分布式系統Kafka和ES中,JVM內存越大越好嗎?
這篇文章,給大家聊一個生產環境的實踐經驗:線上系統部署的時候,JVM 堆內存大小是越大越好嗎?
本文主要討論的是 Kafka 和 Elasticsearch 兩種分布式系統的線上部署情況,不是普通的 Java 應用系統。
是否依賴 Java 系統自身內存處理數據?
先說明一點,不管是我們自己開發的 Java 應用系統,還是一些中間件系統,在實現的時候都需要選擇是否基于自己 Java 進程的內存來處理數據。
大家應該都知道,Java、Scala 等編程語言底層依賴的都是 JVM,那么只要是使用 JVM,就可以考慮在 JVM 進程的內存中來放置大量的數據。
還是給大家舉個例子,大家應該還記得之前聊過消息中間件系統。
比如說系統 A 可以給系統 B 發送一條消息,那么中間需要依賴一個消息中間件,系統 A 要先把消息發送到消息中間件,然后系統 B 從這個消息中間件消費到這條消息。
大家看下面的示意圖:
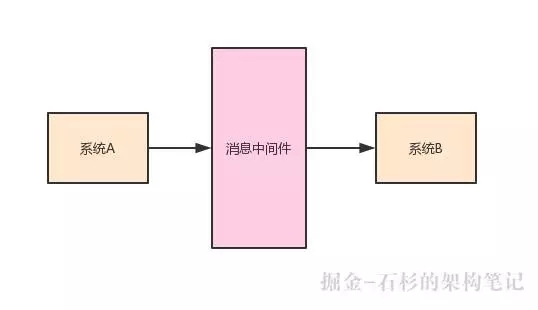
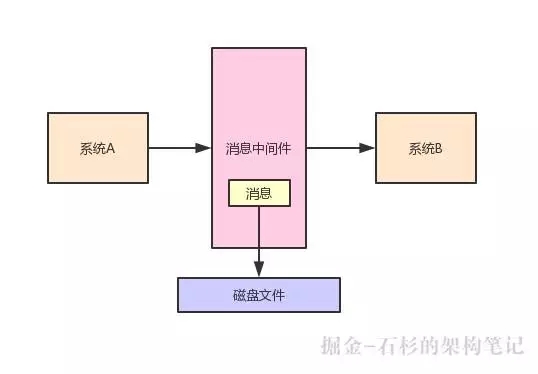
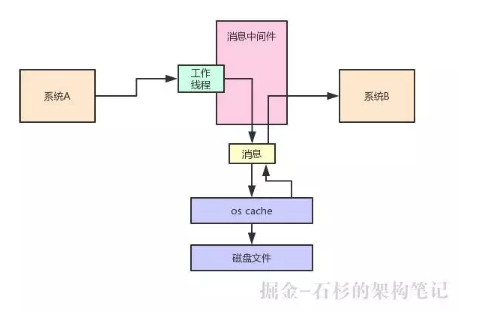
一條消息發送到消息中間件之后,有一種處理方式,就是把這條數據先緩沖在自己的 JVM 內存里。
然后過一段時間之后,再從自己的內存刷新到磁盤上去,這樣可以持久化保存這條消息,如下圖:
依賴 Java 系統自身內存有什么缺陷?
如果用類似上述的方式,依賴 Java 系統自身內存處理數據,比如說設計一個內存緩沖區,來緩沖住高并發寫入的大量消息,那么是有其缺陷的。
***的缺陷,其實就是 JVM 的 GC 問題,這個 GC 就是垃圾回收,這里簡單說一下它是怎么回事。
大家可以想一下,如果一個 Java 進程里老是塞入很多的數據,這些數據都是用來緩沖在內存里的,但是過一會兒這些數據都會寫入磁盤。
那么寫入磁盤之后,這些數據還需要繼續放在內存里嗎?明顯是不需要的了,此時就會依托 JVM 垃圾回收機制,把內存里那些不需要的數據給回收掉,釋放掉那些內存空間騰出來。
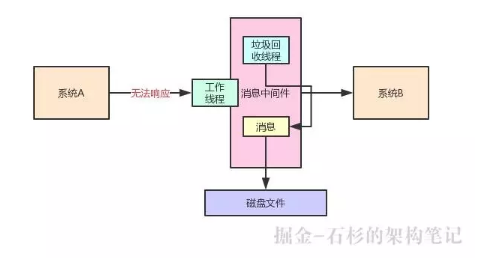
但是 JVM 垃圾回收的時候,有一種情況叫做 stop the world,就是它會停止你的工作線程,就專門讓它進行垃圾回收。
這個時候,它在垃圾回收的時候,有可能你的這個中間件系統就運行不了了。
比如你發送請求給它,它可能都沒法響應給你,因為它的接收請求的工作線程都停了,現在人家后臺的垃圾回收線程正在回收垃圾對象。
大家看下圖:
雖然說現在 JVM 的垃圾回收器一直在不斷的演進和發展,從 CMS 到 G1,盡可能的在降低垃圾回收的時候的影響,減少工作線程的停頓。
但是你要是完全依賴 JVM 內存來管理大量的數據,那在垃圾回收的時候,或多或少總是有影響的。
所以特別是對于一些大數據系統,中間件系統,這個 JVM 的 GC(Garbage Collector,垃圾回收)問題,真是最頭疼的一個問題。
優化為依賴 OS Cache 而不是 JVM
所以類似 Kafka、Elasticsearch 等分布式中間件系統,雖然也是基于 JVM 運行的,但是它們都選擇了依賴 OS Cache 來管理大量的數據。
也就是說,是操作系統管理的內存緩沖,而不是依賴 JVM 自身內存來管理大量的數據。
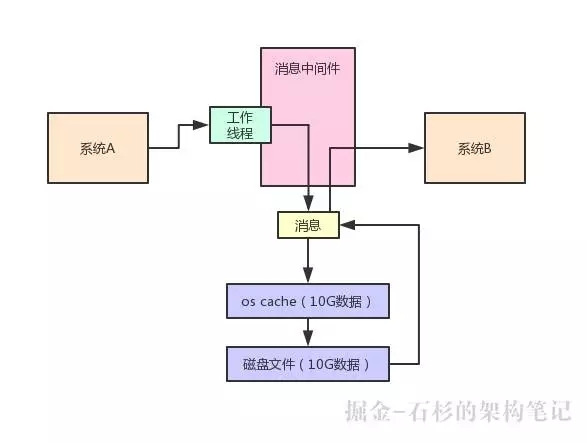
具體來說,比如說 Kafka 吧,如果你寫一條數據到 Kafka,它實際上會直接寫入磁盤文件。
但是磁盤文件在寫入之前其實會進入 OS Cache,也就是操作系統管理的內存空間,然后過一段時間,操作系統自己會選擇把它的 OS Cache 的數據刷入磁盤。
然后后續在消費數據的時候,其實也會優先從 OS Cache(內存緩沖)里來讀取數據。
相當于寫數據和讀數據都是依托于 OS Cache 來進行的,完全依托操作系統級別的內存區域來進行,讀寫性能都很高。
此外,還有另外一個好處,就是不要依托自身 JVM 來緩沖大量的數據,這樣可以避免復雜而且耗時的 JVM 垃圾回收操作。
大家看下面的圖,其實就是一個典型的 Kafka 的運行流程:
然后比如 Elasticsearch,它作為一個現在***的分布式搜索系統,也是采用類似的機制。
大量的依賴 OS Cache 來緩沖大量的數據,然后在進行搜索和查詢的時候,也可以優先從 OS Cache(內存區域)中讀取數據,這樣就可以保證非常高的讀寫性能。
依賴 OS Cache 的系統,JVM 內存越大越好?
現在就可以進入我們的主題了,那么比如就以上述說的 Kafka、Elasticsearch 等系統而言,在線上生產環境部署的時候,你知道它們是大量依賴于 OS Cache 來緩沖大量數據的。那么,給它們分配 JVM 堆內存大小的時候是越大越好嗎?
明顯不是的,假如說你有一臺機器,有 32GB 的內存,現在你如果在搞不清楚狀況的情況下,要是傻傻的認為還是給 JVM 分配越大內存越好,此時比如給了 16G 的堆內存空間給 JVM,那么 OS Cache 剩下的內存,可能就不到 10GB 了,因為本身其他的程序還要占用幾個 GB 的內存。
那如果是這樣的話,就會導致你在寫入磁盤的時候,OS Cache 能容納的數據量很有限。
比如說一共有 20G 的數據要寫入磁盤,現在就只有 10GB 的數據可以放在 OS Cache 里,然后另外 10GB 的數據就只能放在磁盤上。
此時在讀取數據的時候,那么起碼有一半的讀取請求,必須從磁盤上去讀了,沒法從 OS Cache 里讀,誰讓你 OS Cache 里就只能放的下 10G 的一半大小的數據啊,另外一半都在磁盤里,這也是沒辦法的,如下圖:
那此時你有一半的請求都是從磁盤上在讀取數據,必然會導致性能很差。
所以很多人在用 Elasticsearch 的時候就是這樣的一個問題,老是覺得 ES 讀取速度慢,幾個億的數據寫入 ES,讀取的時候要好幾秒。
那能不花費好幾秒嗎?你要是 ES 集群部署的時候,給 JVM 內存過大,給 OS Cache留了幾個 GB 的內存,導致幾億條數據大部分都在磁盤上,不在 OS Cache 里,***讀取的時候大量讀磁盤,耗費個幾秒鐘是很正常的。
正確的做法:針對場景合理給 OS Cache 更大內存
所以說,針對類似 Kafka、Elasticsearch 這種生產系統部署的時候,應該要給 JVM 比如 6GB 或者幾個 GB 的內存就可以了。
因為它們可能不需要耗費過大的內存空間,不依賴 JVM 內存管理數據,當然具體是設置多少,需要你精準的壓測和優化。
但是對于這類系統,應該給 OS Cache 留出來足夠的內存空間,比如 32GB 內存的機器,完全可以給 OS Cache 留出來 20 多 G 的內存空間。
那么此時假設你這臺機器總共就寫入了 20GB 的數據,就可以全部駐留在 OS Cache 里了。
然后后續在查詢數據的時候,不就可以全部從 OS Cache 里讀取數據了,完全依托內存來走,那你的性能必然是毫秒級的,不可能出現幾秒鐘才完成一個查詢的情況。
整個過程,如下圖所示:

所以說,建議大家在線上生產系統引入任何技術的時候,都應該先對這個技術的原理,甚至源碼進行深入的理解,知道它具體的工作流程是什么,然后針對性的合理設計生產環境的部署方案,保證***的生產性能。
中華石杉:十余年 BAT 架構經驗,一線互聯網公司技術總監。帶領上百人團隊開發過多個億級流量高并發系統。現將多年工作中積累下的研究手稿、經驗總結整理成文,傾囊相授。微信公眾號:石杉的架構筆記(ID:shishan100)。