JavaScript是如何工作的:JavaScript的共享傳遞和按值傳遞
關于JavaScript如何將值傳遞給函數,在互聯網上有很多誤解和爭論。大致認為,參數為原始數據類時使用按值傳遞,參數為數組、對象和函數等數據類型使用引用傳遞。
按值傳遞 和 引用傳遞參數 主要區別簡單可以說:
- 按值傳遞:在函數里面改變傳遞的值不會影響到外面
- 引用傳遞:在函數里面改變傳遞的值會影響到外面
但答案是 JavaScript 對所有數據類型都使用按值傳遞。它對數組和對象使用按值傳遞,但這是在的共享傳參或拷貝的引用中使用的按值傳參。這些說有些抽象,先來幾個例子,接著,我們將研究JavaScript在 函數執行期間的內存模型,以了解實際發生了什么。
按值傳參
在 JavaScript 中,原始類型的數據是按值傳參;對象類型是跟Java一樣,拷貝了原來對象的一份引用,對這個引用進行操作。但在 JS 中,string 就是一種原始類型數據而不是對象類。
- let setNewInt = function (i) {
- ii = i + 33;
- };
- let setNewString = function (str) {
- str += "cool!";
- };
- let setNewArray = function (arr1) {
- var b = [1, 2];
- arr1 = b;
- };
- let setNewArrayElement = function (arr2) {
- arr2[0] = 105;
- };
- let i = -33;
- let str = "I am ";
- let arr1 = [-4, -3];
- let arr2 = [-19, 84];
- console.log('i is: ' + i + ', str is: ' + str + ', arr1 is: ' + arr1 + ', arr2 is: ' + arr2);
- setNewInt(i);
- setNewString(str);
- setNewArray(arr1);
- setNewArrayElement(arr2);
- console.log('現在, i is: ' + i + ', str is: ' + str + ', arr1 is: ' + arr1 + ', arr2 is: ' + arr2);
運行結果
- i is: -33, str is: I am , arr1 is: -4,-3, arr2 is: -19,84
- 現在, i is: -33, str is: I am , arr1 is: -4,-3, arr2 is: 105,84
這邊需要注意的兩個地方:
1)***個是通過 setNewString 方法把字符串 str 傳遞進去,如果學過面向對象的語言如C#,Java 等,會認為調用這個方法后 str 的值為改變,引用這在面向對象語言中是 string 類型的是個對象,按引用傳參,所以在這個方法里面更改 str 外面也會跟著改變。
但是 JavaScript 中就像前面所說,在JS 中,string 就是一種原始類型數據而不是對象類,所以是按值傳遞,所以在 setNewString 中更改 str 的值不會影響到外面。
2)第二個是通過 setNewArray 方法把數組 arr1 傳遞進去,因為數組是對象類型,所以是引用傳遞,在這個方法里面我們更改 arr1 的指向,所以如果是這面向對象語言中,我們認為***的結果arr1 的值是重新指向的那個,即 [1, 2],但***打印結果可以看出 arr1 的值還是原先的值,這是為什么呢?
共享傳遞
Stack Overflow上Community Wiki 對上述的回答是:對于傳遞到函數參數的對象類型,如果直接改變了拷貝的引用的指向地址,那是不會影響到原來的那個對象;如果是通過拷貝的引用,去進行內部的值的操作,那么就會改變到原來的對象的。
可以參考博文 JavaScript Fundamentals (2) – Is JS call-by-value or call-by-reference?
- function changeStuff(state1, state2)
- {
- state1.item = 'changed';
- state2 = {item: "changed"};
- }
- var obj1 = {item: "unchanged"};
- var obj2 = {item: "unchanged"};
- changeStuff(obj1, obj2);
- console.log(obj1.item); // obj1.item 會被改變
- console.log(obj2.item); // obj2.item 不會被改變
緣由: 上述的 state1 相當于 obj1, 然后 obj1.item = 'changed',對象 obj1 內部的 item 屬性進行了改變,自然就影響到原對象 obj1 。類似的,state2 也是就 obj2,在方法里 state2 指向了一個新的對象,也就是改變原有引用地址,這是不會影響到外面的對象(obj2),這種現象更專業的叫法:call-by-sharing,這邊為了方便,暫且叫做 共享傳遞。
內存模型
JavaScript 在執行期間為程序分配了三部分內存:代碼區,調用堆棧和堆。 這些組合在一起稱為程序的地址空間。
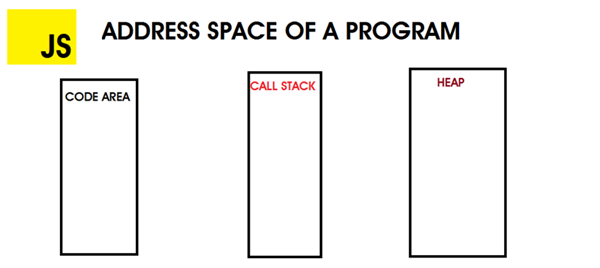
代碼區:這是存儲要執行的JS代碼的區域。
調用堆::這個區域跟蹤當前正在執行的函數,執行計算并存儲局部變量。變量以后進先出法存儲在堆棧中。***一個進來的是***個出去的,數值數據類型存儲在這里。
例如:
- var corn = 95
- let lion = 100
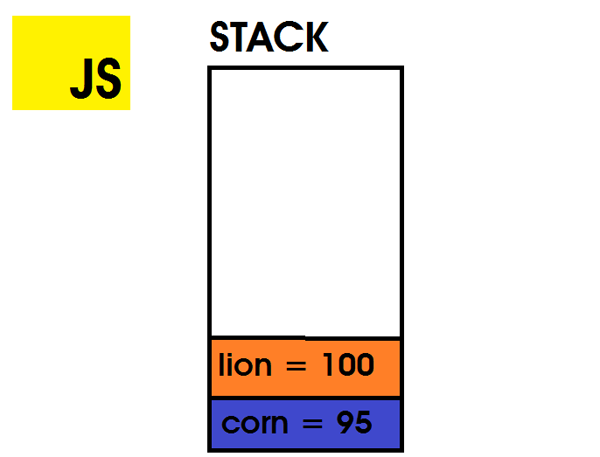
在這里,變量 corn 和 lion 值在執行期間存儲在堆棧中。
堆:是分配 JavaScript 引用數據類型(如對象)的地方。 與堆棧不同,內存分配是隨機放置的,沒有 LIFO策略。 為了防止堆中的內存漏洞,JS引擎有防止它們發生的內存管理器。
- class Animal {}
- // 在內存地址 0x001232 上存儲 new Animal() 實例
- // tiger 的堆棧值為 0x001232
- const tiger = new Animal()
- // 在內存地址 0x000001 上存儲 new Objec實例
- // `lion` 的堆棧值為 0x000001
- let lion = {
- strength: "Very Strong"
- }
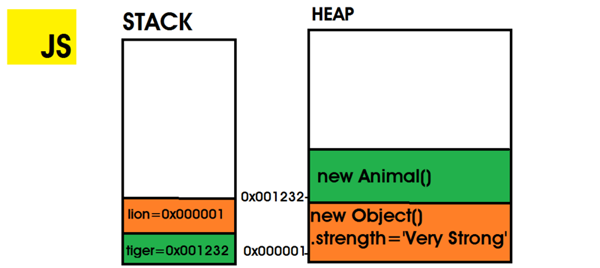
Here,lion 和 tiger 是引用類型,它們的值存儲在堆中,并被推入堆棧。它們在堆棧中的值是堆中位置的內存地址。
激活記錄(Activation Record),參數傳遞
我們已經看到了 JS 程序的內存模型,現在,讓我們看看在 JavaScript 中調用函數時會發生什么。
- // 例子一
- function sum(num1,num2) {
- var result = num1 + num2
- return result
- }
- var a = 90
- var b = 100
- sum(a, b)
每當在 JS 中調用一個函數時,執行該函數所需的所有信息都放在堆棧上。這個信息就是所謂的激活記錄(Activation Record)。
這個 Activation Record,我直譯為激活記錄,找了好多資料,沒有看到中文一個比較好的翻譯,如果朋友們知道,歡迎留言。
激活記錄上的信息包括以下內容:
- SP 堆棧指針:調用方法之前堆棧指針的當前位置。
- RA 返回地址:這是函數執行完成后繼續執行的地址。
- RV 返回值:這是可選的,函數可以返回值,也可以不返回值。
- 參數:將函數所需的參數推入堆棧。
- 局部變量:函數使用的變量被推送到堆棧。
我們必須知道這一點,我們在js文件中編寫的代碼在執行之前由 JS 引擎(例如 V8,Rhino,SpiderMonke y等)編譯為機器語言。
所以以下的代碼:
- let shark = "Sea Animal"
會被編譯成如下機器碼:
- 01000100101010
- 01010101010101
上面的代碼是我們的js代碼等價。 機器碼和 JS 之間有一種語言,它是匯編語言。 JS 引擎中的代碼生成器在最終生成機器碼之前,首先是將 js 代碼編譯為匯編代碼。
為了了解實際發生了什么,以及在函數調用期間如何將激活記錄推入堆棧,我們必須了解程序是如何用匯編表示的。
為了跟蹤函數調用期間參數是如何在 JS 中傳遞的,我們將例子一的代碼使用匯編語言表示并跟蹤其執行流程。
先介紹幾個概念:
ESP:(Extended Stack Pointer)為擴展棧指針寄存器,是指針寄存器的一種,用于存放函數棧頂指針。與之對應的是 EBP(Extended Base Pointer),擴展基址指針寄存器,也被稱為幀指針寄存器,用于存放函數棧底指針。
EBP:擴展基址指針寄存器(extended base pointer) 其內存放一個指針,該指針指向系統棧最上面一個棧幀的底部。
EBP 只是存取某時刻的 ESP,這個時刻就是進入一個函數內后,cpu 會將ESP的值賦給 EBP,此時就可以通過 EBP 對棧進行操作,比如獲取函數參數,局部變量等,實際上使用 ESP 也可以。
- // 例子一
- function sum(num1,num2) {
- var result = num1 + num2
- return result
- }
- var a = 90
- var b = 100
- var s = sum(a, b)
我們看到 sum 函數有兩個參數 num1 和 num2。函數被調用,傳入值分別為 90 和 100 的 a 和 b。
記住:值數據類型包含值,而引用數據類型包含內存地址。
在調用 sum 函數之前,將其參數推入堆棧
- ESP->[......]
- ESP->[ 100 ]
- [ 90 ]
- [.......]
然后,它將返回地址推送到堆棧。返回地址存儲在EIP 寄存器中:
- ESP->[Old EIP]
- [ 100 ]
- [ 90 ]
- [.......]
接下來,它保存基指針
- ESP->[Old EBP]
- [Old EIP]
- [ 100 ]
- [ 90 ]
- [.......]
然后更改 EBP 并將調用保存寄存器推入堆棧。
- ESP->[Old ESI]
- [Old EBX]
- [Old EDI]
- EBP->[Old EBP]
- [Old EIP]
- [ 100 ]
- [ 90 ]
- [.......]
為局部變量分配空間:
- ESP->[ ]
- [Old ESI]
- [Old EBX]
- [Old EDI]
- EBP->[Old EBP]
- [Old EIP]
- [ 100 ]
- [ 90 ]
- [.......]
這里執行加法:
- mov ebp+4, eax ; 100
- add ebp+8, eax ; eaxeax = eax + (ebp+8)
- mov eax, ebp+16
- ESP->[ 190 ]
- [Old ESI]
- [Old EBX]
- [Old EDI]
- EBP->[Old EBP]
- [Old EIP]
- [ 100 ]
- [ 90 ]
- [.......]
我們的返回值是190,把它賦給了 EAX。
- mov ebp+16, eax
EAX 是"累加器"(accumulator), 它是很多加法乘法指令的缺省寄存器。
然后,恢復所有寄存器值。
- [ 190 ] DELETED
- [Old ESI] DELETED
- [Old EBX] DELETED
- [Old EDI] DELETED
- [Old EBP] DELETED
- [Old EIP] DELETED
- ESP->[ 100 ]
- [ 90 ]
- EBP->[.......]
并將控制權返回給調用函數,推送到堆棧的參數被清除。
- [ 190 ] DELETED
- [Old ESI] DELETED
- [Old EBX] DELETED
- [Old EDI] DELETED
- [Old EBP] DELETED
- [Old EIP] DELETED
- [ 100 ] DELETED
- [ 90 ] DELETED
- [ESP, EBP]->[.......]
調用函數現在從 EAX 寄存器檢索返回值到 s 的內存位置。
- mov eax, 0x000002 ; // s 變量在內存中的位置
我們已經看到了內存中發生了什么以及如何將參數傳遞匯編代碼的函數。
調用函數之前,調用者將參數推入堆棧。因此,可以正確地說在 js 中傳遞參數是傳入值的一份拷貝。如果被調用函數更改了參數的值,它不會影響原始值,因為它存儲在其他地方,它只處理一個副本。
- function sum(num1) {
- num1 = 30
- }
- let n = 90
- sum(n)
- // `n` 仍然為 90
讓我們看看傳遞引用數據類型時會發生什么。
- function sum(num1) {
- num1 = { number:30 }
- }
- let n = { number:90 }
- sum(n)
- // `n` 仍然是 { number:90 }
用匯編代碼表示:
- n -> 0x002233
- Heap: Stack:
- 002254 012222
- ... 012223 0x002233
- 002240 012224
- 002239 012225
- 002238
- 002237
- 002236
- 002235
- 002234
- 002233 { number: 90 }
- 002232
- 002231 { number: 30 }
- Code:
- ...
- 000233 main: // entry point
- 000234 push n // n 值為 002233 ,它指向堆中存放 {number: 90} 地址。 n 被推到堆棧的 0x12223 處.
- 000235 ; // 保存所有寄存器
- ...
- 000239 call sum ; // 跳轉到內存中的`sum`函數
- 000240
- ...
- 000270 sum:
- 000271 ; // 創建對象 {number: 30} 內在地址主 0x002231
- 000271 mov 0x002231, (ebp+4) ; // 將內存地址為 0x002231 中 {number: 30} 移動到堆棧 (ebp+4)。(ebp+4)是地址 0x12223 ,即 n 所在地址也是對象 {number: 90} 在堆中的位置。這里,堆棧位置被值 0x002231 覆蓋。現在,num1 指向另一個內存地址。
- 000272 ; // 清理堆棧
- ...
- 000275 ret ; // 回到調用者所在的位置(000240)
我們在這里看到變量n保存了指向堆中其值的內存地址。 在sum 函數執行時,參數被推送到堆棧,由 sum 函數接收。
sum 函數創建另一個對象 {number:30},它存儲在另一個內存地址 002231 中,并將其放在堆棧的參數位置。 將前面堆棧上的參數位置的對象 {number:90} 的內存地址替換為新創建的對象 {number:30} 的內存地址。
這使得 n 保持不變。因此,復制引用策略是正確的。變量 n 被推入堆棧,從而在 sum 執行時成為 n 的副本。
此語句 num1 = {number:30} 在堆中創建了一個新對象,并將新對象的內存地址分配給參數 num1。 注意,在 num1 指向 n 之前,讓我們進行測試以驗證:
- // example1.js
- let n = { number: 90 }
- function sum(num1) {
- log(num1 === n)
- num1 = { number: 30 }
- log(num1 === n)
- }
- sum(n)
- $ node example1
- true
- false
是的,我們是對的。就像我們在匯編代碼中看到的那樣。最初,num1 引用與 n 相同的內存地址,因為n被推入堆棧。
然后在創建對象之后,將 num1 重新分配到對象實例的內存地址。
讓我們進一步修改我們的例子1:
- function sum(num1) {
- num1.number = 30
- }
- let n = { number: 90 }
- sum(n)
- // n 成為了 { number: 30 }
這將具有與前一個幾乎相同的內存模型和匯編語言。這里只有幾件事不太一樣。在 sum 函數實現中,沒有新的對象創建,該參數受到直接影響。
- ...
- 000270 sum:
- 000271 mov (ebp+4), eax ; // 將參數值復制到 eax 寄存器。eax 現在為 0x002233
- 000271 mov 30, [eax]; // 將 30 移動到 eax 指向的地址
num1 是(ebp+4),包含 n 的地址。值被復制到 eax 中,30 被復制到 eax 指向的內存中。任何寄存器上的花括號 [] 都告訴 CPU 不要使用寄存器中找到的值,而是獲取與其值對應的內存地址號的值。因此,檢索 0x002233 的 {number: 90} 值。
看看這樣的答案:
原始數據類型按值傳遞,對象通過引用的副本傳遞。
具體來說,當你傳遞一個對象(或數組)時,你無形地傳遞對該對象的引用,并且可以修改該對象的內容,但是如果你嘗試覆蓋該引用,它將不會影響該對象的副本- 即引用本身按值傳遞:
- function replace(ref) {
- ref = {}; // 這段代碼不影響傳遞的對象
- }
- function update(ref) {
- ref.key = 'newvalue'; // 這段代碼確實會影響對象的內容
- }
- var a = { key: 'value' };
- replace(a); // a 仍然有其原始值,它沒有被修改的
- update(a); // a 的內容被更改
從我們在匯編代碼和內存模型中看到的。這個答案***正確。在 replace 函數內部,它在堆中創建一個新對象,并將其分配給 ref 參數,a 對象內存地址被重寫。
update 函數引用 ref 參數中的內存地址,并更改存儲在存儲器地址中的對象的key屬性。
總結
根據我們上面看到的,我們可以說原始數據類型和引用數據類型的副本作為參數傳遞給函數。不同之處在于,在原始數據類型,它們只被它們的實際值引用。JS 不允許我們獲取他們的內存地址,不像在C與C++程序設計學習與實驗系統,引用數據類型指的是它們的內存地址。