













前員工揭內(nèi)幕:10年了,為何谷歌還搞不定知識(shí)圖譜?
本文由微信公眾號(hào) 「AI 前線」原創(chuàng)(ID:ai-front),未經(jīng)授權(quán)不得轉(zhuǎn)載。
當(dāng)我向別人解釋我們?cè)?Dgraph 實(shí)驗(yàn)室所做的東西時(shí),經(jīng)常會(huì)有人問我是不是曾經(jīng)在 Facebook 工作過,或者我們正在做的東西是否受到 Facebook 的啟發(fā)。很多人都知道 Facebook 在社交圖服務(wù)方面做了大量工作,因?yàn)樗麄儼l(fā)表了多篇關(guān)于如何構(gòu)建圖基礎(chǔ)設(shè)施的文章。
在說到谷歌時(shí),一般僅限于知識(shí)圖譜服務(wù),但卻沒有人提到過其內(nèi)部基礎(chǔ)設(shè)施是怎么回事。其實(shí)谷歌有專門用于提供知識(shí)圖譜的系統(tǒng)。事實(shí)上,我們(在谷歌的時(shí)候)在圖服務(wù)系統(tǒng)方面也做了大量的工作。早在 2010 年,我就冒險(xiǎn)進(jìn)行了兩次嘗試,看看可以做出些什么東西。
谷歌需要構(gòu)建一個(gè)圖服務(wù)系統(tǒng),不僅可以處理知識(shí)圖數(shù)據(jù)中的復(fù)雜關(guān)系,還可以處理所有可以訪問結(jié)構(gòu)化數(shù)據(jù)的 OneBox。服務(wù)系統(tǒng)需要遍歷事實(shí)數(shù)據(jù),并具備足夠高的吞吐量和足夠低的延遲,以應(yīng)對(duì)大量的 Web 搜索。但沒有現(xiàn)成可用的系統(tǒng)或數(shù)據(jù)庫能夠同時(shí)滿足這三個(gè)要求。
我已經(jīng)回答了為什么谷歌需要構(gòu)建一個(gè)圖服務(wù)系統(tǒng),在本文的其余部分,我將帶你回顧我們構(gòu)建圖服務(wù)系統(tǒng)的整個(gè)旅程。
我是怎么知道這些的?我先自我介紹一下,2006 年到 2013 年期間,我在谷歌工作。先是實(shí)習(xí)生,然后是 Web 搜索基礎(chǔ)設(shè)施的軟件工程師。2010 年,谷歌收購了 Metaweb,那時(shí)我的團(tuán)隊(duì)剛剛推出了 Caffeine。我想做一些與眾不同的東西,于是開始與 Metaweb 的人(在舊金山)合作。我的目標(biāo)是弄清楚如何使用知識(shí)圖譜來改進(jìn) Web 搜索。
Metaweb 的故事之前已經(jīng)說過,谷歌在 2010 年收購了 Metaweb。Metaweb 已經(jīng)使用多種技術(shù)構(gòu)建了一個(gè)高質(zhì)量的知識(shí)圖譜,包括爬取和解析維基百科。所有這些都是由他們內(nèi)部構(gòu)建的一個(gè)圖數(shù)據(jù)庫驅(qū)動(dòng)的,這個(gè)數(shù)據(jù)庫叫作 Graphd——一個(gè)圖守護(hù)程序(現(xiàn)在已經(jīng)發(fā)布在 GitHub 上:https://github.com/google/graphd)。
Graphd 有一些非常典型的屬性。和守護(hù)程序一樣,它運(yùn)行在單臺(tái)服務(wù)器上,所有數(shù)據(jù)都保存在內(nèi)存中。Freebase 網(wǎng)站讓 Graphd 不堪重負(fù),在被收購之后,谷歌面臨的一個(gè)挑戰(zhàn)是如何繼續(xù)運(yùn)營 Freebase。
谷歌在商用硬件和分布式軟件領(lǐng)域建立了一個(gè)帝國。單臺(tái)服務(wù)器數(shù)據(jù)庫永遠(yuǎn)無法支撐與搜索相關(guān)的爬取、索引和服務(wù)工作負(fù)載。谷歌先是推出了 SSTable,然后是 Bigtable,可以橫向擴(kuò)展到數(shù)百甚至數(shù)千臺(tái)機(jī)器,為數(shù) PB 數(shù)據(jù)提供處理能力。他們使用 Borg(K8s 的前身)來配置機(jī)器,使用 Stubby(gRPC 的前身)進(jìn)行通信,通過 Borg 名稱服務(wù)解析 IP 地址(BNS,已集成到 K8s 中),并將數(shù)據(jù)存儲(chǔ)在谷歌文件系統(tǒng)(GFS)上。進(jìn)程可能會(huì)死亡,機(jī)器可能會(huì)崩潰,但系統(tǒng)會(huì)一直運(yùn)轉(zhuǎn)。
Graphd 當(dāng)時(shí)就處在這樣的環(huán)境中。使用單個(gè)數(shù)據(jù)庫為運(yùn)行在單臺(tái)服務(wù)器上的網(wǎng)站提供服務(wù),這種想法與谷歌(包括我自己)的風(fēng)格格格不入。特別是,Graphd 需要 64GB 或更多的內(nèi)存才能運(yùn)行。如果你認(rèn)為這樣的內(nèi)存要求很搞笑,那么請(qǐng)注意,那是在 2010 年。當(dāng)時(shí)大多數(shù)谷歌服務(wù)器的***內(nèi)存為 32GB,所以谷歌必須購買配備足夠多內(nèi)存的特殊機(jī)器來支持 Graphd。
替換 Graphd有關(guān)替換或重寫 Graphd 并讓它支持分布式的想法開始冒了出來,但這對(duì)于圖數(shù)據(jù)庫來說是一件非常困難的事情。它們不像鍵值數(shù)據(jù)庫那樣,可以將一大塊數(shù)據(jù)移動(dòng)到另一臺(tái)服務(wù)器上,在查詢時(shí)提供鍵就可以了。圖數(shù)據(jù)庫承諾的是高效的連接和遍歷,需要以特定的方式來實(shí)現(xiàn)。
其中的一個(gè)想法是使用一個(gè)叫作 MindMeld(IIRC)的項(xiàng)目。這個(gè)項(xiàng)目承諾若通過網(wǎng)絡(luò)硬件可以更快地訪問另一臺(tái)服務(wù)器內(nèi)存。這應(yīng)該比正常的 RPC 要快,快到足以偽復(fù)制內(nèi)存數(shù)據(jù)庫所需的直接內(nèi)存訪問。但這個(gè)想法并沒有走得太遠(yuǎn)。
另一個(gè)想法(實(shí)際上是一個(gè)項(xiàng)目)是構(gòu)建一個(gè)真正的分布式圖服務(wù)系統(tǒng),不僅可以取代 Graphd,還可以為將來的所有知識(shí)提供服務(wù)。它就是 Dgraph——一種分布式圖守護(hù)程序。
Dgraph 實(shí)驗(yàn)室和開源項(xiàng)目 Dgraph 的命名就是從谷歌的這個(gè)項(xiàng)目開始的。
當(dāng)我在本文中提到 Dgraph 時(shí),指的是谷歌的內(nèi)部項(xiàng)目,而不是我們后來構(gòu)建的開源項(xiàng)目。
Cerebro 的故事:一個(gè)知識(shí)引擎雖然我知道 Dgraph 的目標(biāo)是要取代 Graphd,但我的目標(biāo)卻是做出一些東西來改進(jìn) Web 搜索。我在 Metaweb 找到了一位研究工程師 DH,Cubed(https://blog.dgraph.io/refs/freebase-cubed.pdf)就是他開發(fā)的。
谷歌紐約辦公室的一些工程師開發(fā)了 Squared(https://en.wikipedia.org/wiki/Google_Squared)。DH 則更進(jìn)一步,開發(fā)了 Cubed。雖然 Squared 沒有什么用,但 Cubed 卻令人印象深刻。我開始想如何也在谷歌開發(fā)一個(gè)這樣的東西,畢竟谷歌已經(jīng)有一些現(xiàn)成的東西可以利用。
首先是一個(gè)搜索項(xiàng)目,它提供了一種方法,可用于高度準(zhǔn)確地分辨哪些單詞應(yīng)該合在一起。例如,對(duì)于 [tom hanks movies] 這樣的短語,它會(huì)告訴你 [tom] 和 [hanks] 應(yīng)該合在一起。同樣,在 [san francisco weather] 這個(gè)短語中,[san] 和 [francisco] 應(yīng)該合在一起。對(duì)于人類而言,這些都是顯而易見的事情,但對(duì)機(jī)器來說可不是這么回事。
第二個(gè)是理解語法。在查詢 [books by french authors] 時(shí),機(jī)器可以將其解釋成由 [french authors] 所寫的 [books](即法國作家所著的書籍)。但它也可以被解釋成 [authors] 所寫的 [french books](即作家所著的法語書籍)。我使用了斯坦福的詞性(POS)標(biāo)記器來更好地理解語法,并構(gòu)建了語法樹。
第三個(gè)是理解實(shí)體。[french] 可以指很多東西,它可以是指國家(地區(qū))、國籍(法國人)、菜肴(指食物)或語言。我使用了另一個(gè)項(xiàng)目來獲取單詞或短語所對(duì)應(yīng)的實(shí)體列表。
第四個(gè)是理解實(shí)體之間的關(guān)系。現(xiàn)在我已經(jīng)知道如何將單詞關(guān)聯(lián)成短語、短語的執(zhí)行順序,即語法,以及它們對(duì)應(yīng)的實(shí)體,我還需要一種方法來找到這些實(shí)體之間的關(guān)系,以便創(chuàng)建機(jī)器解釋。例如,對(duì)于查詢 [books by french authors],POS 會(huì)告訴我們,它指的是 [french authors] 所著的 [books]。我們有一些 [french] 的實(shí)體和 [authors] 的實(shí)體,算法需要確定如何連接它們。它們可以通過出生地連接在一起,即出生在法國的作家(但可能使用英文寫作),或者是法國藉的作家,或者說法語或使用法語寫作(但可能與法國無關(guān))的作家,或者只是喜歡法國美食的作家。
基于搜索索引的圖系統(tǒng)為了確定某些實(shí)體是否是連接在一起的,以及是如何連接在一起的,我需要一個(gè)圖系統(tǒng)。知識(shí)圖譜數(shù)據(jù)使用了三元組的格式,即每個(gè)事實(shí)通過三個(gè)部分來表示,主語(實(shí)體)、謂詞(關(guān)系)和賓語(另一個(gè)實(shí)體)。查詢必須是 [S P]→[O]、[P O]→[S],有時(shí)候是 [S O]→[P]。
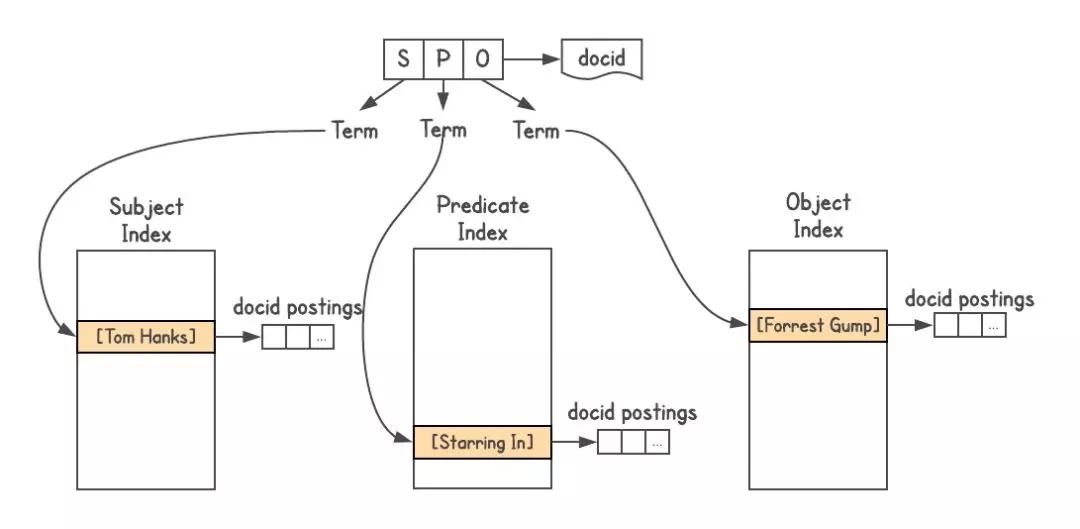
我使用了谷歌的搜索索引系統(tǒng),為每個(gè)三元組分配了一個(gè) docid,并構(gòu)建了三個(gè)索引,分別為 S、P 和 O。另外,索引允許附帶附件,所以我附上了每個(gè)實(shí)體的類型信息。
我構(gòu)建了這個(gè)圖服務(wù)系統(tǒng),知道它有連接深度問題(下面會(huì)解釋),并且不適用于復(fù)雜的圖查詢。事實(shí)上,當(dāng) Metaweb 團(tuán)隊(duì)的某個(gè)人要求我開放系統(tǒng)訪問時(shí),被我拒絕了。
現(xiàn)在,為了確定關(guān)系,我會(huì)執(zhí)行一些查詢,看看會(huì)產(chǎn)生哪些結(jié)果。[french] 和 [author] 會(huì)產(chǎn)生什么結(jié)果嗎?選擇這些結(jié)果,并看看它們?nèi)绾闻c [books] 連接在一起。這樣會(huì)生成多個(gè)機(jī)器解釋。例如,當(dāng)你查詢 [tom hanks movies] 時(shí),它會(huì)生成 [movies directed by tom hanks]、[movies starring tom hanks]、[movies produced by tom hanks] 這樣的解釋,并自動(dòng)拒絕像 [movies named tom hanks] 這樣的解釋。
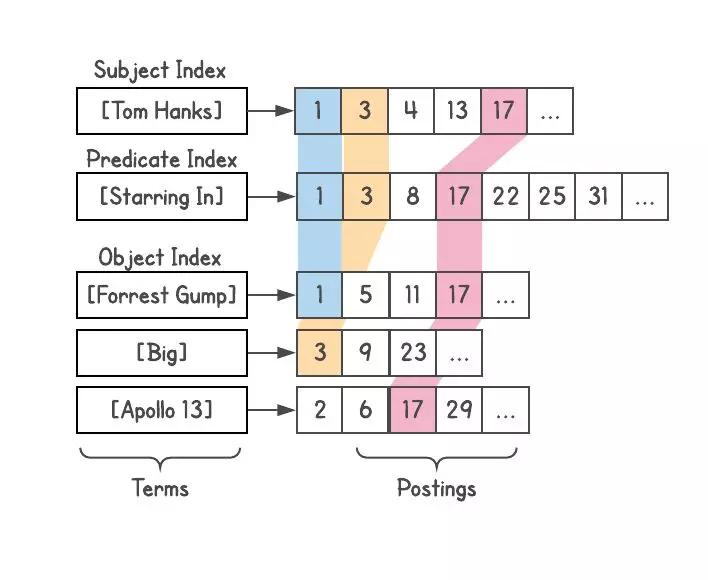
對(duì)于每一個(gè)解釋,它將生成一個(gè)結(jié)果列表——圖中的有效實(shí)體——并且還將返回實(shí)體的類型(存在于附件中)。這個(gè)功能非常強(qiáng)大,因?yàn)樵诹私饬私Y(jié)果的類型后,就可以進(jìn)行過濾、排序或進(jìn)一步擴(kuò)展。對(duì)于電影類型的結(jié)果,你可以按照發(fā)行年份、電影的長度(短片、長片)、語言、獲獎(jiǎng)情況等對(duì)電影進(jìn)行排序。
這個(gè)項(xiàng)目看起來很智能,我們(DH 作為這個(gè)項(xiàng)目的知識(shí)圖譜專家)將它叫作 Cerebro,與《X 戰(zhàn)警》中出現(xiàn)的設(shè)備同名。
Cerebro 經(jīng)常會(huì)展示出一些人們最初沒有搜索過的非常有趣的事實(shí)。例如,如果你搜索 [us presidents],Cerebro 知道總統(tǒng)是人類,而人類會(huì)有身高,你就可以按照身高對(duì)總統(tǒng)進(jìn)行排序,然后會(huì)告訴你 Abraham Lincoln 是美國身高***的總統(tǒng)。還可以通過國籍來過濾搜索結(jié)果。在這個(gè)例子中,它顯示的是美國和英國,因?yàn)槊绹幸晃挥丝偨y(tǒng)——George Washington。(免責(zé)聲明:這個(gè)結(jié)果是基于當(dāng)時(shí)的 KG 狀態(tài),所以不保證這些結(jié)果的正確性。)
藍(lán)色鏈接與知識(shí)圖譜Cerebro 其實(shí)是有可能真正理解用戶的查詢的。如果圖中有數(shù)據(jù),就可以為查詢生成機(jī)器解釋和結(jié)果列表,并根據(jù)對(duì)結(jié)果的理解進(jìn)行進(jìn)一步的探索。如上所述,在知道了正在處理的是電影、人類或書籍之后,就可以啟用特定的過濾和排序功能。還可以遍歷圖的邊來顯示連接數(shù)據(jù),從 [us presidents] 到 [schools they went to],或者 [children they fathered]。DH 在另一個(gè)叫作 Parallax(https://vimeo.com/1513562)的項(xiàng)目中演示了從一個(gè)結(jié)果列表跳轉(zhuǎn)到另一個(gè)結(jié)果列表的能力。
Cerebro 令人印象深刻,Metaweb 的領(lǐng)導(dǎo)層也很支持它。即使是圖服務(wù)部分也提供了較好的性能和功能。我把它叫作知識(shí)引擎(搜索引擎的升級(jí)),但谷歌管理層(包括我的經(jīng)理)對(duì)此并不感興趣。后來,有人告訴我應(yīng)該去找誰溝通這件事,于是我才有機(jī)會(huì)向搜索方面的一位高級(jí)負(fù)責(zé)人展示它。
但得到的回應(yīng)并不是我所希望的那樣。這位負(fù)責(zé)人向我展示了使用谷歌搜索 [books by french authors] 的結(jié)果,其中顯示了十個(gè)藍(lán)色鏈接,并堅(jiān)持說谷歌可以做同樣的事情。此外,他們不希望網(wǎng)站的流量被搶走,因?yàn)槟菢拥脑掃@些網(wǎng)站的所有者肯定會(huì)生氣。
如果你認(rèn)為他是對(duì)的,那么請(qǐng)想一下:谷歌搜索其實(shí)并不能真正理解用戶搜索的是什么。它只會(huì)在正確的相對(duì)位置查找正確的關(guān)鍵字,并對(duì)頁面進(jìn)行排名。盡管它是一個(gè)極其復(fù)雜的系統(tǒng),但仍然不能真正理解搜索或搜索結(jié)果意味著什么。***,用戶還需要自己查看結(jié)果,并從中解析和提取他們需要的信息,并進(jìn)行進(jìn)一步的搜索,然后將完整的結(jié)果組合在一起。
例如,對(duì)于 [books by french authors] 這個(gè)搜索,用戶首先需要對(duì)結(jié)果列表進(jìn)行組合,而這些結(jié)果可能不會(huì)出現(xiàn)在同一個(gè)頁面中。然后按照出版年份對(duì)這些書籍進(jìn)行排序,或者按照出版社等條件進(jìn)行過濾——所有這些都需要進(jìn)行大量的鏈接跟蹤、進(jìn)一步的搜索和手動(dòng)聚合。Cerebro 有可能可以減少這些工作量,讓用戶交互變得簡單而***。
然而,這在當(dāng)時(shí)是一種典型的獲取知識(shí)的方法。管理層不確定知識(shí)圖譜是否真的有用,或者不確定如何將其用在搜索中。對(duì)于一個(gè)已經(jīng)通過向用戶提供大量超鏈接而取得成功的企業(yè)來說,這種獲取知識(shí)的新途徑并不容易理解。
在與管理層磨合了一年之后,我沒有興趣再繼續(xù)下去了。2011 年 6 月,谷歌上海辦公室的一位經(jīng)理找到我,我把項(xiàng)目交給了他。他為這個(gè)項(xiàng)目組建了一個(gè)由 15 名工程師組成的團(tuán)隊(duì)。我在上海呆了一個(gè)星期,把相關(guān)的東西都移交給了這個(gè)團(tuán)隊(duì)的工程師。DH 也參與了這個(gè)項(xiàng)目,并長期指導(dǎo)團(tuán)隊(duì)。
連接深度問題我為 Cerebro 開發(fā)的圖服務(wù)系統(tǒng)存在連接深度問題。當(dāng)一個(gè)查詢的后續(xù)部分需要用到前面部分的結(jié)果時(shí),就需要執(zhí)行連接。典型的連接通常涉及到 SELECT 操作,即對(duì)通用數(shù)據(jù)集進(jìn)行過濾,獲得某些結(jié)果,然后使用這些結(jié)果來過濾數(shù)據(jù)集的另一部分。我將用一個(gè)例子來說明。
假設(shè)你想知道 [people in SF who eat sushi],而且人們已經(jīng)分享了他們的數(shù)據(jù),包括誰住在哪個(gè)城市以及他們喜歡吃哪些食物的信息。
上面的查詢是一個(gè)單級(jí)連接。如果數(shù)據(jù)庫外部的應(yīng)用程序正在執(zhí)行這個(gè)連接,它將先執(zhí)行一個(gè)查詢,然后再執(zhí)行多個(gè)查詢(每個(gè)結(jié)果一個(gè)查詢),找出每個(gè)人都吃些什么,然后挑選出吃壽司的人。
第二步存在扇出(fan-out)問題。如果***步有一百萬個(gè)結(jié)果(基于舊金山人口),那么第二步需要將每個(gè)結(jié)果放入查詢中,找出他們的飲食習(xí)慣,然后進(jìn)行過濾。
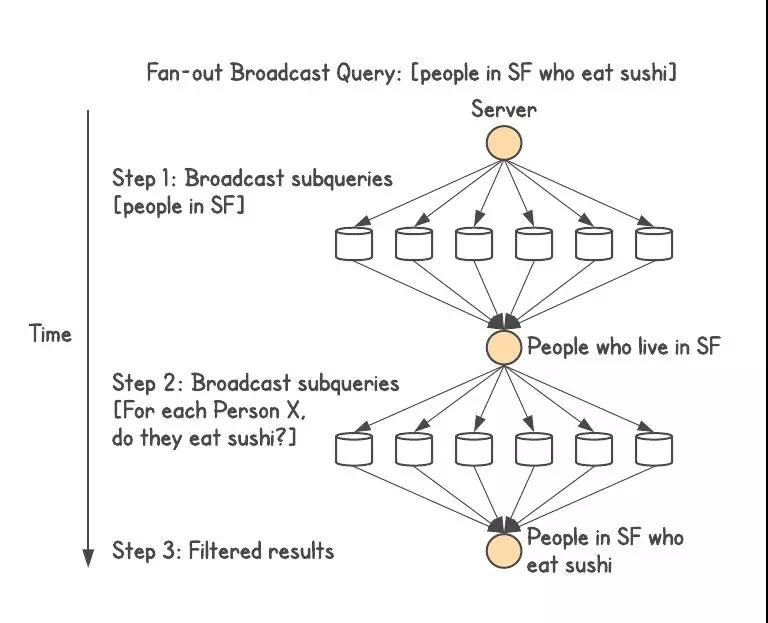
分布式系統(tǒng)工程師通常會(huì)通過廣播來解決這個(gè)問題。他們根據(jù)分片函數(shù)將結(jié)果分成多個(gè)批次,然后查詢集群中的每一臺(tái)服務(wù)器。他們可以通過這種方式實(shí)現(xiàn)連接,但會(huì)導(dǎo)致嚴(yán)重的查詢延遲。
在分布式系統(tǒng)中使用廣播并不是個(gè)好主意。谷歌大牛 Jeff Dean 在他的“Achieving Rapid Response Times in Large Online Services”演講(視頻:https://www.youtube.com/watch?v=1-3Ahy7Fxsc,幻燈片:https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44875.pdf)中很好地解釋了這個(gè)問題。查詢的總延遲總是大于最慢組件的延遲。單臺(tái)機(jī)器的一丁點(diǎn)延遲會(huì)隨著機(jī)器數(shù)量的增多而戲劇性地增加查詢總延遲。
想象一下,有一臺(tái)服務(wù)器,它的 50 百分位延遲為 1 毫秒,99 百分位延遲為 1 秒。如果查詢只涉及一臺(tái)服務(wù)器,那么只有 1%的請(qǐng)求會(huì)占用一秒鐘時(shí)間。但如果查詢涉及 100 臺(tái)服務(wù)器,那么就會(huì)有 63%的請(qǐng)求占用一秒鐘時(shí)間。
因此,廣播會(huì)給查詢延遲帶來不利的影響。如果需要進(jìn)行兩次、三次或更多次的連接,對(duì)于實(shí)時(shí)(OLTP)執(zhí)行來說就會(huì)顯得很慢。
大多數(shù)非原生圖數(shù)據(jù)庫都存在這種高扇出廣播問題,包括 Janus Graph、Twitter 的 FlockDB 和 Facebook 的 TAO。
分布式連接是一個(gè)大難題。現(xiàn)有的原生圖數(shù)據(jù)庫通過將通用數(shù)據(jù)集保存在一臺(tái)機(jī)器(獨(dú)立數(shù)據(jù)庫)上,并在連接時(shí)不訪問其他服務(wù)器來避免這個(gè)問題,如 Neo4j。
Dgraph:任意深度連接在結(jié)束 Cerebro 之后,我擁有了構(gòu)建圖服務(wù)系統(tǒng)的經(jīng)驗(yàn)。隨后,我加入了 Dgraph 項(xiàng)目,成為該項(xiàng)目的三位技術(shù)主管之一。Dgraph 的設(shè)計(jì)理念非常新穎,并解決了連接深度問題。
Dgraph 以一種非常獨(dú)特的方式對(duì)圖數(shù)據(jù)進(jìn)行分片,可以在單臺(tái)機(jī)器上執(zhí)行連接。回到 SPO 這個(gè)問題上,Dgraph 的每個(gè)實(shí)例都將保存與該實(shí)例中的每個(gè)謂詞相對(duì)應(yīng)的所有主語和賓語。Dgraph 實(shí)例將保存多個(gè)謂詞和完整的謂語。
這樣就可以執(zhí)行任意深度的連接,同時(shí)避免了扇出廣播問題。以 [people in SF who eat sushi] 為例,不管集群大小是怎樣的,這個(gè)查詢最多需要兩次網(wǎng)絡(luò)調(diào)用。***次調(diào)用會(huì)找到所有住在舊金山的人,第二次調(diào)用會(huì)將這個(gè)名單與所有吃壽司的人進(jìn)行交集操作。然后我們可以添加更多約束或擴(kuò)展,每個(gè)步驟仍然會(huì)涉及最多一次網(wǎng)絡(luò)調(diào)用。
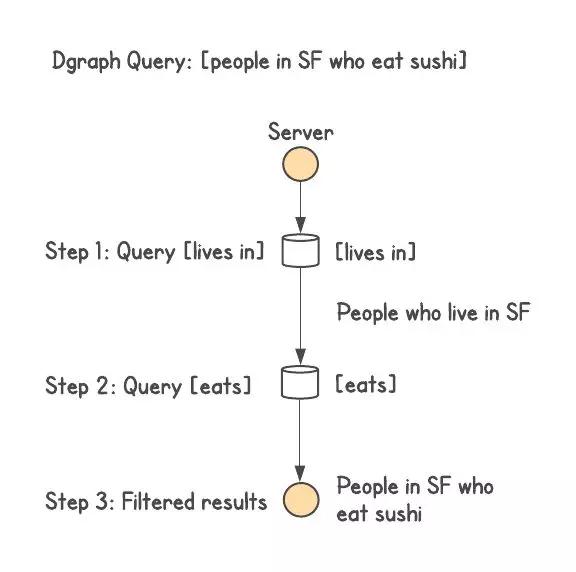
這導(dǎo)致了單臺(tái)服務(wù)器上的謂語會(huì)變得非常大,不過可以通過進(jìn)一步拆分謂語服務(wù)器來解決這個(gè)問題。但是,在最極端的情況下,即所有數(shù)據(jù)只對(duì)應(yīng)一個(gè)謂語,那么基于整個(gè)集群拆分謂語是一種最糟糕的行為。但在其他情況下,基于謂語對(duì)數(shù)據(jù)進(jìn)行分片的設(shè)計(jì)可以在實(shí)際系統(tǒng)中實(shí)現(xiàn)更低的查詢延遲。
分片并不是 Dgraph 的唯一創(chuàng)新。所有的賓語都被分配了一個(gè)整型 ID,然后經(jīng)過排序,保存在倒排列表中,可以與其他倒排列表進(jìn)行快速的交集操作。這樣可以加快連接期間的過濾、查找公共引用等操作。這里還使用了谷歌 Web 服務(wù)系統(tǒng)的一些想法。
通過 Plasma 聯(lián)合 OneBoxe谷歌的 Dgraph 并不是一個(gè)數(shù)據(jù)庫,而是一個(gè)服務(wù)系統(tǒng),相當(dāng)于谷歌的 Web 搜索服務(wù)系統(tǒng)。此外,它需要對(duì)實(shí)時(shí)更新做出響應(yīng)。作為一個(gè)實(shí)時(shí)更新的服務(wù)系統(tǒng),它需要一個(gè)實(shí)時(shí)的圖索引系統(tǒng)。因?yàn)橹皡⑴c過 Caffeine(https://googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html)的工作,所以我在實(shí)時(shí)增量索引系統(tǒng)方面也擁有了很多經(jīng)驗(yàn)。
后來我又啟動(dòng)了一個(gè)新項(xiàng)目,基于這個(gè)圖索引系統(tǒng)將谷歌所有的 OneBox 聯(lián)合在一起,包括天氣、航班、事件,等等。你可能不知道 OneBox 是什么,但你肯定見過它們。OneBox 是單獨(dú)的顯示框,會(huì)在運(yùn)行某些類型的搜索時(shí)出現(xiàn),谷歌可以在這些顯示框中顯示更多的信息。
在開始這個(gè)項(xiàng)目之前,每個(gè) OneBox 由獨(dú)立的后端提供支持,并由不同的團(tuán)隊(duì)負(fù)責(zé)維護(hù)。它們有一組豐富的結(jié)構(gòu)化數(shù)據(jù),但顯示框之間并不會(huì)共享這些數(shù)據(jù)。維護(hù)這些后端不僅涉及大量的工作,而且因?yàn)槿狈χR(shí)共享,限制了谷歌能夠響應(yīng)的查詢類型。
例如,[events in SF] 可以顯示事件,[weather in SF] 可以顯示天氣,但如果 [events in SF] 知道當(dāng)時(shí)在下雨,并且知道事件是在室內(nèi)還是在室外進(jìn)行,那么它就可以根據(jù)天氣(如果下暴雨,看電影或聽交響樂可能是***的選擇)對(duì)事件進(jìn)行過濾(或排序)。
在 Metaweb 團(tuán)隊(duì)的幫助下,我們將所有數(shù)據(jù)轉(zhuǎn)換為 SPO 格式,并在一個(gè)系統(tǒng)中對(duì)其進(jìn)行索引。我將這個(gè)系統(tǒng)命名為 Plasma,一個(gè)用于 Dgraph 的實(shí)時(shí)圖索引系統(tǒng)。
管理層變動(dòng)與 Cerebro 一樣,Plasma 也是一個(gè)缺乏資金支持的項(xiàng)目,但仍在繼續(xù)成長。***,當(dāng)管理層意識(shí)到 OneBoxe 即將使用這個(gè)項(xiàng)目時(shí),他們需要找到“合適的人”負(fù)責(zé)這方面的工作。在這場政治游戲中,我們經(jīng)歷了三次管理層變動(dòng),但他們都沒有這方面的經(jīng)驗(yàn)。
在這次管理層變動(dòng)過程中,支持 Spanner(一個(gè)全球分布式 SQL 數(shù)據(jù)庫,需要 GPS 時(shí)鐘來確保全球一致性)的管理層認(rèn)為 Dgraph 過于復(fù)雜。
***,Dgraph 項(xiàng)目被取消了,不過 Plasma 幸免于難。一個(gè)新團(tuán)隊(duì)接管了這個(gè)項(xiàng)目,這個(gè)團(tuán)隊(duì)的負(fù)責(zé)人直接向***執(zhí)行官匯報(bào)。這個(gè)新團(tuán)隊(duì)(他們其實(shí)對(duì)與圖相關(guān)的問題缺乏了解)決定構(gòu)建一個(gè)基于谷歌現(xiàn)有搜索索引的服務(wù)系統(tǒng)(就像我為 Cerebro 所做的那樣)。我建議使用我為 Cerebro 開發(fā)的那個(gè)系統(tǒng),但被拒絕了。我修改了 Plasma,讓它爬取并將每個(gè)知識(shí)主題擴(kuò)展出幾個(gè)級(jí)別,這個(gè)系統(tǒng)就可以將其視為一個(gè) Web 文檔。他們稱之為 TS(這只是個(gè)縮寫)。
這意味著新的服務(wù)系統(tǒng)將無法執(zhí)行深度連接。我看到很多公司的工程師們?cè)谝婚_始就錯(cuò)誤地認(rèn)為“圖實(shí)際上是一個(gè)很簡單的問題,可以通過在另一個(gè)系統(tǒng)之上構(gòu)建一個(gè)層來解決”。
幾個(gè)月之后,也就是 2013 年 5 月,我離開了谷歌,那個(gè)時(shí)候我在 Dgraph/Plasma 項(xiàng)目上大約已經(jīng)工作了兩年時(shí)間。
后面的故事幾年后,“Web 搜索基礎(chǔ)設(shè)施”被重命為“Web 搜索和知識(shí)圖譜基礎(chǔ)設(shè)施”,之前我向他演示 Cerebro 的那個(gè)人負(fù)責(zé)領(lǐng)導(dǎo)這方面的工作。他們打算使用知識(shí)圖譜替代藍(lán)色鏈接——盡可能為用戶查詢提供最直接的答案。
當(dāng)上海的 Cerebro 團(tuán)隊(duì)即將在生產(chǎn)環(huán)境中部署這個(gè)項(xiàng)目時(shí),項(xiàng)目卻被谷歌紐約辦公室搶走了。***,它改頭換面成了“Knowledge Strip”。如果你搜索 [tom hanks movies],會(huì)在頂部看到它。自***發(fā)布以來,它有了一些改進(jìn),但仍然無法達(dá)到 Cerebro 能夠提供的過濾和排序水平。
參與 Dgraph 工作的三位技術(shù)主管(包括我)最終都離開了谷歌。據(jù)我所知,其他兩位主管現(xiàn)在正在微軟和 LinkedIn 工作。
我獲得了兩次晉升,如果算上當(dāng)時(shí)我以高級(jí)軟件工程師的身份離開谷歌,總共是三次。
當(dāng)前版本的 TS 實(shí)際上非常接近 Cerebro 的設(shè)計(jì),主語、謂語和賓語都有一個(gè)索引。因此,它仍然存在連接深度問題。
此后,Plasma 被重寫和改名,但仍然是一個(gè)支持 TS 的實(shí)時(shí)圖索引系統(tǒng)。它們繼續(xù)托管著谷歌的所有結(jié)構(gòu)化數(shù)據(jù),包括知識(shí)圖譜。
谷歌在深度連接方面的無能為力在很多地方都可以看出來。首先,我們?nèi)匀粵]有看到 OneBoxe 之間的數(shù)據(jù)聯(lián)合:[cities by most rain in asia] 并不會(huì)生成城市列表,盡管天氣和 KG 數(shù)據(jù)是可用的。[events in SF] 無法根據(jù)天氣進(jìn)行過濾,[US presidents] 的結(jié)果不能進(jìn)行進(jìn)一步的排序、過濾或擴(kuò)展。我懷疑這也是他們停止使用 Freebase 的原因之一。
Dgraph:鳳凰涅槃離開谷歌兩年之后,我決定重新開始 Dgraph(https://github.com/dgraph-io/dgraph)。在谷歌之外,我看到了與當(dāng)初類似的情況。這個(gè)領(lǐng)域有很多不成熟的自定義解決方案,他們匆匆茫茫地在關(guān)系型數(shù)據(jù)庫或 NoSQL 數(shù)據(jù)庫之上添加了一個(gè)層,或者將其作為多模型數(shù)據(jù)庫的眾多功能之一。如果存在原生解決方案,會(huì)遇到可伸縮性問題。
在我看來,沒有人能夠在高性能和可伸縮設(shè)計(jì)方面一路走下去。構(gòu)建一個(gè)具備水平可伸縮性、低延遲且可進(jìn)行任意深度連接的圖數(shù)據(jù)庫是一件非常困難的事情。我希望我們?cè)跇?gòu)建 Dgraph 這件事情上不會(huì)走錯(cuò)路。
在過去的三年里,除了我自己的經(jīng)驗(yàn),Dgraph 團(tuán)隊(duì)還在設(shè)計(jì)中加入了大量原創(chuàng)研究,開發(fā)出了這款***的圖數(shù)據(jù)庫。其他公司可以選擇這個(gè)強(qiáng)大、可伸縮且高性能的解決方案,而不是另一個(gè)不成熟的解決方案。
英文原文:
https://blog.dgraph.io/post/why-google-needed-graph-serving-system/























