













京東「賣家日志」系統的構建 | 流式計算日志系統應用實踐
引言
本文講述如何去構建一個日志系統,用到了哪些技術?為什么用這些技術?遇到的問題及優化的過程,希望給大家在實踐中提供一些參考。
這是一個有關于日志的項目,負責收集、處理、存儲、查詢京東賣家相關操作的日志,這里就叫它“賣家日志”。在日常的開發過程中,可能對日志這個詞并不陌生,例如常接觸到的Log4j、slf4j等等,這些日志工具通常用來記錄代碼運行的情況,當系統出問題時,可以通過查看日志及時的定位問題所在,從而很快的解決問題。
今天所講的“賣家日志”,與普通的日志有些許的不同,“賣家日志”是用來記錄賣家對系統各個功能的操作情況,例如:張三這個商家對它的店鋪的某款商品進行了價格的修改,就會記錄下一條日志在系統當中,系統中的部分信息是可以提供給商家、運營人員看的,從而讓商家知道自己做了哪些操作,也讓運營人員更好的對商家進行管理。除此之外,也可以幫忙查找從log中找不到的信息,從而幫助開發人員解決問題。接下來就講一下業務場景。
業務場景
有許多的業務系統,如訂單、商品,還有一些其他的系統,之前大家都是各自記錄各自的日志,而且記錄的方式五花八門,格式也獨具一格,這對于商家和運營人員來說是非常頭疼的一件事,沒有給運營人員提供一個可以查詢日志的平臺,每次有問題的時候,只能耗費大半天的時間去找對應的開發團隊,請他們配合找出問題所在,而且有的時候效果也不是很好。
在這么一種情況下,“賣家日志”就誕生了,它給商家和運營以及開發提供了一個統一的日志平臺,所有團隊的日志都可以通過申請權限接入這個平臺,并且運營和商家有問題可以第一時間自己去查找日志解決問題,而不是盲目的找人解決。
日志總體設計
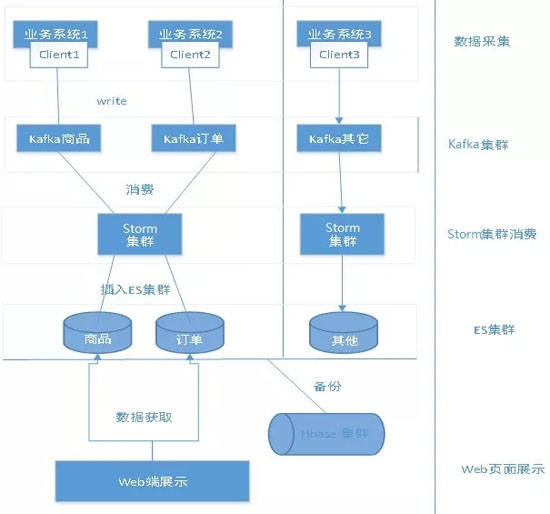
上圖是“賣家日志”系統的整體流程圖,在對于處理日志這一塊業務上,寫了一個日志客戶端提供給各個組調用,還用到了kafka+Strom的流式計算,對于日志查詢這一塊,首先想到了ES,因為ES是一個分布式的文件檢索系統,它可以根據日志的內容提供豐富的檢索功能。而對于冷日志的存儲,用了一個能夠存更大量的工具—HBase,并且也可以根據一些基本的條件進行日志的搜索。
流程:日志客戶端 - Kafka集群 - Strom消費 - ES -HBase - ...
技術點
- Kafka:一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據,說淺顯易懂一點,可以將Kafka理解成為一個消息隊列。
- Storm:Storm是開源的分布式實時大數據處理框架,它是實時的,可以將它理解為一個專門用來處理流式實時數據的東西。
- ElasticSearch:ES是一個基于Lucene的搜索服務器,它是一個分布式的文件檢索系統,它提供了高效的檢索,以及支持多種檢索條件,用起來也十分方便。
- HBase:HBase是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,適用于結構化的存儲,底層依賴于Hadoop的HDFS,利用HBase技術可在廉價PCServer上搭建起大規模結構化存儲集群。
日志客戶端
日志客戶端給各個系統提供了一個統一的API,類似于Log4j這些日志工具,這樣使得接入變得方便簡潔,和平常寫日志沒什么區別。這里需要提到的一個點是客戶端對于日志的處理過程,用下圖來進行說明:
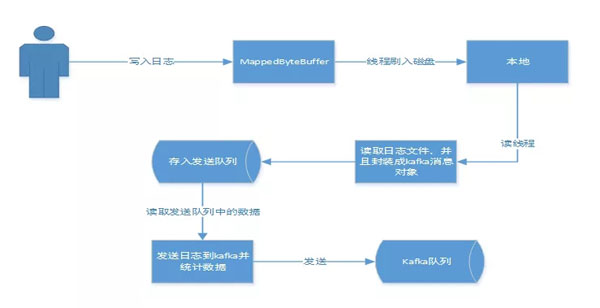
大家可能會疑惑,為什么不直接寫Kafka呢?接下來做個比較,直接寫入本地快,還是寫Kafka快呢?
很明顯,寫入本地快。因為寫日志,想達到的效果是盡量不要影響業務,能夠以更快的方式處理,而對于日志后期的處理,只需要在后臺開啟固定的幾個線程就可以了,這樣既使業務對此無感知,又不浪費資源,除此之外,落盤的方式還為日志數據不丟提供了保障。
此外,這里本地數據的落盤和讀取都用到了NIO的內存映射,寫入和讀取的數據又有了進一步的提升,使得業務日志快速落盤,并且能夠快速的讀取出來發送到Kafka,這也是一個優勢。
為什么要用Kafka
首先介紹一下Kafka,Kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據,可以將Kafka理解成為一個消息隊列。具體的一些細節,大家可以上網搜索。
Kafka主要應用場景:
- 持續的消息:為了從大數據中派生出有用的數據,任何數據的丟失都會影響生成的結果,Kafka提供了一個復雜度為O(1)的磁盤結構存儲數據,即使是對于TB級別的數據都是提供了一個常量時間性能
- 高吞吐量:Kafka采用普通的硬件支持每秒百萬級別的吞吐量
- 分布式:明確支持消息的分區,通過Kafka服務器和消費者機器的集群分布式消費,維持每一個分區是有序的
- 支持多種語言:Java、.net、PHP、ruby、Python
- 實時性:消息被生成者線程生產就能馬上被消費者線程消費,這種特性和事件驅動的系統是相似的
Kafka的優勢:
- 主要用來解決百萬級別的數據中生產者和消費者之間數據傳輸的問題
- 可以將一條數據提供給多個接收這做不同的處理
- 當兩個系統是隔絕的,無法通信的時候,如果想要他們通信就需要重新構建其中的一個工程,而Kafka實現了生產者和消費者之間的無縫對接
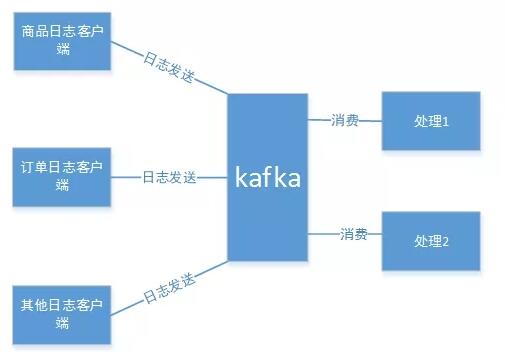
通過上面對Kafka的應用場景和優勢的描述,再去理解“賣家日志”的業務場景,就能理解為什么采用的技術是Kafka了。因為Kafka快,并且適用于流式處理,它可以將突發的量轉換成為平穩的流,以便于Strom的處理。
因為日志是不定時的,就像水流一樣,一直是不斷的,并且不一定是平穩的。而Kafka的一些特性,非常符合“賣家日志”的業務,除此之外,Kafka作為一個高吞吐量的分布式發布訂閱消息系統,可以有多個生產者和消費者,這也為“賣家日志”統一接入和后期的多元化處理提供了強有力的保障。如下圖:
Storm的應用
日志是一個流式的數據,它是不定時的,而且是不平穩的,將這些不定時且不平穩的數據進行處理,用什么方式更好呢?討論后最終采用了Kafka+Storm的方式來處理這些日志數據。
為什么要用Storm呢?Storm是一個免費開源、分布式、高容錯的實時計算系統。Storm令持續不斷的流計算變得容易,Kafka可以將突發的數據轉換成平穩的流,源源不斷的推向Storm,Storm進行消費,處理,最終落庫。Storm處理這一塊的流程,如下圖所示:
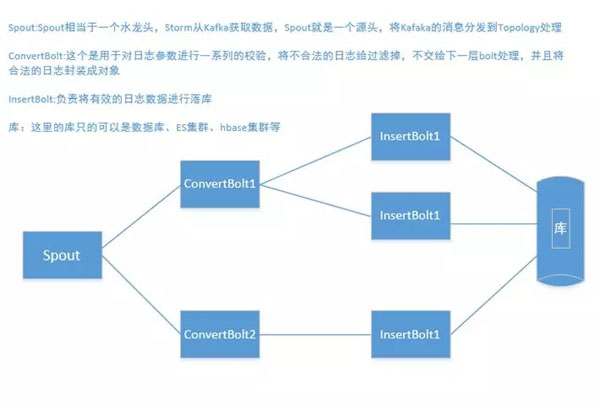
從上圖可以看到,Storm整個處理的流程,其中對日志進行了兩次的處理,一次是校驗是否有效,并且封裝成對象交給下一個bolt,insertBolt負責將數據落庫,這么一個流程看起來比較清晰明了。
關于數據存儲的處理
對于數據的存儲,采用ES對熱數據進行存儲,而對于冷數據,也就是很久之前的數據,采用HBase來進行存儲備份。為什么要這樣做呢?
日志數據使用什么做存儲,直接影響查詢,前期的想法是直接把數據存到能夠抗量HBase上,但是對于多種條件的查詢,HBase顯然不符合要求,所以經過評審,決定用一個分布式檢索的系統來進行存儲,那就是ElasticSearch。
那大家可能會問到:為什么還要用HBase呢?因為ES作為一個檢索的系統,它并不適用于大量的數據的存儲,隨著數據量的增大,ES的查詢性能會慢慢的降低,而日志需要保存的時間是一年,每天的量都是6、7億的數據,所以對于ES來說,很難抗住,不斷的加機器并不是很好的解決辦法。
經過討論,尋求一個更能夠存數據的東西來存很久不用的日志數據,并且能夠提供簡單的檢索,最終選擇了HBase,將最近兩個月的數據放在ES中,給用戶提供多條件的檢索,兩個月之前的數據存放在HBase中,提供簡單的檢索功能,因為兩個多月前的日志也沒有太大的量去查看了。具體的數據流轉如下圖:
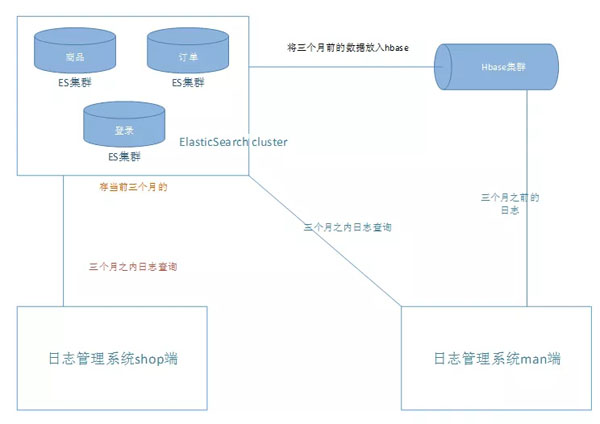
遇到的問題
隨著數據量的增多,對服務的要求越來越高,即使是將存儲的數據做了冷熱分離,查詢也非常的忙,并且隨著數據量的增多,插入的性能也越來越慢了。而且,對于所申請的Kafka集群,明顯也扛不住這么多客戶端每天輸入這么大的量,因此對日志這一塊的業務流程進行了仔細的梳理。
解決方案
經過不斷的討論和架構的評審,想到了一個比較好的解決辦法,那就是對日志數據進行業務分離。抽出了幾個日志量比較大的業務,比如訂單和商品,新申請了訂單和商品的Kafka集群和ES集群,其他業務還是不變,訂單和商品的日志和其他日志都單獨開來,使用不同的Kafka和ES、HBase集群。
通過對業務的抽離,性能得到了很明顯的提升,并且對數據進行業務的分類,也方便了對日志數據的管理,達到互不影響的狀態。今后對于HBase的數據,也打算將它推入到大數據集市中,提供不同的部門做數據分析。















