













比較五款企業級ETL工具,助你選出適合項目的解決方案
譯文【51CTO.com快譯】在商業環境中,隨著各類數據量的不斷猛增,企業對于那些以ETL為基本要素的數據倉庫項目和高級分析系統的需求也在不斷增多。此處ETL所對應的是數據倉庫的三個概念:提取(Extracting)、轉換(Transforming)和加載(Loading)。其主要流程包括:
- 從不同的外部源提取數據。
- 將數據轉換為所需的業務模型。
- 將數據加載到新的倉庫之中。
可見,ETL是整個數據遷移任務的一個子集。在《數據倉庫ETL工具包(Warehouse ETL Toolkit)》一書中(請詳見https://www.amazon.com/Data-Warehouse-ETL-Toolkit-Techniques-Extracting/dp/0764567578),定義了ETL的三個基本特征:
- 以適當的格式下載數據,并予以分析。
- 它包含有許多額外的信息。
- 系統會記錄數據的來源。
因此,數據不應該只是簡單地從一處被加載到另一處,而應該在加載的過程中得到改進與優化。例如:ETL開發人員可以添加新的技術屬性,去跟蹤數據在數據庫中的顯示方式、數據被更改的時間及方式。
ETL的流程步驟
通常,Web程序員可以將ETL架構想象成如下圖所示的三個區域:
- 數據源。
- 中間區域。
- 數據接收器。
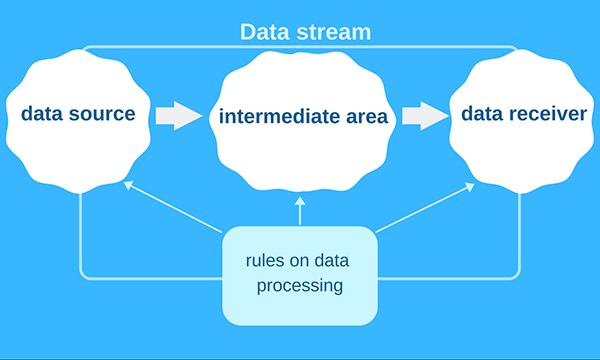
數據流從源頭向接收器移動。由于每個階段都非常復雜,因此創建ETL軟件的過程往往會包括如下不同的挑戰:
- 外部數據源的多樣性。
- 需要根據業務規則來統一數據。
- 更新頻率和其他具體的要求。
因此,普通IT公司需要清楚地了解數據源的結構,并配備相應的目標應用。
一個ETL示例
常見的ETL任務是將數據從關系數據庫管理系統(Relational Database Management System,RDBMS)傳輸到另一個更適合于商業智能工具的數據庫中。因此,ELT的作業可分為兩種類型:
- 批量作業
- 流式作業
其中,流式作業的一個例子是:從RDBMS中獲取數據,逐個且單獨地傳輸出去,以備后期處理。否則,我們認為它屬于批量處理的范疇。例如:您可以先獲取整個文件,再對其進行處理,***將其保存到更大的文件中。可以說,不同的ETL系統會以不同的方式處理上述任務。
如今,單一的批量方法已被淘汰。持續增長的流式數據源,導致了各種ETL工具被主要用于通過處理流式作業,來盡快地提供出各種***的數據。
同時,由于ETL能夠將數據成功地集成到各種數據庫和應用之中,而各種琳瑯滿目的云端數據集成工具,經常會讓我們難以做出選擇,因此我在此為大家羅列和比較了五款企業級ETL工具的優缺點,希望能夠幫助您找出最適合手頭項目的解決方案。
1. Apache Nifi
定價 :免費
優點:
- ***地實現了數據流的編程概念。
- 能夠處理二進制數據。
- 提供數據來源(Data Provenance)。
缺點:
- 用戶界面過于簡單。
- 缺乏實時監控和逐條記錄的統計數據。
由Apache Software Foundation開發的開源項目--Apache NiFi可謂是***的ETL工具之一。由于基于數據流的編程概念,因此它能夠讓我們在boxes中可視化地組裝各種程序,并在幾乎不需要任何代碼的情況下運行起來。在這一點上,您完全可以不必了解任何編程語言。
作為一款備受歡迎的ETL工具,NiFi能夠處理許多不同的數據源,其中包括:RabbitMQ、JDBC查詢、Hadoop、MQTT、以及UDP套接字等。而在操作方面,您可以對數據進行篩選、調整、連接、拆分、增強和驗證。
由于Apache NiFi是用Java編寫而成,并且是在Apache 2.0的許可證中發布的,因此它不但能夠在JVM上運行,而且支持所有的JVM語言。
該ETL工具既有助于用戶創建長期運行(long-running)的作業,又適用于處理流式數據和一些周期性的批處理。不過,對于那些手動式管理任務而言,用戶在設置NiFi時,可能會碰到一些麻煩。
Apache NiFi是一種功能強大且易于使用的解決方案。它采用了全面的架構模式,其FlowFile包含了各種元信息。因此,該工具不但能夠識別CSV,還可以處理照片、視頻、音頻文件、以及其他二進制數據。
NiFi的處理器包括如下三種輸出:
- Failure:意味著FlowFile的處理過程中存在著一些問題。
- Original:表示傳入的FlowFile已被處理。
- Success:表示FlowFiles的處理已完成。
您可以使用特殊的復選框,來刪除那些已終止的輸出。同時,您應該注意在高級ETL編程中的進程組(Process Groups),它們對于組合復雜的數據流元素來說是非常必需的。
NiFi的另一個實用功能是:可以采用不同的隊列策略(包括FIFO、LIFO以及其他)。Data Provenance是一種用于記錄數據流中幾乎所有內容的連接服務。它可以便利地讓您獲悉數據的保存或執行方式。當然,該功能的唯一缺點是需要大量的磁盤空間。
雖然在我看來Apache NiFi的界面不但簡潔清晰,而且可用性強,但是仍有不少用戶抱怨其缺少必要的組件。例如,他們認為:由于缺少了自動調整各種長SQL查詢的文本字段,因此只能通過手動來完成。
NiFi擁有內置的Node集群。您可以通過選擇一些實例,來讓它提取必要的ETL數據。另外,NiFi可以通過背壓(back pressure)機制,來快速地連接MySQL,獲取某個文件,并將其添加到下一個處理器上。
總而言之,Apache NiFi的主要優勢在于擁有100多種不同的嵌入式處理器。它們能夠通過HTTP、S3或Google Data Source來下載文件,并能將文件上傳到MySQL、或其他數據接收器上。您只需配置UI,按下RUN按鈕,后續它就能自動運行了。
2. Apache StreamSets
定價:免費
優點:
- 每個處理器都有基于單條記錄的統計信息,且具有友好的可視化調試效果。
- 用戶界面非常友好。
- 提供流式和基于記錄的數據工具。
缺點:
- 缺少可重用的JDBC配置。
- 更改單個處理器的設置后,需要停止整個數據流。
Apache StreamSets可謂Apache NiFi的強有力競爭對手,我們很難說出誰更勝一籌。
根據流暢且通用的數據流格式的設計思想,所有被放入StreamSets的數據都會被自動轉換為可交換的記錄。與Apache Nifi不同的是,該ETL工具并不顯示處理器之間的隊列。如果您想使用其他不同的格式,Apache Nifi通常需要從一個版本的處理器轉換為另一個版本。而StreamSets則不然,您需要為設置的更改停止整個數據流,而不僅僅停止某一個處理器。
在StreamSets中,雖然對于錯誤的修復看似困難,但事實上,由于它提供實時的調試工具,因此用戶反而更容易實現錯誤的修復。借助具有實時儀表板和顯示所有統計信息的友好用戶界面,您可以快速地發現并修復任何出現的錯誤。此外,您還可以在處理器之間的連接處,放置各種具有記錄功能的過濾器,以檢查不同可疑的記錄。因此,它具有如下四種處理器的變體:
- Origin:處理器從數據源接收信息。
- Processors:獲取和轉換接收到的數據。
- Destinations:將轉換后的數據放入各種外部文件。
- Executors:處理那些由其他處理器完成的操作。
StreamSets的各種處理器可以生成包括錯誤在內的動作和事件。您需要executors,來跟蹤和修復這些錯誤。雖然那些只用到Processors和Controller Services的用戶會更喜歡Apache NiFi的簡約設計。但是,StreamSets也有著規劃合理的架構。憑借著友好的用戶界面,它也并不那么難以上手。
我個人感覺:由于缺少了針對JDBC設置的Controller Services,因此在調整每一個處理器時,都會讓人覺得有些棘手。
StreamSets會在運行數據流之前檢查所有的處理器,即:在數據流啟動之前,必須確保所有處理器的連接。該功能會導致StreamSets不允許用戶留下任何暫未連接、以備將來修復錯誤的處理器。StreamSets的另一個缺點是:無法讓用戶同時選擇多個處理器。畢竟,逐一移動并重組多個處理器,會耗費大量的時間和精力。
總而言之,作為一款成熟的開源ETL工具,它提供了便捷的可視化數據流和時尚的Web界面。
3. Apache Airflow

定價 :免費
官方網站:https://airflow.apache.org
實用資源:教程
優點:
- 適合不同類型的任務。
- 具有清晰且可視化的用戶界面。
- 提供可擴展的方案。
缺點:
- 不適合流式作業。
- 需要額外的運算符(operators)。
這是一種被用于創建與跟蹤工作流的開源式ETL軟件。它可以與包括GCP、Azure和AWS在內的云服務一起使用。同時,您可以在Kubernetes上通過Astronomer Enterprise來運行Airflow。
在使用Python來編寫工作流代碼時,您不必擔心XML或GUI拖放等問題,這些步驟具有一定的智能性。作為一款靈活的任務調度程序,Airflow可以被用在許多API之中,以實現訓練ML模型、發送通知、跟蹤系統、以及增強函數等目的。
該平臺具有如下主要特點:
- 通過Qubole和astronomer.io來提供Airflow-as-a-Service。
- 2015年由Airbnb所創建,2016年轉入Apache。
- 以Google Cloud Composer為基礎。
- 工作流程被作為有向無環圖(directed acyclic graphs,DAGs)執行。
開發者可以用Apache Airflow來創建dynamic、extensible、elegant和scalable四種解決方案。因此,它通過Python代碼提供了動態管道的生成。同時,您還可以自定義運算符和執行程序,以及按需擴展的抽象庫。由于相關參數已被包含在平臺的核心里,因此它能夠創建出各種清晰準確的管道。此外,模塊化與消息隊列式的設計,也讓Airflow更容易實現按需擴展。
Apache Airflow適用于大多數日常任務,包括:運行ETL作業和ML管道,提供數據和完成數據庫備份。但是,對于流式作業來說,這并不是一個很好的選擇。
該平臺具有可視化元素的時尚UI。您可以查看所有正在運行的管道,跟蹤進度并修復錯誤。這些都有助于用戶完成DAG上的復雜任務。
雖然該結構比ETL數據庫更具動態性,但是它能夠提供穩定的工作流。因此,如果您將工作流定義為代碼的話,它們將更具有協作性、可版本化、可測試性和可維護性。
該平臺可運行在私有的Kubernetes集群中,并包含各種資源管理與分析工具,例如:StatsD、Prometheus和Grafana。
您可以使用如下的Airflow工作流,來進行ETL測試:
- 單元測試
- 集成測試
- 端到端測試(在某些情況下)
上述***種類型適用于檢查DAG的加載、Python運算符函數、各種自定義運算符和Bash/EMR腳本。該平臺不需要任何原始配置,其唯一需要更改的地方是:DB連接字符串。您需要創建一個空的數據庫,并授予用戶CREATE/ALTER的權限。剩下的就可以交給Airflow去完成了。
總而言之,Apache Airflow是一款由Python編寫的免費獨立框架。如果您想單獨運行Airflow的話,則會面臨一些挑戰,因此您***使用一些不同的運算符。
4. AWS Data Pipeline

定價:不定,請參見https://aws.amazon.com/datapipeline/pricing/
官方網站:https://aws.amazon.com/datapipeline/
優點:
- 易用的ETL技術
- 價格合理
- 靈活性好
缺點:
- 沒有太多內置函數
該Web服務確保了數據在AWS計算資源和各種數據源之間的處理和移動。它能夠對已存儲的數據提供***的訪問與轉換。其最終結果也可以被轉移到諸如:Amazon DynamoDB、Amazon RDS、Amazon EMR和Amazon S3等服務之中。該ETL工具簡化了創建復雜數據處理負載的相關過程,有助于實現可重復、高可用且可靠的用例負載(case-load)。
AWS Data Pipeline能夠移動和處理那些被鎖在本地數據孤島中的數據。Amazon號稱其ETL工具有如下六項主要優勢:
- 準確性
- 簡單性
- 適應性
- 價錢合理
- 可擴展性
- 透明度
AWS Data Pipeline是一種可靠的服務,它能夠在發生故障時,自動對各種活動進程進行重試。通過配置,您可以通過Amazon SNS接收到運行成功、延時或失敗等通知。
您還可以通過拖放控制臺,來簡單快速地設計各種管道。其內置的預置條件,省去了您通過額外編寫邏輯去調用它們。Web開發人員可能會用到的功能包括:調度、依賴關系跟蹤和問題處理。同時,該服務也被靈活地設計為能夠流暢地處理大量文件。
AWS Data Pipeline是一種無服務器式的編排服務,因此您只需為自己所使用的內容付費。同時,它為新用戶提供了免費的試用版。通過該透明式方案,用戶能夠接收與管道相關的完整信息,并完全控制各種計算資源。
這款ETL工具很適合于執行各種管道作業。我在當前的項目中就使用它來傳輸各種數據。雖然AWS Data Pipeline沒有豐富的內置函數,但是它提供了便捷的UI和內置了多種處理器的實用工具。用戶可以用它來生成各種實例,并實現級聯式的文件管理。
5. AWS Glue
定價:不定,請參見https://aws.amazon.com/glue/pricing/
官方網站:https://aws.amazon.com/glue/
實用資源:教程
優點:
- 支持各種數據源。
- 與AWS的各種服務有良好的集成。
缺點:
- 需要大量的手工操作。
- 靈活性差。
AWS Glue允許您在AWS管理控制臺中創建和運行一項ETL作業。該服務能夠從AWS中獲取各種數據和元數據,并通過放入相應的類目,以供ETL進行搜索、查詢和使用。整個過程分為如下三個步驟:
- 通過構建類目(包括JSON、CSV、Parquet和許多其他格式)對數據進行分類。
- 生成ETL代碼和各種編輯轉換(可用Scala或Python編寫)。
- 調度和運行各種ETL作業。
這款ETL工具具有如下三個主要優點:
- 便利性:由于能與眾多的AWS服務和引擎相緊密集成,因此該工具對于那些已經使用了Amazon產品的用戶來說,非常容易上手。不過,其缺點在于:您無法在本地、或任何其他云端環境中實現它。
- 經濟實惠:無服務器解決方案意味著您無需配置或管理任何基礎架構。因此,其成本取決于各個“數據處理單元”的開銷。您只需為正在運行的作業付費便可。
- 功能強大:能夠自動創建、維護和運行各種ETL作業。當然,該服務也需要大量的手工操作。
雖然AWS Glue是AWS生態系統中的重要組成部分,但是您應該注意它的細微差別。該服務能夠提供抽象級別的CSV文件。不過,您需要通過大量的手工操作,才能最終生成可運行的Spark代碼。您可以在Scala或Python中下載相應的代碼,并按需進行各種修改。雖然它適用于大量的數據源,但是該服務會最終強制您選取某一種特定的方案。而且您無法在后續的使用中,再去改用其他方式。
如何選擇正確的ETL工具
InfoWorld曾斷言:在構建數據倉庫系統的方面,ETL的成本占比***。用戶需要特別關注由它所產生的瓶頸。因此,只有恰當地實施ETL,才能優化企業的成本和加快員工的工作效率。***,我為您列出如下五個方面,供您在選用ETL工具時進行參考:
- 系統的復雜性。
- 您的數據要求。
- 開發者的經驗。
- ETL的技術成本。
- 特殊的業務需求。
原文標題:Top 5 Enterprise ETL Tools,作者:Vitaliy Samofal
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】










