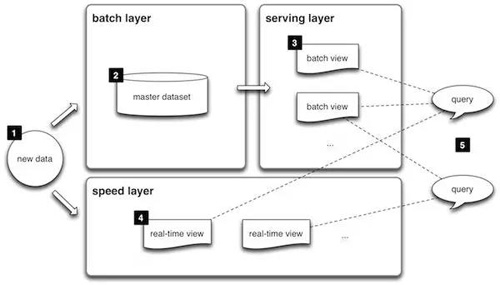
圖 1: Lambda 架構(gòu)
隨著技術(shù)和架構(gòu)的演進,近年來,工程師們開始意識到用流和批兩個詞來區(qū)分應(yīng)用場景,進而給計算框架分類并不合適,兩種處理實質(zhì)上有著許多共同點。在很多場景下,流和批處理應(yīng)用同一套處理邏輯,卻不得不因為框架不同進行重復(fù)開發(fā)。數(shù)據(jù)在產(chǎn)生之時就沒有所謂批和流的概念,只是我們的處理方式不同才導(dǎo)致了數(shù)據(jù)屬性的不同,進而導(dǎo)致了框架的不同。
流和批本來就應(yīng)該沒有界限!
LinkedIn 的 Jay Kreps(Apache Kafka 作者,現(xiàn) Confluent CEO)提出了 Kappa 架構(gòu),將批處理層、流處理層簡化為一致性的流處理。谷歌工程師(Apache Beam 核心人物)Tyler Akidau 提出了 Dataflow 模型則致力于取代谷歌上一代的 MapReduce,將批處理(有限的數(shù)據(jù)流)視為流處理(***的數(shù)據(jù)流)的特例,重新定義大數(shù)據(jù)處理的原語。Apache Flink 作為新一代流處理框架的翹楚,其設(shè)計遵循 Dataflow 模型,從根本上統(tǒng)一了批處理和流處理。而 Apache Spark 也推翻了之前微批處理的設(shè)計,推出了 Structured Streaming,使用表和 SQL 的概念進行處理的統(tǒng)一。
有效地提取和提供數(shù)據(jù)對于流處理應(yīng)用程序的成功至關(guān)重要。由于處理速度和頻率的不同,數(shù)據(jù)的攝取需要通過兩種策略進行。在典型的 Lambda 架構(gòu)中,分布式文件系統(tǒng)(例如 HDFS)負責為批處理應(yīng)用提供高并發(fā)、高吞吐量的數(shù)據(jù),而消息隊列系統(tǒng)(例如 RocketMQ)負責為流處理應(yīng)用提供數(shù)據(jù)臨時緩沖,發(fā)布 / 訂閱功能,數(shù)據(jù)不進行長時間的持久化保留。兩者無法整合也是目前 Kappa 架構(gòu)對歷史數(shù)據(jù)處理能力有限的原因。
Pravega 設(shè)計宗旨是成為流的實時存儲解決方案。應(yīng)用程序?qū)?shù)據(jù)持久化存儲到 Pravega 中,Pravega 的 Stream 可以有***制的數(shù)量并且持久化存儲任意長時間,使用同樣的 Reader API 提供尾讀 (tail read) 和追趕讀 (catch-up read) 功能,能夠有效滿足兩種處理方式的統(tǒng)一。
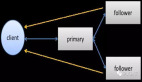
Pravega 支持僅一次處理 (exactly-once),可在 Kappa 架構(gòu)上實現(xiàn)鏈接應(yīng)用需求,以便將計算拆分為多個獨立的應(yīng)用程序,這就是流式系統(tǒng)的微服務(wù)架構(gòu)。我們所設(shè)想的架構(gòu)是由事件驅(qū)動、連續(xù)和有狀態(tài)的數(shù)據(jù)處理的流式存儲 - 計算的模式(如圖 2)。
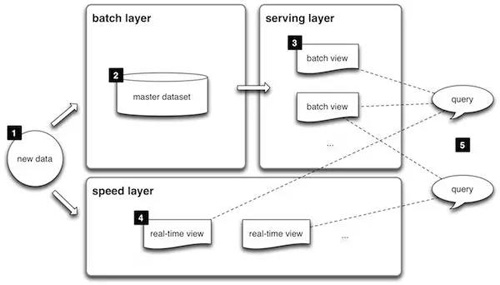
圖 2: 流處理的簡單生命周期
通過將 Pravega 流存儲與 Apache Flink 有狀態(tài)流處理器相結(jié)合,圖 2 中的所有寫、處理、讀和存儲都是獨立的、彈性的,并可以根據(jù)到達數(shù)據(jù)量進行實時動態(tài)擴展。這使我們所有人都能構(gòu)建以前無法構(gòu)建的流式應(yīng)用,并將其從測試原型無縫擴展到生產(chǎn)環(huán)境。擁有了 Pravega,Kappa 架構(gòu)得以湊齊了***的拼圖,形成了統(tǒng)一存儲、統(tǒng)一計算的閉環(huán)。
流式存儲的要求
我們使用的組件需要為它而設(shè)計,以滿足我們想實現(xiàn)的需求,不然就會像現(xiàn)今的大數(shù)據(jù)架構(gòu)那樣,形成復(fù)雜性的堆砌。上述內(nèi)容已經(jīng)提到,現(xiàn)有的存儲引擎同時無法滿足兩種數(shù)據(jù)讀取的需求。結(jié)合實際的應(yīng)用場景,總結(jié)所需要的特性,企業(yè)級流存儲引擎的實現(xiàn)相當有難度,因為它需要三種看似矛盾的系統(tǒng)功能:
- 能夠?qū)?shù)據(jù)視為連續(xù)和***的,而不是有限和靜態(tài)的
- 能夠通過自動彈性伸縮數(shù)據(jù)采集、存儲和處理能力,與負載保持協(xié)調(diào)一致,持續(xù)快速地交付結(jié)果
- 即使在延遲到達或出現(xiàn)亂序數(shù)據(jù)的情況下,也能連續(xù)交付準確的處理結(jié)果
讓我們具體深入上述特征,以當今業(yè)界應(yīng)用最廣的分布式消息系統(tǒng) Apache Kafka 作為對比,看看 Pravega 如何以今天存儲無法實現(xiàn)的方式實現(xiàn)它們。
將數(shù)據(jù)視為連續(xù)和***的
Kafka 源于 LinkedIn 的日志采集系統(tǒng),采用分布式事務(wù)日志架構(gòu)進行持久化層的管理。因此,Kafka 采用添加到文件的末尾并跟蹤其內(nèi)容的方式模擬連續(xù)和***的數(shù)據(jù)流。然而文件既沒有針對此模式進行優(yōu)化,也受限于本地文件系統(tǒng)的文件描述符以及磁盤容量,因此并非是***的。對于數(shù)據(jù)的可靠性,Kafka 使用同步副本(in-sync replica)方式進行,占用了更多的存儲的同時也意味著對吞吐率性能的受損。并且它們利用消息頭部的 header 記錄元數(shù)據(jù)以構(gòu)造數(shù)據(jù)結(jié)構(gòu),使得它們不像字節(jié)序列那樣通用。
將這些想法拼接在一起, 我們提出了 Pravega 將從數(shù)據(jù)的角度支持的連續(xù)和***的特點:
- Pravega 的 Stream 是一個命名的、持久的、僅追加的、***的字節(jié)序列
- 使用低延遲追加尾寫并從序列的尾讀 (tail read/write)
- 具有來自序列較舊部分的高吞吐追趕讀 (catch-up read)
基于負載的自動 (zero-touch) 彈性伸縮特性 (scale up/scale down)
Kafka 通過將數(shù)據(jù)拆分為分區(qū),并獨立處理來獲得并行性。這種做法由來已久,Hadoop 就使用了分區(qū)在 HDFS 和 MapReduce 實現(xiàn)了并行化的批處理。對于流式工作負載,傳統(tǒng)的分區(qū)有著很大的問題:分區(qū)會同時影響讀客戶端和寫客戶端。連續(xù)處理的讀寫操作所要求的并行程度通常各不相同,使其鏈接固定數(shù)量的分區(qū)就會增加實現(xiàn)復(fù)雜性。雖然可以添加分區(qū)以進行擴展,但這需要手動更新寫客戶端、讀客戶端和存儲。代價高昂,也并非動態(tài)縮放。
Pravega,專為動態(tài)和獨立擴展而設(shè)計,支持:
- 許多寫客戶端同時追加寫不相交的數(shù)據(jù)子集
- 寫入數(shù)據(jù)依靠路由鍵 (routing key) 寫入不同的 segment 以保證隔離性
- 讓應(yīng)用程序為寫客戶端分配鍵
- 當鍵空間或?qū)懣蛻舳税l(fā)生改變時,對應(yīng)的存儲不能有約束和改變
- 許多讀客戶端同時處理不相交的數(shù)據(jù)子集
- 讀取的數(shù)據(jù)分區(qū)不依賴于寫入分區(qū)
- 讀取的分區(qū)由存儲策略控制
- 使用 segment 概念代替物理的分區(qū),且數(shù)量根據(jù)攝取流量進行自動連續(xù)的更新
連續(xù)處理數(shù)據(jù)生成準確的結(jié)果
連續(xù)計算要得到準確的結(jié)果需要僅一次處理 (exactly-once)。而僅一次處理語義對數(shù)據(jù)存儲有著明確的要求,數(shù)據(jù)寫入必須是:
- 持久化的
- 有序的
- 一致的
- 事務(wù)性的
這些關(guān)鍵屬性也是存儲系統(tǒng)設(shè)計中最困難的部分。如果沒有事先的設(shè)計考慮,后期就只能通過系統(tǒng)重構(gòu)來完成這些特性。
持久性意味著一旦寫入得到確認,即使遇到組件故障數(shù)據(jù)也不會丟失。持久性由于與失敗后數(shù)據(jù)重放相關(guān)因而至關(guān)重要。沒有持久化的系統(tǒng)意味著數(shù)據(jù)需要開發(fā)人員進行手動歸檔,將***副本存儲在歸檔系統(tǒng)(通常是 HDFS)中。Pravega 流式存儲通過數(shù)據(jù)寫入可持久化的分層存儲保證持久性,用戶能夠***可靠地保存流數(shù)據(jù)。
有序性意味著讀客戶端將按照寫入的順序處理數(shù)據(jù),Kafka 保證了消費者組內(nèi)部是有序的。對于 Pravega 這樣的通過路由鍵 (routing key) 來實現(xiàn)分區(qū)的系統(tǒng)而言,有序僅對具有相同鍵的數(shù)據(jù)有意義。例如擁有數(shù)百萬傳感器的物聯(lián)網(wǎng)系統(tǒng)中,sensor-ID.metric 可能作為鍵,Pravega 的 Stream 能夠保證讀取該傳感器的數(shù)據(jù)將按其寫入的順序進行。對于使用增量更新計算的聚合函數(shù)之類的應(yīng)用,有序性是必不可少的。
一致性意味著即使面對組件故障,而且無論是從流的尾讀還是追趕讀,所有讀客戶端都會看到給定鍵的相同的有序數(shù)據(jù)視圖。與持久性一樣,Pravega 的一致性僅依靠存儲系統(tǒng)的一致性是不夠的。對 Pravega 而言,寫客戶端的寫入操作是冪等的,而寫入的數(shù)據(jù)對于 Pravega 而言也是不透明的(無法再次進行修改),我們以此實現(xiàn)了強一致性。我們基于 Pravega 的強一致性還抽象出了狀態(tài)同步器的 API,用戶可以在此之上構(gòu)建輕量級的其它分布式系統(tǒng)的狀態(tài)同步。
事務(wù)性寫入對于跨鏈接的應(yīng)用程序一次完全正確是必要的。不僅 Pravega 本身支持事務(wù)性的寫入,更和 Apache Flink 的 Sink 集成,在 Flink 檢查點之間建立事務(wù),通過分布式兩階段提交協(xié)議支持端到端的事務(wù)和僅一次處理。
參 考
官網(wǎng):http://pravega.io
GitHub 鏈接:https://github.com/pravega/pravega/
http://blog.pravega.io/2017/04/09/storage-reimagined-for-a-streaming-world/
http://blog.pravega.io/2017/12/14/i-have-a-stream/
作者介紹滕昱: 就職于 DellEMC 非結(jié)構(gòu)化數(shù)據(jù)存儲部門 (Unstructured Data Storage) 團隊并擔任軟件開發(fā)總監(jiān)。2007 年加入 DellEMC 以后一直專注于分布式存儲領(lǐng)域。參加并領(lǐng)導(dǎo)了中國研發(fā)團隊參與兩代 DellEMC 對象存儲產(chǎn)品的研發(fā)工作并取得商業(yè)上成功。從 2017 年開始,兼任 Streaming 存儲和實時計算系統(tǒng)的設(shè)計開發(fā)工作。
周煜敏:復(fù)旦大學(xué)計算機專業(yè)研究生,從本科起就參與 DellEMC 分布式對象存儲的實習(xí)工作。現(xiàn)參與 Flink 相關(guān)領(lǐng)域研發(fā)工作。