













人臉識(shí)別技術(shù)總結(jié):從傳統(tǒng)方法到深度學(xué)習(xí)
自七十年代以來(lái),人臉識(shí)別已經(jīng)成為了計(jì)算機(jī)視覺(jué)和生物識(shí)別領(lǐng)域被研究最多的主題之一。基于人工設(shè)計(jì)的特征和傳統(tǒng)機(jī)器學(xué)習(xí)技術(shù)的傳統(tǒng)方法近來(lái)已被使用非常大型的數(shù)據(jù)集訓(xùn)練的深度神經(jīng)網(wǎng)絡(luò)取代。在這篇論文中,我們對(duì)流行的人臉識(shí)別方法進(jìn)行了全面且***的文獻(xiàn)總結(jié),其中既包括傳統(tǒng)方法(基于幾何的方法、整體方法、基于特征的方法和混合方法),也有深度學(xué)習(xí)方法。
引言
人臉識(shí)別是指能夠識(shí)別或驗(yàn)證圖像或視頻中的主體的身份的技術(shù)。***人臉識(shí)別算法誕生于七十年代初 [1,2]。自那以后,它們的準(zhǔn)確度已經(jīng)大幅提升,現(xiàn)在相比于指紋或虹膜識(shí)別 [3] 等傳統(tǒng)上被認(rèn)為更加穩(wěn)健的生物識(shí)別方法,人們往往更偏愛(ài)人臉識(shí)別。讓人臉識(shí)別比其它生物識(shí)別方法更受歡迎的一大不同之處是人臉識(shí)別本質(zhì)上是非侵入性的。比如,指紋識(shí)別需要用戶將手指按在傳感器上,虹膜識(shí)別需要用戶與相機(jī)靠得很近,語(yǔ)音識(shí)別則需要用戶大聲說(shuō)話。相對(duì)而言,現(xiàn)代人臉識(shí)別系統(tǒng)僅需要用戶處于相機(jī)的視野內(nèi)(假設(shè)他們與相機(jī)的距離也合理)。這使得人臉識(shí)別成為了對(duì)用戶最友好的生物識(shí)別方法。這也意味著人臉識(shí)別的潛在應(yīng)用范圍更廣,因?yàn)樗部杀徊渴鹪谟脩舨黄谕c系統(tǒng)合作的環(huán)境中,比如監(jiān)控系統(tǒng)中。人臉識(shí)別的其它常見(jiàn)應(yīng)用還包括訪問(wèn)控制、欺詐檢測(cè)、身份認(rèn)證和社交媒體。
當(dāng)被部署在無(wú)約束條件的環(huán)境中時(shí),由于人臉圖像在現(xiàn)實(shí)世界中的呈現(xiàn)具有高度的可變性(這類人臉圖像通常被稱為自然人臉(faces in-the-wild)),所以人臉識(shí)別也是最有挑戰(zhàn)性的生物識(shí)別方法之一。人臉圖像可變的地方包括頭部姿勢(shì)、年齡、遮擋、光照條件和人臉表情。圖 1 給出了這些情況的示例。

圖 1:在自然人臉圖像中找到的典型變化。(a)頭部姿勢(shì),(b)年齡,(c)光照,(d)面部表情,(e)遮擋。
人臉識(shí)別技術(shù)這些年已經(jīng)發(fā)生了重大的變化。傳統(tǒng)方法依賴于人工設(shè)計(jì)的特征(比如邊和紋理描述量)與機(jī)器學(xué)習(xí)技術(shù)(比如主成分分析、線性判別分析或支持向量機(jī))的組合。人工設(shè)計(jì)在無(wú)約束環(huán)境中對(duì)不同變化情況穩(wěn)健的特征是很困難的,這使得過(guò)去的研究者側(cè)重研究針對(duì)每種變化類型的專用方法,比如能應(yīng)對(duì)不同年齡的方法 [4,5]、能應(yīng)對(duì)不同姿勢(shì)的方法 [6]、能應(yīng)對(duì)不同光照條件的方法 [7,8] 等。近段時(shí)間,傳統(tǒng)的人臉識(shí)別方法已經(jīng)被基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的深度學(xué)習(xí)方法接替。深度學(xué)習(xí)方法的主要優(yōu)勢(shì)是它們可用非常大型的數(shù)據(jù)集進(jìn)行訓(xùn)練,從而學(xué)習(xí)到表征這些數(shù)據(jù)的***特征。網(wǎng)絡(luò)上可用的大量自然人臉圖像已讓研究者可收集到大規(guī)模的人臉數(shù)據(jù)集 [9-15],這些圖像包含了真實(shí)世界中的各種變化情況。使用這些數(shù)據(jù)集訓(xùn)練的基于 CNN 的人臉識(shí)別方法已經(jīng)實(shí)現(xiàn)了非常高的準(zhǔn)確度,因?yàn)樗鼈兡軌驅(qū)W到人臉圖像中穩(wěn)健的特征,從而能夠應(yīng)對(duì)在訓(xùn)練過(guò)程中使用的人臉圖像所呈現(xiàn)出的真實(shí)世界變化情況。此外,深度學(xué)習(xí)方法在計(jì)算機(jī)視覺(jué)方面的不斷普及也在加速人臉識(shí)別研究的發(fā)展,因?yàn)?CNN 也正被用于解決許多其它計(jì)算機(jī)視覺(jué)任務(wù),比如目標(biāo)檢測(cè)和識(shí)別、分割、光學(xué)字符識(shí)別、面部表情分析、年齡估計(jì)等。
人臉識(shí)別系統(tǒng)通常由以下構(gòu)建模塊組成:
- 人臉檢測(cè)。人臉檢測(cè)器用于尋找圖像中人臉的位置,如果有人臉,就返回包含每張人臉的邊界框的坐標(biāo)。如圖 3a 所示。
- 人臉對(duì)齊。人臉對(duì)齊的目標(biāo)是使用一組位于圖像中固定位置的參考點(diǎn)來(lái)縮放和裁剪人臉圖像。這個(gè)過(guò)程通常需要使用一個(gè)特征點(diǎn)檢測(cè)器來(lái)尋找一組人臉特征點(diǎn),在簡(jiǎn)單的 2D 對(duì)齊情況中,即為尋找最適合參考點(diǎn)的***仿射變換。圖 3b 和 3c 展示了兩張使用了同一組參考點(diǎn)對(duì)齊后的人臉圖像。更復(fù)雜的 3D 對(duì)齊算法(如 [16])還能實(shí)現(xiàn)人臉正面化,即將人臉的姿勢(shì)調(diào)整到正面向前。
- 人臉表征。在人臉表征階段,人臉圖像的像素值會(huì)被轉(zhuǎn)換成緊湊且可判別的特征向量,這也被稱為模板(template)。理想情況下,同一個(gè)主體的所有人臉都應(yīng)該映射到相似的特征向量。
- 人臉匹配。在人臉匹配構(gòu)建模塊中,兩個(gè)模板會(huì)進(jìn)行比較,從而得到一個(gè)相似度分?jǐn)?shù),該分?jǐn)?shù)給出了兩者屬于同一個(gè)主體的可能性。

圖 2:人臉識(shí)別的構(gòu)建模塊。
很多人認(rèn)為人臉表征是人臉識(shí)別系統(tǒng)中最重要的組件,這也是本論文第二節(jié)所關(guān)注的重點(diǎn)。

圖 3:(a)人臉檢測(cè)器找到的邊界框。(b)和(c):對(duì)齊后的人臉和參考點(diǎn)。
深度學(xué)習(xí)方法
卷積神經(jīng)網(wǎng)絡(luò)(CNN)是人臉識(shí)別方面最常用的一類深度學(xué)習(xí)方法。深度學(xué)習(xí)方法的主要優(yōu)勢(shì)是可用大量數(shù)據(jù)來(lái)訓(xùn)練,從而學(xué)到對(duì)訓(xùn)練數(shù)據(jù)中出現(xiàn)的變化情況穩(wěn)健的人臉表征。這種方法不需要設(shè)計(jì)對(duì)不同類型的類內(nèi)差異(比如光照、姿勢(shì)、面部表情、年齡等)穩(wěn)健的特定特征,而是可以從訓(xùn)練數(shù)據(jù)中學(xué)到它們。深度學(xué)習(xí)方法的主要短板是它們需要使用非常大的數(shù)據(jù)集來(lái)訓(xùn)練,而且這些數(shù)據(jù)集中需要包含足夠的變化,從而可以泛化到未曾見(jiàn)過(guò)的樣本上。幸運(yùn)的是,一些包含自然人臉圖像的大規(guī)模人臉數(shù)據(jù)集已被公開(kāi) [9-15],可被用來(lái)訓(xùn)練 CNN 模型。除了學(xué)習(xí)判別特征,神經(jīng)網(wǎng)絡(luò)還可以降維,并可被訓(xùn)練成分類器或使用度量學(xué)習(xí)方法。CNN 被認(rèn)為是端到端可訓(xùn)練的系統(tǒng),無(wú)需與任何其它特定方法結(jié)合。
用于人臉識(shí)別的 CNN 模型可以使用不同的方法來(lái)訓(xùn)練。其中之一是將該問(wèn)題當(dāng)作是一個(gè)分類問(wèn)題,訓(xùn)練集中的每個(gè)主體都對(duì)應(yīng)一個(gè)類別。訓(xùn)練完之后,可以通過(guò)去除分類層并將之前層的特征用作人臉表征而將該模型用于識(shí)別不存在于訓(xùn)練集中的主體 [99]。在深度學(xué)習(xí)文獻(xiàn)中,這些特征通常被稱為瓶頸特征(bottleneck features)。在這***個(gè)訓(xùn)練階段之后,該模型可以使用其它技術(shù)來(lái)進(jìn)一步訓(xùn)練,以為目標(biāo)應(yīng)用優(yōu)化瓶頸特征(比如使用聯(lián)合貝葉斯 [9] 或使用一個(gè)不同的損失函數(shù)來(lái)微調(diào)該 CNN 模型 [10])。另一種學(xué)習(xí)人臉表征的常用方法是通過(guò)優(yōu)化配對(duì)的人臉 [100,101] 或人臉三元組 [102] 之間的距離度量來(lái)直接學(xué)習(xí)瓶頸特征。
使用神經(jīng)網(wǎng)絡(luò)來(lái)做人臉識(shí)別并不是什么新思想。1997 年就有研究者為人臉檢測(cè)、眼部定位和人臉識(shí)別提出了一種名為「基于概率決策的神經(jīng)網(wǎng)絡(luò)(PBDNN)」[103] 的早期方法。這種人臉識(shí)別 PDBNN 被分成了每一個(gè)訓(xùn)練主體一個(gè)全連接子網(wǎng)絡(luò),以降低隱藏單元的數(shù)量和避免過(guò)擬合。研究者使用密度和邊特征分別訓(xùn)練了兩個(gè) PBDNN,然后將它們的輸出組合起來(lái)得到最終分類決定。另一種早期方法 [104] 則組合使用了自組織映射(SOM)和卷積神經(jīng)網(wǎng)絡(luò)。自組織映射 [105] 是一類以無(wú)監(jiān)督方式訓(xùn)練的神經(jīng)網(wǎng)絡(luò),可將輸入數(shù)據(jù)映射到更低維的空間,同時(shí)也能保留輸入空間的拓?fù)湫再|(zhì)(即在原始空間中相近的輸入在輸出空間中也相近)。注意,這兩種早期方法都不是以端到端的方式訓(xùn)練的([103] 中使用了邊特征,[104] 中使用了 SOM),而且提出的神經(jīng)網(wǎng)絡(luò)架構(gòu)也都很淺。[100] 中提出了一種端到端的人臉識(shí)別 CNN。這種方法使用了一種孿生式架構(gòu),并使用了一個(gè)對(duì)比損失函數(shù) [106] 來(lái)進(jìn)行訓(xùn)練。這個(gè)對(duì)比損失使用了一種度量學(xué)習(xí)流程,其目標(biāo)是最小化對(duì)應(yīng)同一主體的特征向量對(duì)之間的距離,同時(shí)***化對(duì)應(yīng)不同主體的特征向量對(duì)之間的距離。該方法中使用的 CNN 架構(gòu)也很淺,且訓(xùn)練數(shù)據(jù)集也較小。
上面提到的方法都未能取得突破性的成果,主要原因是使用了能力不足的網(wǎng)絡(luò),且訓(xùn)練時(shí)能用的數(shù)據(jù)集也相對(duì)較小。直到這些模型得到擴(kuò)展并使用大量數(shù)據(jù) [107] 訓(xùn)練后,用于人臉識(shí)別的***深度學(xué)習(xí)方法 [99,9] 才達(dá)到了當(dāng)前***水平。尤其值得一提的是 Facebook 的 DeepFace [99],這是最早的用于人臉識(shí)別的 CNN 方法之一,其使用了一個(gè)能力很強(qiáng)的模型,在 LFW 基準(zhǔn)上實(shí)現(xiàn)了 97.35% 的準(zhǔn)確度,將之前***表現(xiàn)的錯(cuò)誤率降低了 27%。研究者使用 softmax 損失和一個(gè)包含 440 萬(wàn)張人臉(來(lái)自 4030 個(gè)主體)的數(shù)據(jù)集訓(xùn)練了一個(gè) CNN。本論文有兩個(gè)全新的貢獻(xiàn):(1)一個(gè)基于明確的 3D 人臉建模的高效的人臉對(duì)齊系統(tǒng);(2)一個(gè)包含局部連接的層的 CNN 架構(gòu) [108,109],這些層不同于常規(guī)的卷積層,可以從圖像中的每個(gè)區(qū)域?qū)W到不同的特征。在那同時(shí),DeepID 系統(tǒng) [9] 通過(guò)在圖塊(patch)上訓(xùn)練 60 個(gè)不同的 CNN 而得到了相近的結(jié)果,這些圖塊包含十個(gè)區(qū)域、三種比例以及 RGB 或灰度通道。在測(cè)試階段,會(huì)從每個(gè)圖塊提取出 160 個(gè)瓶頸特征,加上其水平翻轉(zhuǎn)后的情況,可形成一個(gè) 19200 維的特征向量(160×2×60)。類似于 [99],新提出的 CNN 架構(gòu)也使用了局部連接的層。其驗(yàn)證結(jié)果是通過(guò)在這種由 CNN 提取出的 19200 維特征向量上訓(xùn)練一個(gè)聯(lián)合貝葉斯分類器 [48] 得到的。訓(xùn)練該系統(tǒng)所使用的數(shù)據(jù)集包含 202599 張人臉圖像,來(lái)自 10177 位名人 [9]。
對(duì)于基于 CNN 的人臉識(shí)別方法,影響準(zhǔn)確度的因素主要有三個(gè):訓(xùn)練數(shù)據(jù)、CNN 架構(gòu)和損失函數(shù)。因?yàn)樵诖蠖鄶?shù)深度學(xué)習(xí)應(yīng)用中,都需要大訓(xùn)練集來(lái)防止過(guò)擬合。一般而言,為分類任務(wù)訓(xùn)練的 CNN 的準(zhǔn)確度會(huì)隨每類的樣本數(shù)量的增長(zhǎng)而提升。這是因?yàn)楫?dāng)類內(nèi)差異更多時(shí),CNN 模型能夠?qū)W習(xí)到更穩(wěn)健的特征。但是,對(duì)于人臉識(shí)別,我們感興趣的是提取出能夠泛化到訓(xùn)練集中未曾出現(xiàn)過(guò)的主體上的特征。因此,用于人臉識(shí)別的數(shù)據(jù)集還需要包含大量主體,這樣模型也能學(xué)習(xí)到更多類間差異。[110] 研究了數(shù)據(jù)集中主體的數(shù)量對(duì)人臉識(shí)別準(zhǔn)確度的影響。在這項(xiàng)研究中,首先以降序形式按照每個(gè)主體的圖像數(shù)量對(duì)一個(gè)大數(shù)據(jù)集進(jìn)行了排序。然后,研究者通過(guò)逐漸增大主體數(shù)量而使用訓(xùn)練數(shù)據(jù)的不同子集訓(xùn)練了一個(gè) CNN。當(dāng)使用了圖像數(shù)量最多的 10000 個(gè)主體進(jìn)行訓(xùn)練時(shí),得到的準(zhǔn)確度是***的。增加更多主體會(huì)降低準(zhǔn)確度,因?yàn)槊總€(gè)額外主體可用的圖像非常少。另一項(xiàng)研究 [111] 研究了更寬度的數(shù)據(jù)集更好,還是更深度的數(shù)據(jù)集更好(如果一個(gè)數(shù)據(jù)集包含更多主體,則認(rèn)為它更寬;類似地,如果每個(gè)主體包含的圖像更多,則認(rèn)為它更深)。這項(xiàng)研究總結(jié)到:如果圖像數(shù)量相等,則更寬的數(shù)據(jù)集能得到更好的準(zhǔn)確度。研究者認(rèn)為這是因?yàn)楦鼘挾鹊臄?shù)據(jù)集包含更多類間差異,因而能更好地泛化到未曾見(jiàn)過(guò)的主體上。表 1 展示了某些最常用于訓(xùn)練人臉識(shí)別 CNN 的公開(kāi)數(shù)據(jù)集。
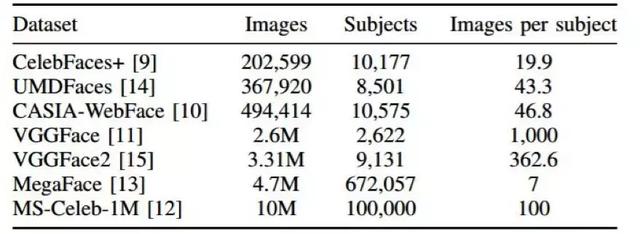
表 1:公開(kāi)的大規(guī)模人臉數(shù)據(jù)集。
用于人臉識(shí)別的 CNN 架構(gòu)從那些在 ImageNet 大規(guī)模視覺(jué)識(shí)別挑戰(zhàn)賽(ILSVRC)上表現(xiàn)優(yōu)異的架構(gòu)上取得了很多靈感。舉個(gè)例子,[11] 中使用了一個(gè)帶有 16 層的 VGG 網(wǎng)絡(luò) [112] 版本,[10] 中則使用了一個(gè)相似但更小的網(wǎng)絡(luò)。[102] 中探索了兩種不同類型的 CNN 架構(gòu):VGG 風(fēng)格的網(wǎng)絡(luò) [112] 和 GoogleNet 風(fēng)格的網(wǎng)絡(luò) [113]。即使這兩種網(wǎng)絡(luò)實(shí)現(xiàn)了相當(dāng)?shù)臏?zhǔn)確度,但 GoogleNet 風(fēng)格的網(wǎng)絡(luò)的參數(shù)數(shù)量少 20 倍。更近段時(shí)間,殘差網(wǎng)絡(luò)(ResNet)[114] 已經(jīng)成為了很多目標(biāo)識(shí)別任務(wù)的最受偏愛(ài)的選擇,其中包括人臉識(shí)別 [115-121]。ResNet 的主要?jiǎng)?chuàng)新點(diǎn)是引入了一種使用捷徑連接的構(gòu)建模塊來(lái)學(xué)習(xí)殘差映射,如圖 7 所示。捷徑連接的使用能讓研究者訓(xùn)練更深度的架構(gòu),因?yàn)樗鼈冇兄诳鐚拥男畔⒘鲃?dòng)。[121] 對(duì)不同的 CNN 架構(gòu)進(jìn)行了全面的研究。在準(zhǔn)確度、速度和模型大小之間的***權(quán)衡是使用帶有一個(gè)殘差模塊(類似于 [122] 中提出的那種)的 100 層 ResNet 得到的。
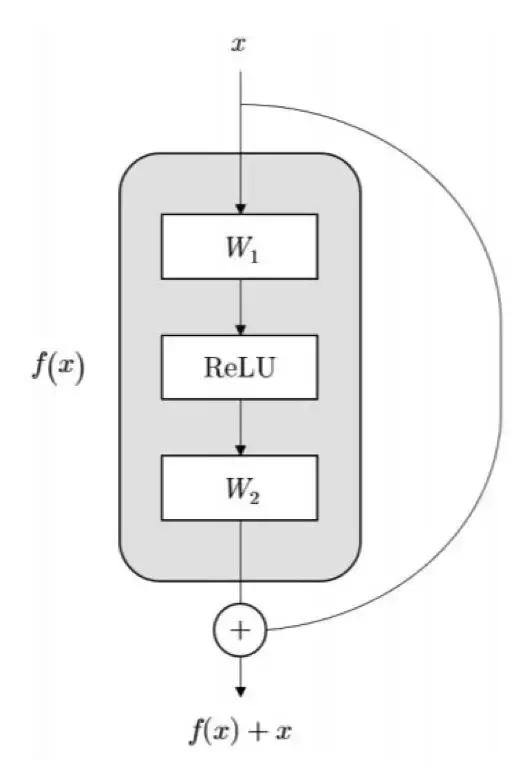
圖 7:[114] 中提出的原始的殘差模塊。
選擇用于訓(xùn)練 CNN 方法的損失函數(shù)已經(jīng)成為近來(lái)人臉識(shí)別最活躍的研究領(lǐng)域。即使使用 softmax 損失訓(xùn)練的 CNN 已經(jīng)非常成功 [99,9,10,123],但也有研究者認(rèn)為使用這種損失函數(shù)無(wú)法很好地泛化到訓(xùn)練集中未出現(xiàn)過(guò)的主體上。這是因?yàn)?softmax 損失有助于學(xué)習(xí)能增大類間差異的特征(以便在訓(xùn)練集中區(qū)別不同的類),但不一定會(huì)降低類內(nèi)差異。研究者已經(jīng)提出了一些能緩解這一問(wèn)題的方法。優(yōu)化瓶頸特征的一種簡(jiǎn)單方法是使用判別式子空間方法,比如聯(lián)合貝葉斯 [48],就像 [9,124,125,126,10,127] 中所做的那樣。另一種方法是使用度量學(xué)習(xí)。比如,[100,101] 中使用了配對(duì)的對(duì)比損失來(lái)作為唯一的監(jiān)督信號(hào),[124-126] 中還結(jié)合使用了分類損失。人臉識(shí)別方面最常用的度量學(xué)習(xí)方法是三元組損失函數(shù) [128],最早在 [102] 中被用于人臉識(shí)別任務(wù)。三元組損失的目標(biāo)是以一定余量分開(kāi)正例對(duì)之間的距離和負(fù)例對(duì)之間的距離。從數(shù)學(xué)形式上講,對(duì)于每個(gè)三元組 i,需要滿足以下條件 [102]:
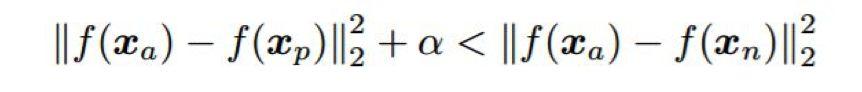
其中 x_a 是錨圖像,x_p 是同一主體的圖像,x_n 是另一個(gè)不同主體的圖像,f 是模型學(xué)習(xí)到的映射關(guān)系,α 施加在正例對(duì)和負(fù)例對(duì)距離之間的余量。在實(shí)踐中,使用三元組損失訓(xùn)練的 CNN 的收斂速度比使用 softmax 的慢,這是因?yàn)樾枰罅咳M(或?qū)Ρ葥p失中的配對(duì))才能覆蓋整個(gè)訓(xùn)練集。盡管這個(gè)問(wèn)題可以通過(guò)在訓(xùn)練階段選擇困難的三元組(即違反余量條件的三元組)來(lái)緩解 [102],但常見(jiàn)的做法是在***個(gè)訓(xùn)練階段使用 softmax 損失訓(xùn)練,在第二個(gè)訓(xùn)練階段使用三元組損失來(lái)對(duì)瓶頸特征進(jìn)行調(diào)整 [11,129,130]。研究者們已經(jīng)提出了三元組損失的一些變體。比如 [129] 中使用了點(diǎn)積作為相似度度量,而不是歐幾里德距離;[130] 中提出了一種概率式三元組損失;[131,132] 中提出了一種修改版的三元組損失,它也能最小化正例和負(fù)例分?jǐn)?shù)分布的標(biāo)準(zhǔn)差。用于學(xué)習(xí)判別特征的另一種損失函數(shù)是 [133] 中提出的中心損失(centre loss)。中心損失的目標(biāo)是最小化瓶頸特征與它們對(duì)應(yīng)類別的中心之間的距離。通過(guò)使用 softmax 損失和中心損失進(jìn)行聯(lián)合訓(xùn)練,結(jié)果表明 CNN 學(xué)習(xí)到的特征能夠有效增大類間差異(softmax 損失)和降低類內(nèi)個(gè)體差異(中心損失)。相比于對(duì)比損失和三元組損失,中心損失的優(yōu)點(diǎn)是更高效和更容易實(shí)現(xiàn),因?yàn)樗恍枰谟?xùn)練過(guò)程中構(gòu)建配對(duì)或三元組。另一種相關(guān)的度量學(xué)習(xí)方法是 [134] 中提出的范圍損失(range loss),這是為改善使用不平衡數(shù)據(jù)集的訓(xùn)練而提出的。范圍損失有兩個(gè)組件。類內(nèi)的損失組件是最小化同一類樣本之間的 k-***距離,而類間的損失組件是***化每個(gè)訓(xùn)練批中最近的兩個(gè)類中心之間的距離。通過(guò)使用這些極端案例,范圍損失為每個(gè)類都使用同樣的信息,而不管每個(gè)類別中有多少樣本可用。類似于中心損失,范圍損失需要與 softmax 損失結(jié)合起來(lái)以避免損失降至零 [133]。
當(dāng)結(jié)合不同的損失函數(shù)時(shí),會(huì)出現(xiàn)一個(gè)困難,即尋找每一項(xiàng)之間的正確平衡。最近一段時(shí)間,已有研究者提出了幾種修改 softmax 損失的方法,這樣它無(wú)需與其它損失結(jié)合也能學(xué)習(xí)判別特征。一種已被證明可以增加瓶頸特征的判別能力的方法是特征歸一化 [115,118]。比如,[115] 提出歸一化特征以具有單位 L2 范數(shù),[118] 提出歸一化特征以具有零均值和單位方差。一個(gè)成功的方法已經(jīng)在 softmax 損失中每類之間的決策邊界中引入了一個(gè)余量 [135]。為了簡(jiǎn)單,我們介紹一下使用 softmax 損失進(jìn)行二元分類的情況。在這種情況下,每類之間的決策邊界(如果偏置為零)可由下式給定:
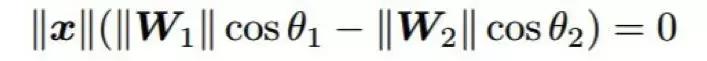
其中 x 是特征向量,W_1 和 W_2 是對(duì)應(yīng)每類的權(quán)重,θ_1 和 θ_2 是 x 分別與 W_1 和 W_2 之間的角度。通過(guò)在上式中引入一個(gè)乘法余量,這兩個(gè)決策邊界可以變得更加嚴(yán)格:
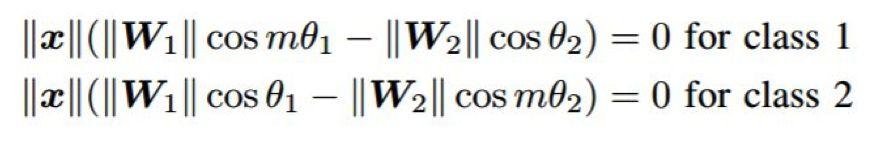
如圖 8 所示,這個(gè)余量可以有效地增大類別之間的區(qū)分程度以及各自類別之內(nèi)的緊湊性。根據(jù)將該余量整合進(jìn)損失的方式,研究者們已經(jīng)提出了多種可用方法 [116,119-121]。比如 [116] 中對(duì)權(quán)重向量進(jìn)行了歸一化以具有單位范數(shù),這樣使得決策邊界僅取決于角度 θ_1 和 θ_2。[119,120] 中則提出了一種加性余弦余量。相比于乘法余量 [135,116],加性余量更容易實(shí)現(xiàn)和優(yōu)化。在這項(xiàng)工作中,除了歸一化權(quán)重向量,特征向量也如 [115] 中一樣進(jìn)行了歸一化和比例調(diào)整。[121] 中提出了另一種加性余量,它既有 [119,120] 那樣的優(yōu)點(diǎn),還有更好的幾何解釋方式,因?yàn)檫@個(gè)余量是加在角度上的,而不是余弦上。表 2 總結(jié)了有余量的 softmax 損失的不同變體的決策邊界。這些方法是人臉識(shí)別領(lǐng)域的當(dāng)前***。
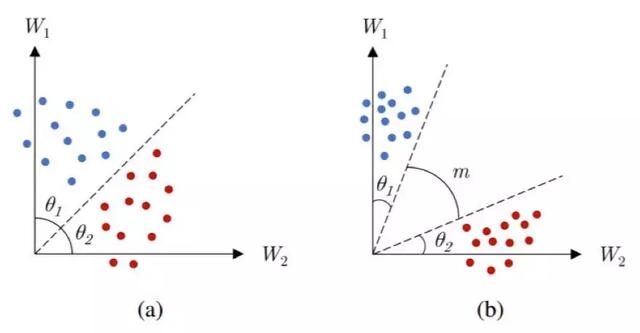
圖 8:在兩個(gè)類別之間的決策邊界中引入一個(gè)余量 m 的效果。(a)softmax 損失,(b)有余量的 softmax 損失。

表 2:有余量的 softmax 損失的不同變體的決策邊界。注意這些決策邊界針對(duì)的是二元分類案例中的類別 1。
【本文是51CTO專欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)譯文,微信公眾號(hào)“機(jī)器之心( id: almosthuman2014)”】





















