













數據庫系統實現-存儲管理(CheckSum&RAID)
磁盤并不是萬無一失的,也可能發生故障和損壞。磁盤發生故障是災難性的,存儲介質的損壞如果在沒備份的情況下,基本是100%丟失數據,比rm -rf 還嚴重,那么磁盤的故障有那么些?
- 間歇性故障
- 介質損壞
- 寫故障
- 磁盤崩潰
在這些故障的時候有哪些應對策略和辦法?我們這章來來學習一下。
間歇性故障
當我們嘗試從磁盤讀一個塊的時候,可能這個塊的內容未正確的發送到磁盤控制器,這就是一次間歇性的故障,控制器會以一種辦法來判斷這個磁盤塊的好壞,如果讀的數據是壞的,控制器會嘗試再次讀取發起請求,直到讀取的數據正確位置,或者發送N次請求,然后再停止。
同樣,我們嘗試寫入一個扇區,可能寫入的內容不是原本想要寫入的內容,唯一的辦法就是磁盤把寫入的內容讀取出來跟磁盤控制器的內容再比較一下。然而,跟磁盤控制器比較,其實還可以讀取寫入的扇區,并且查看狀態是否為"好",如果狀態是"壞"那么就重寫,這個狀態如何產生的呢?這就引出了是checksum概念。
校驗和(checksum)
在說checksum之前,我們來玩個小游戲:
桌子上擺放了7個黑白棋子,魔術師蒙著眼睛看不見棋子。魔術師徒弟在看完7個棋子之后在右邊添加個棋子,和其他棋子并排,這個時候有8個棋子,魔術師依舊蒙著眼睛。這個時候觀眾可將其中的一個棋子翻轉,或者不翻轉任何一枚。觀眾和徒弟一言不發,魔術師并不知道觀眾是否翻轉棋子。
現在魔術師摘下眼罩,觀察8枚棋子,然后可以說出是否翻轉了棋子,識破觀眾的行為。那么魔術師是如何識破的呢?
校驗和:在磁盤的每個扇區都有幾個附加位,這個被稱為校驗和。在數據讀取的時候,如果校驗和跟數據位不符合,那么就判斷讀取錯誤。不過校驗和正確,也有可能數據是錯誤的,這個的可能性跟校驗位的長度成負相關。校驗位越長,判斷錯誤的概率越小。
校驗和是基于扇區內所有位的奇偶性(parity),如果二進制的集合中有奇數個1,那么數據位有奇數奇偶性并增加值為1的奇偶位。同理,如果有偶數個1,那么數據位有偶數奇偶性并且增加值為0的奇數位。
假如我們用一個字節(8bits)來判斷奇偶,并且檢測出錯誤的可能性為50%,那么出錯的概率為,1/2^8,如果用4個字節呢,則出錯率為1/2^32。相對于40億次中只有一次錯誤沒被檢測出來。
一般的在數據庫中用的是CRC或者是FNV算來進行checksum的,在PostgreSQL中用得上 FNV-1a,我們來看看PG是如何實現的。
PostgreSQL-CheckSum
Postgres默認是不開啟checksum的,在初始化數據庫的時候可以通過選項-k開啟。
- -k, --data-checksums use data page checksums
使用的算法是FNV-1a,下面的地址是這個算法的詳細介紹:http://www.isthe.com/chongo/tech/comp/fnv/
核心代碼在:src/include/storage/checksum_impl.h
函數入口:pg_checksum_block
官方描述:

PG的實現跟官方的實現有區別,官方的實現為:

而PG在乘之前,先右移了17位,然后再xor。
計算出來的結果都存儲在頁頭PageHeaderData->pd_checksum
數據從shared_buffer刷盤以及從disk讀取block都需要計算checksum。如果只是在內存中變更數據頁,是不需要計算checksum的。
感興趣的可以gdb跟一下看看。
再回到上面的小游戲,魔術師只要跟徒弟在之前協定好,有偶數個白或者黑,問題就解決了,這也是一種奇偶校驗的實現。
介質損壞
磁盤也是有使用壽命的,當磁盤損壞后,破壞是物理性的,數據是不可能完全的恢復回來。在上面我們介紹了如何來高效的檢測介質的故障或讀寫的故障,但是卻沒說明如何解決這個問題。
在磁盤的扇區損壞的問題上,可以用2塊或者多塊磁盤來存儲數據。例如我們寫入內容X,通常扇區是成對的,我們把寫入X的扇區稱作為(左拷貝)Xl和(右拷貝)Xr。讀函數可以讀取Xl或者Xr,返回一個結果w,那么w是X的真實的內容。前提是我們通過CheckSum對Xl和Xr扇區的完整性做了排查。(這段內容有點繞口,其實就是寫2份數據到不同的磁盤扇區,然后可以任意從其中一個讀取到你想要的內容)。
寫的策略也是一樣的,例如寫入Xl,檢查是否返回狀態為"好",如果不是,就需要不停的寫,到達若干次后,如果任然未成功,則可表示該扇區是壞的,則可以用Xr來替換損壞Xl。相反對Xr跟Xl是一樣的邏輯,重復Xl的動作即可。
讀策略是交互的,交替的讀取Xl和Xr,預先設定個很大的數字,若嘗試超過這個數據,則可以確定X是無法讀取的。
RAID
上面討論的內容其實就是RAID(Redundant Array of Independent Disk,獨立磁盤冗余陣列)。磁盤崩潰發生率一般由平均失效時間來衡量,假設磁盤平均失效時間為10年,則每年磁盤中的1/10會發生故障,為了避免這種故障,就采用了這種策略,當一個數據盤或者冗余盤發生崩潰的時候,其他的磁盤可用于恢復故障磁盤,從而使得沒有任何數據會丟失。RAID分了很多等級,我們下面就看看不同等級的計算和使用。
RAID-1
RAID-1方案使用2塊磁盤做扇區的拷貝,一個做數據盤,一個做冗余盤,或者互換。相當于有2份磁盤空間來存儲數據(空間浪費),任何一份失效,可以使用未損壞的進行修復,除非2塊盤同時失效。
看個例子:假設每個磁盤的使用壽命為10年,那么意味著每年的損壞率為10%。如果磁盤被鏡像,發生故障的時候我們可以利用另外一塊好的替換他。所以造成錯誤的至少要2個磁盤的數據都丟失,才能說是數據無法恢復。假設替換的時間為3個小時,這是一天中的1/8,或者是1年的1/2920,那么10年的故障率為1/29200,2塊磁盤之一平均5年發生一次故障,那么丟失數據的概率大概為5*29200=14600年。
RAID-4(奇偶塊)
RAID是以磁盤塊為奇偶校驗,假設有N塊數據盤,一個冗余盤,在冗余盤中,第i塊由所有的數據盤的第i塊奇偶校驗位組成,也就是說,所有第i塊盤的j位,包括數據盤和冗余盤,他們中間必須有偶數個1,而我們總是選取冗余盤的位讓條件為真。
假設我們有4塊盤,3個數據盤,一個冗余盤。假設一個塊只有一個字節,8位。
盤1:11110000
盤2:10101010
盤3:00111000
冗余盤
盤4:01100010
在1,2,4,5,7位有兩個1,在3,4有4個1,在6和8有零個1。
利用冗余盤的位讓數據盤的奇偶校驗條件為真。
讀:
從任意一個數據盤讀取是沒有任何差別。
寫
當我們寫一個數據盤的一個新塊,我們不僅僅需要改變那個數據塊,還需要改變冗余盤的相應的塊,以保持數據盤的奇偶性。一個樸素的辦法是讀取N個數據盤的相應塊,取他們的摸2和,并重寫冗余盤,那么這樣就會是N+1次的磁盤I/O。
還有個更好的辦法,只關注在被寫盤的i塊的老版本和新版本,操作如下:
1、讀要要被改變的數據盤的舊值
2、讀冗余盤的相應塊
3、寫新數據盤
4、重新計算并寫冗余盤的塊
這樣就只有4次I/O操作
摸2代數解釋

假設有如下三個數據盤,***個塊如下:
盤1:11110000
盤2:10101010
盤3:00111000
冗余盤:01100010
假設盤2的塊由10101010改變為11001100,我們來求盤2上的舊值和新值的摸2和,得到
01100110,這個結果告訴我們,必須改變冗余盤的***塊的位置,2,3,6,7的值。那么冗余盤為:0000100,如下:
盤1:11110000
盤2:11001100
盤3:00111000
冗余盤:0000100
這樣每列依舊有偶數個1
故障恢復
如果是冗余盤壞了,直接換一塊新盤,并且重新計算奇偶。如果是數據盤壞了,也是換一個新盤,不起根據其他盤重新計算它的數據。我們來看個例子:
盤1:11110000
盤2:????????
盤3:00111000
盤4:01100010
我們取每一列的模2和,可以推導出盤2為:
盤1:11110000
xor
盤2:00111000
=:11001000
xor
01100010
=10101010
RAID-5
在RAID-4的策略中,除非2塊盤同時損壞,否則還是能有效的保護數據。不過有個缺點,就是無論是讀和寫都需要訪問冗余盤。從上面故障恢復的例子可以發現,恢復數據盤和冗余盤是一樣的策略,都是取其它盤的模2和。這樣,我們就不必要把一個盤做冗余盤,而把其他盤作為數據盤,相反,我們可以把每個磁盤作為某寫塊的冗余盤來處理,這種改進稱為RAID-5。
假設我們有4塊盤,0-3。***個盤編號為0,講作為編號為4,8,12等盤的冗余,因為當被4除時,余數為0。編號為1的盤將作為編號為1,5,9等塊的冗余。盤2是2,6,10塊的冗余,盤3是3,7,11等塊的冗余。
如果每個盤讀寫負荷一樣,如果所有的塊有相同的可能性被寫,那么對于一次寫,每個盤有1/4的機會,并且還有1/3的機會作為那個塊的冗余盤。這樣,4個盤的每個涉及寫的機會是1/4+3/4*1/3=1/2
多個盤的崩潰處理(RAID-6)
前面講的都是一塊盤的崩潰,如果涉及到多個盤的崩潰,還是無法處理的。多個盤的崩潰有一個糾錯碼原理,允許我們處理多個盤的崩潰,前提的我們有足夠多的冗余盤。這個 策略導致了***的RAID級別-RAID-6。這個策略是基于海明碼(Hamming code)進行糾錯的。
我們來看個例子,一個7個磁盤的系統,磁盤編號為1-7,前面4個是數據盤,5-7是冗余盤。數據盤和冗余盤組成的一個3*7的矩陣,如下圖:
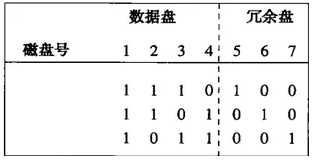
如圖,請注意:
1、除了全0列之外的,三個0和1的所有可能的列都在這個矩陣中
2、冗余盤有單個1
3、數據盤至少各有兩個1
通過這個矩陣可以知道:
1、盤5是盤1、2、3相應位的摸2和
2、盤6是盤1、2、4相應位的模2和
3、盤7是盤1、3、4相應位的模2和
通過這個規則,我們就能從兩個同時發生故障的磁盤崩潰中恢復。
讀
我們從任何一個數據盤讀取數據,不用理睬冗余盤
寫
寫的話就需要考慮冗余盤。為了寫某個塊,需要計算新舊塊的摸2和,這些位以模2和的方式加入到滿足條件的所有冗余盤相應塊中。
看個例子:
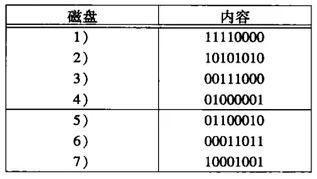
我們把第二個盤修改為00001111,新值和舊值的模2和為:10100101,因為盤5和6在盤行1和行2都有1
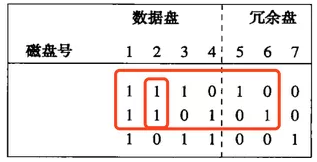
所以我們需要拿他們的***個塊跟剛才算出來的值10100101執行摸2和,也就是說我們需要對這2個塊的1,3,6,8位置求反。
盤5:
10100101
xor
01100010
=
11000111
盤6:
10100101
xor
00011011
=
10111110
所以結果如下:
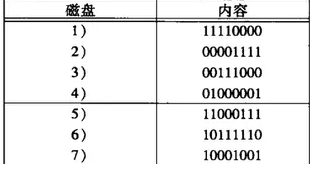
RAID-6故障恢復
假設故障盤為a和b,我們可以從下面這個矩陣中能夠把a和b的列不同的某個行r找到,假設a是0,而b是1.
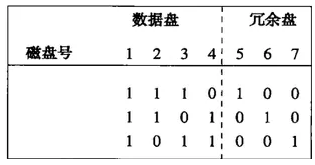
然后我們通過取來自b之外所有的行r有1的磁盤相應位模2,我們就能計算出b。計算完b,我們必須用所有其他的盤重新計算a。辦法是取該行帶1的那些其他磁盤的位摸2.
看個例子,如果盤2和盤5在同一時間損壞,如下圖:
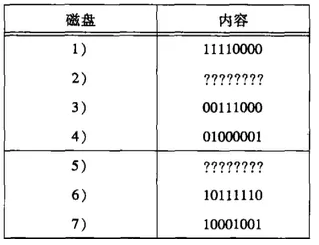
我們發現這2個盤在列2不同,盤2是1盤5是0,那么我們用盤1,4,6來恢復盤2如下圖:
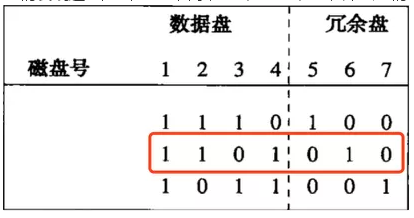
盤2通過計算得到:
盤1:11110000
xor
盤4:01000001
=10110001
Xor
盤6:10111110
=00001111
盤5可以用盤1,2,3來恢復,如下圖:
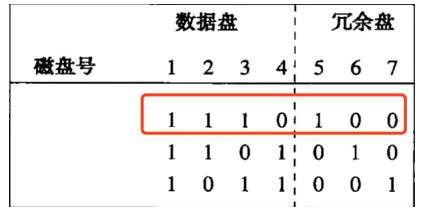
盤1:11110000
xor
盤2:00001111
=11111111
xor
盤3:00111000
=11000111
這樣盤2和盤5都恢復了,結果如下:
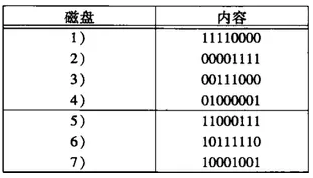
關于RAID-6,磁盤的數量可以是任意次方-1,例如2^k-1,k是冗余盤,剩下的2^k-k-1是數據盤,所有冗余盤差不多是數據盤的對數增長的,并且都可以構造成矩陣來表示。
書中只大概介紹了這幾種RAID,不過現在有跟多的RAID,例如:
- RAID-0:Data Stripping
- RAID-1:磁盤鏡像
- RAID-0+1:RAID-0和RAID-1的結合體
- RAID-2:帶海明嗎校驗
- RAID-3:帶奇偶校驗并行傳送
- RAID-4:帶奇偶校驗獨立磁盤結構
- RAID-5:分布式奇偶校驗
- RAID-6:帶2種分布式存儲奇偶校驗
- RAID-7:優化的高速傳輸磁盤結構
- RAID-10:高可靠和高效磁盤結構
- RAID-53:高速數據傳輸磁盤結構
總結:主要是講磁盤的損壞和恢復方面的內容,包括如何檢測損壞和如何恢復,checksum是個很好的檢測手段,而磁盤的冗余是在存儲介質損壞的時候提供有力的數據保護,并且分析了幾種冗余策略。下一章我們來看看數據是如何在磁盤組織的,包括定長&變長數據的存儲,Tuple的修改(插入,刪除,跟新),跨塊的存儲和列存儲相關內容,并且我們用C語言自己來寫個例子程序。













