













數(shù)據(jù)遷移到MySQL的性能測(cè)試
今天對(duì)一套環(huán)境的數(shù)據(jù)從SQL Server遷移到MySQL,中間涉及諸多的架構(gòu)改進(jìn),我們主要說一下數(shù)據(jù)遷移的一些基本思路,以下是一個(gè)開始,會(huì)在后面不斷的迭代改進(jìn)一些方案。
整體來說,遷移的數(shù)據(jù)量聽起來不是很多,大概是300G左右。
整體的步驟是:
1)數(shù)據(jù)從SQL Server導(dǎo)出為csv文件
2)數(shù)據(jù)流轉(zhuǎn)到MySQL中間服務(wù)器上
因?yàn)槲募^大,比如有的文件有幾十G,單次導(dǎo)入會(huì)直接拋錯(cuò),所以需要做下切分,比如按照1000萬的數(shù)據(jù)維度切分。
3)數(shù)據(jù)切分
數(shù)據(jù)會(huì)被切分成相對(duì)規(guī)整的分片,比如按照1000萬的基準(zhǔn),一個(gè)4億數(shù)據(jù)量的文件會(huì)被切分為近40個(gè)500M的文件
4)因?yàn)榍蟹趾蟮奈募啵栽趯?dǎo)入前需要把這些任務(wù)劃分為幾個(gè)組
5)導(dǎo)入的時(shí)候,是按照并發(fā)進(jìn)程的方式,因?yàn)閿?shù)據(jù)庫(kù)后端已經(jīng)做了分片,所以就不需要調(diào)用是開啟太多的線程了。
6)數(shù)據(jù)通過中間件導(dǎo)入,數(shù)據(jù)落盤在多個(gè)分片節(jié)點(diǎn)上,物理分片是4個(gè),每個(gè)物理分片上有4個(gè)邏輯分片,即一共有16個(gè)邏輯分片。
數(shù)據(jù)流程圖如下:
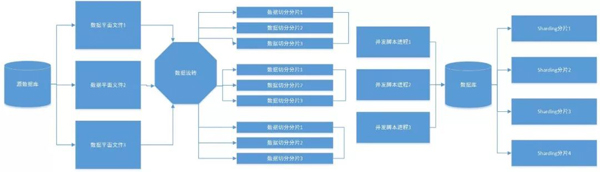
從目前的測(cè)試來看,如果是4個(gè)物理分片,通過中間件使用load data的方式,速度基本在80萬每秒。和單機(jī)的20萬相比,效率和性能是很明顯的。
從目前的數(shù)據(jù)遷移來看,還是存在一些使用風(fēng)險(xiǎn),一來轉(zhuǎn)儲(chǔ)數(shù)據(jù)為csv文件的時(shí)間較長(zhǎng),中間還涉及數(shù)據(jù)流轉(zhuǎn)和數(shù)據(jù)切分,等到數(shù)據(jù)真正導(dǎo)入的時(shí)候,流量和性能的損耗已經(jīng)很高了。
目前的測(cè)試,有些分片節(jié)點(diǎn)的負(fù)載高達(dá)30以上,算是充分利用了服務(wù)器資源。
按照目前的基本數(shù)據(jù)情況,導(dǎo)入近70億數(shù)據(jù)需要2個(gè)小時(shí)左右,而這個(gè)過程還不包括中間環(huán)節(jié)的銜接和數(shù)據(jù)流轉(zhuǎn),實(shí)際的時(shí)間會(huì)在近5個(gè)小時(shí),從數(shù)據(jù)遷移窗口來算,這個(gè)時(shí)間明顯是不符合需求的,如果把時(shí)間控制在1個(gè)小時(shí),有沒有更好的方法?


















