拋開復(fù)雜的架構(gòu)設(shè)計(jì),MySQL優(yōu)化思想基本都在這了

數(shù)據(jù)庫優(yōu)化一方面是找出系統(tǒng)的瓶頸,提高M(jìn)ySQL數(shù)據(jù)庫的整體性能,而另一方面需要合理的結(jié)構(gòu)設(shè)計(jì)和參數(shù)調(diào)整,以提高用戶的相應(yīng)速度,同時(shí)還要盡可能的節(jié)約系統(tǒng)資源,以便讓系統(tǒng)提供更大的負(fù)荷。
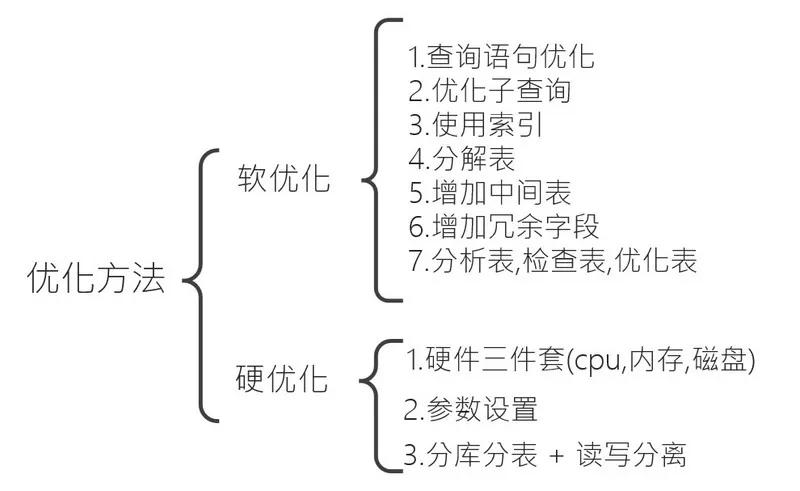
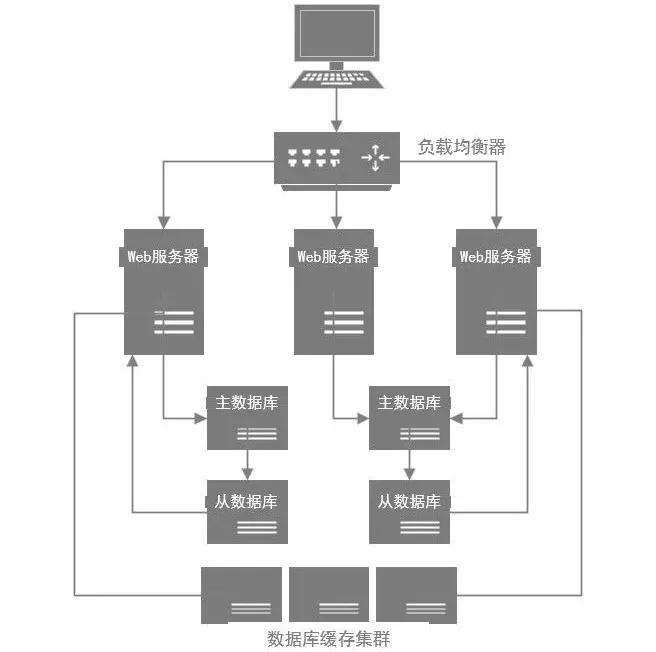
一、優(yōu)化一覽圖
二、優(yōu)化
筆者將優(yōu)化分為了兩大類:軟優(yōu)化和硬優(yōu)化。軟優(yōu)化一般是操作數(shù)據(jù)庫即可;而硬優(yōu)化則是操作服務(wù)器硬件及參數(shù)設(shè)置。
1、軟優(yōu)化
1)查詢語句優(yōu)化
首先我們可以用EXPLAIN或DESCRIBE(簡寫:DESC)命令分析一條查詢語句的執(zhí)行信息。
例:
- DESC SELECT * FROM `user`
顯示:

其中會(huì)顯示索引和查詢數(shù)據(jù)讀取數(shù)據(jù)條數(shù)等信息。
2)優(yōu)化子查詢
在MySQL中,盡量使用JOIN來代替子查詢。因?yàn)樽硬樵冃枰短撞樵儯短撞樵儠r(shí)會(huì)建立一張臨時(shí)表,臨時(shí)表的建立和刪除都會(huì)有較大的系統(tǒng)開銷,而連接查詢不會(huì)創(chuàng)建臨時(shí)表,因此效率比嵌套子查詢高。
3)使用索引
索引是提高數(shù)據(jù)庫查詢速度最重要的方法之一,使用索引的三大注意事項(xiàng)包括:
- LIKE關(guān)鍵字匹配'%'開頭的字符串,不會(huì)使用索引;
- OR關(guān)鍵字的兩個(gè)字段必須都是用了索引,該查詢才會(huì)使用索引;
- 使用多列索引必須滿足最左匹配。
4)分解表
對(duì)于字段較多的表,如果某些字段使用頻率較低,此時(shí)應(yīng)當(dāng)將其分離出來從而形成新的表。
5)中間表
對(duì)于將大量連接查詢的表可以創(chuàng)建中間表,從而減少在查詢時(shí)造成的連接耗時(shí)。
6)增加冗余字段
類似于創(chuàng)建中間表,增加冗余也是為了減少連接查詢。
7)分析表、檢查表、優(yōu)化表
分析表主要是分析表中關(guān)鍵字的分布;檢查表主要是檢查表中是否存在錯(cuò)誤;優(yōu)化表主要是消除刪除或更新造成的表空間浪費(fèi)。
分析表:使用 ANALYZE 關(guān)鍵字,如ANALYZE TABLE user

- Op:表示執(zhí)行的操作;
- Msg_type:信息類型,有status、info、note、warning、error;
- Msg_text:顯示信息。
檢查表: 使用 CHECK關(guān)鍵字,如CHECK TABLE user [option]。option 只對(duì)MyISAM有效。共五個(gè)參數(shù)值:
- QUICK:不掃描行,不檢查錯(cuò)誤的連接;
- FAST:只檢查沒有正確關(guān)閉的表;
- CHANGED:只檢查上次檢查后被更改的表和沒被正確關(guān)閉的表;
- MEDIUM:掃描行,以驗(yàn)證被刪除的連接是有效的,也可以計(jì)算各行關(guān)鍵字校驗(yàn)和;
- EXTENDED:最全面的的檢查,對(duì)每行關(guān)鍵字全面查找。
優(yōu)化表:使用OPTIMIZE關(guān)鍵字,如OPTIMIZE [LOCAL|NO_WRITE_TO_BINLOG] TABLE user;
LOCAL|NO_WRITE_TO_BINLOG都是表示不寫入日志,優(yōu)化表只對(duì)VARCHAR、BLOB和TEXT有效,通過OPTIMIZE TABLE語句可以消除文件碎片,在執(zhí)行過程中會(huì)加上只讀鎖。
2、硬優(yōu)化
1)硬件三件套
配置多核心和頻率高的cpu,多核心可以執(zhí)行多個(gè)線程;
配置大內(nèi)存,提高內(nèi)存,即可提高緩存區(qū)容量,因此能減少磁盤I/O時(shí)間,從而提高響應(yīng)速度;
配置高速磁盤或合理分布磁盤:高速磁盤提高I/O,分布磁盤能提高并行操作的能力。
2)優(yōu)化數(shù)據(jù)庫參數(shù)
優(yōu)化數(shù)據(jù)庫參數(shù)可以提高資源利用率,從而提高M(jìn)ySQL服務(wù)器性能。MySQL服務(wù)的配置參數(shù)都在my.cnf或my.ini,下面列出性能影響較大的幾個(gè)參數(shù):
- key_buffer_size:索引緩沖區(qū)大小;
- table_cache:能同時(shí)打開表的個(gè)數(shù);
- query_cache_size和query_cache_type:前者是查詢緩沖區(qū)大小,后者是前面參數(shù)的開關(guān),0表示不使用緩沖區(qū),1表示使用緩沖區(qū),但可以在查詢中使用SQL_NO_CACHE表示不要使用緩沖區(qū),2表示在查詢中明確指出使用緩沖區(qū)才用緩沖區(qū),即SQL_CACHE;
- sort_buffer_size:排序緩沖區(qū)。
更多參數(shù):
https://www.mysql.com/cn/why-mysql/performance/index.html
3)分庫分表
因?yàn)閿?shù)據(jù)庫壓力過大,首先一個(gè)問題就是高峰期系統(tǒng)性能可能會(huì)降低,因?yàn)閿?shù)據(jù)庫負(fù)載過高對(duì)性能會(huì)有影響。
另外一個(gè),壓力過大把你的數(shù)據(jù)庫給搞掛了怎么辦?
所以此時(shí)你必須得對(duì)系統(tǒng)做分庫分表+讀寫分離,也就是把一個(gè)庫拆分為多個(gè)庫,部署在多個(gè)數(shù)據(jù)庫服務(wù)上,這時(shí)作為主庫承載寫入請(qǐng)求。然后每個(gè)主庫都掛載至少一個(gè)從庫,由從庫來承載讀請(qǐng)求。
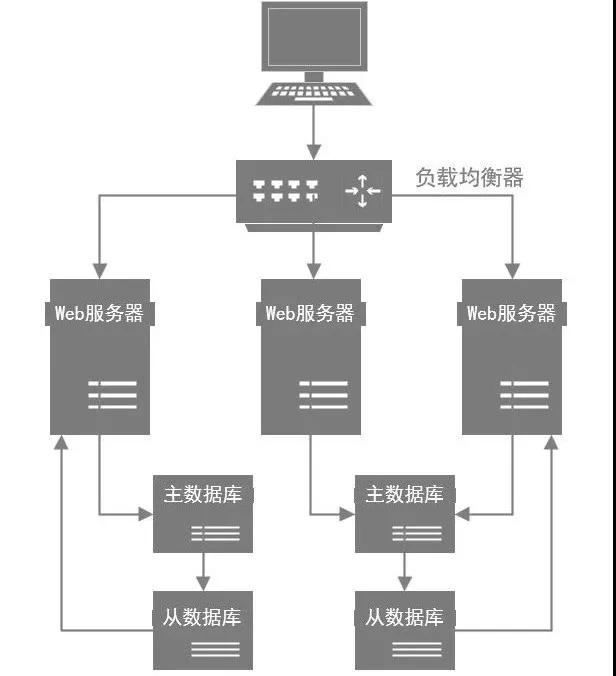
4)緩存集群
如果用戶量越來越大,此時(shí)你可以不停的加機(jī)器,比如說系統(tǒng)層面不停加機(jī)器,就可以承載更高的并發(fā)請(qǐng)求。
然后數(shù)據(jù)庫層面如果寫入并發(fā)越來越高,就擴(kuò)容加數(shù)據(jù)庫服務(wù)器,通過分庫分表是可以支持?jǐn)U容機(jī)器的,如果數(shù)據(jù)庫層面的讀并發(fā)越來越高,就擴(kuò)容加更多的從庫。
但是這里有一個(gè)很大的問題:
數(shù)據(jù)庫其實(shí)本身不是用來承載高并發(fā)請(qǐng)求的,所以通常來說,數(shù)據(jù)庫單機(jī)每秒承載的并發(fā)就在幾千的數(shù)量級(jí),而且數(shù)據(jù)庫使用的機(jī)器都是比較高配置,比較昂貴的機(jī)器,成本很高。
如果你就是簡單的不停的加機(jī)器,其實(shí)是不對(duì)的。
所以在高并發(fā)架構(gòu)里通常都有緩存這個(gè)環(huán)節(jié),緩存系統(tǒng)的設(shè)計(jì)就是為了承載高并發(fā)而生。單機(jī)承載的并發(fā)量都在每秒幾萬,甚至每秒數(shù)十萬,對(duì)高并發(fā)的承載能力比數(shù)據(jù)庫系統(tǒng)要高出一到兩個(gè)數(shù)量級(jí)。
你完全可以根據(jù)系統(tǒng)的業(yè)務(wù)特性,對(duì)那種寫少讀多的請(qǐng)求,引入緩存集群。
具體來說,就是在寫數(shù)據(jù)庫的時(shí)候同時(shí)寫一份數(shù)據(jù)到緩存集群里,然后用緩存集群來承載大部分的讀請(qǐng)求。這樣的話,通過緩存集群,就可以用更少的機(jī)器資源承載更高的并發(fā)。
三、結(jié)語
一個(gè)完整而復(fù)雜的高并發(fā)系統(tǒng)架構(gòu)中,一定會(huì)包含各種復(fù)雜的自研基礎(chǔ)架構(gòu)系統(tǒng)和各種精妙的架構(gòu)設(shè)計(jì),因此一篇小文頂多具有拋磚引玉的效果。但是總得來看,數(shù)據(jù)庫優(yōu)化的思想差不多就這些了。希望能對(duì)大家有所幫助。