中國移動研究院常耀斌:主流人工智能技術棧的深度探討和實踐總結
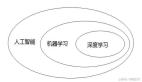
導語:這幾年人工智能技術之所以能夠獲得快速發展,主要是有三個元素的融合:神經元網絡、芯片以及大數據。人工智能是讓機器像人一樣思考甚至超越人類,而機器學習是實現人工智能的一種方法,它最基本的做法是使用算法來解析數據、從中學習,然后對真實世界中的事件做出決策和預測。深度學習又是機器學習的一種實現方式,它是模擬人神經網絡的方式,用更多的層數和神經元,給系統輸入海量的數據來訓練網絡。下面我以人工智能在醫療領域的平臺架構為例,進行五層模型技術棧的講解,分別是基礎數據層,計算引擎層,分析引擎層,應用引擎層和典型應用層,重點講解計算和分析引擎。

01
首先,探討一下人工智能平臺的計算引擎,目前最主流的五個大數據分布式計算框架包括Hadoop,Spark,Flink,Storm,Samaza。下面分別探討其優勢和應用場景。
1. Hadoop是***被商用的框架,在工業和產品界被廣泛認可。如果數據可以批量處理,可以被分割成小的處理任務,分發到計算集群,然后綜合計算結果,并且整個過程都是邏輯清晰,那么這個場景下很適合用Hadoop處理。
2. Spark是采用更先進的架構,其靈活性、易用性、性能等方面都比Hadoop更有優勢,有取代Hadoop的趨勢,但其穩定性需要大幅提高。
3. Flink既是批處理又是實時處理框架,但流處理還是放在***位的,Flink提供了一系列API,包括針對Java和Scala的流API,針對Java,Scala,Python的靜態數據API,以及在Java和Scala中嵌入SQL查詢的代碼。它也自帶機器學習和圖像處理包。
4. Storm是占領一定市場份額的分布式計算框架,其應用被設計成有向無環圖。被設計成容易處理***流,并且可用于任何編程語言。每個節點每秒處理上百萬個元組,高度可伸縮,提供任務處理保證。用Clojure寫的。可用于實時分析,分布式機器學習,以及大量別的情形,特別是數據流大的。Storm可以運行在YARN上,集成到Hadoop生態系統中。
5. Samza是由LinkedIn開源的一個分布式流處理框架,它是基于Kafka消息隊列來實現類實時的流式數據處理的,非常像Twitter的流處理系統Storm。不同的是Samza基于Hadoop,而且使用了LinkedIn的Kafka分布式消息系統,并使用資源管理器Apache Hadoop YARN實現容錯處理、處理器隔離、安全性和資源管理。
02
Spark是專為大規模數據處理而設計的快速通用的計算引擎,目前已經發行了2.4版本。Spark是UC Berkeley AMP lab所開源的類Hadoop MapReduce的通用并行框架,幾乎擁有Hadoop MapReduce所具有的優點,借助內存分布數據集,除了能夠提供交互式查詢外,還可以優化迭代工作負載。Spark今年發布的2.4,除了持續提升Spark的穩定性、易用性和性能之外,還擴展了Spark的生態圈,引入了Spark on K8s, 讓用戶多了一種部署Spark的方式,還引入了Pandas UDF,可以讓用戶在Spark上直接運行Pandas函數。我們分析其內核運行架構如下:
1. SparkContext引擎構建分析:
通常而言,用戶開發的Spark應用程序的提交與執行都離不開SparkContex的支持。在正式提交應用程序之前,首先需要初始化SparkContext。SparkContext隱藏了網絡通信、分布式部署、消息通信、存儲體系、計算引擎、度量系統、文件服務、Web UI等內容,應用程序開發者只需要使用SparkContext提供的API完成功能開發。
2. SparkEnv環境構建分析:
Spark執行環境SparkEnv是Spark中的Task運行所必需的組件。SparkEnv內部封裝了RPC環境(RpcEnv)、序列化管理器、廣播管理器(BroadcastManager)、map任務輸出跟蹤器(MapOutputTracker)、存儲體系、度量系統(MetricsSystem)、輸出提交協調器(OutputCommitCoordinator)等Task運行所需的各種組件。
3. 可交換的存儲體系分析:
Spark優先考慮使用各節點的內存作為存儲,當內存不足時才會考慮使用磁盤,這極大地減少了磁盤I/O,提升了任務執行的效率,使得Spark適用于實時計算、迭代計算、流式計算等場景。在實際場景中,有些Task是存儲密集型的,有些則是計算密集型的,所以有時候會造成存儲空間很空閑,而計算空間的資源又很緊張。Spark的內存存儲空間與執行存儲空間之間的邊界可以是“軟”邊界,因此資源緊張的一方可以借用另一方的空間,這既可以有效利用資源,又可以提高Task的執行效率。此外,Spark的內存空間還提供了Tungsten的實現,直接操作操作系統的內存。由于Tungsten省去了在堆內分配Java對象,因此能更加有效地利用系統的內存資源,并且因為直接操作系統內存,空間的分配和釋放也更迅速。
4. 雙級調度系統分析:
調度系統主要由DAGScheduler和TaskScheduler組成,它們都內置在SparkContext中。DAGScheduler負責創建Job、將DAG中的RDD劃分到不同的Stage、給Stage創建對應的Task、批量提交Task等功能。TaskScheduler負責按照FIFO或者FAIR等調度算法對批量Task進行調度;為Task分配資源;將Task發送到集群管理器的當前應用的Executor上,由Executor負責執行等工作。即使現在Spark增加了SparkSession和DataFrame等新的API,但這些新API的底層實際依然依賴于SparkContext。
5. 多維計算引擎分析:
計算引擎由內存管理器(MemoryManager)、Tungsten、任務內存管理器(TaskMemory-Manager)、Task、外部排序器(ExternalSorter)、Shuffle管理器(ShuffleManager)等組成。MemoryManager除了對存儲體系中的存儲內存提供支持和管理外,還為計算引擎中的執行內存提供支持和管理。Tungsten除用于存儲外,也可以用于計算或執行。TaskMemoryManager對分配給單個Task的內存資源進行更細粒度的管理和控制。ExternalSorter用于在map端或reduce端對ShuffleMapTask計算得到的中間結果進行排序、聚合等操作。ShuffleManager用于將各個分區對應的ShuffleMapTask產生的中間結果持久化到磁盤,并在reduce端按照分區遠程拉取ShuffleMapTask產生的中間結果。
6. 強大的SparkMLlib機器學習庫:
旨在簡化機器學習的工程實踐工作,并方便擴展到更大規模。MLlib由一些通用的學習算法和工具組成,包括分類、回歸、聚類、協同過濾、降維等,同時還包括底層的優化原語和高層的管道API。
然后,分析一下人工智能平臺分析引擎的處理過程。分析引擎的主要技術是機器學習和深度學習。機器學習框架涵蓋用于分類,回歸,聚類,異常檢測和數據準備的各種學習方法,也可以包括神經網絡方法。深度學習框架涵蓋具有許多隱藏層的各種神經網絡拓撲,包括模式識別的多步驟過程。網絡中的層越多,可以提取用于聚類和分類的特征越復雜。常見的深度學習框架有Caffe,CNTK,DeepLearning4j,Keras,MXNet和TensorFlow。其中Deeplearning4j是應用最廣泛的JVM開源深度學習工具,面向Java、Scala和Clojure用戶群。它旨在將深度學習引入生產棧,與Hadoop與Spark等主流大數據框架緊密集成。DL4J能處理圖像、文本、時間序列和聲音等所有主要數據類型,提供的算法包括卷積網絡、LSTM等循環網絡、Word2Vec和Doc2Vec等NLP工具以及各類自動編碼器。Deeplearning4j自帶內置Spark集成,用于處理在集群上開展的分布式神經網絡訓練,采用數據并行來將網絡訓練向外擴展至多臺計算機,每個節點靠一個(或四個)GPU運行。
03
深度學習框架的計算需要大量的圖像數據,數據從前端傳輸到后端進行預處理,然后進行標注,獲得訓練數據集。數據整理好之后,進行模型訓練,這是一個計算和通信非常密集的過程;模型訓練完之后,我們進行推理預測,其主要是一個前向計算過程。其需要對批量樣本的高吞吐高并發響應和單個樣本的低延時響應。下面以圖像識別的過程為例說明如下:
1. 數據的采集和獲取:
是通過物聯網傳感器,將光或聲音等信息轉化為電信息。信息可以是二維的圖象如文字、圖象等,可以是一維的波形如聲波、心電圖、腦電圖,也可以是物理量與邏輯值。
2. 數據預處理:
包括A\D、二值化、圖象的平滑、變換、增強、恢復、濾波等, 主要指圖象處理。
3. 特征抽取和選擇:
在模式識別中,需要進行特征的抽取和選擇,例如,一幅64x64的圖象可以得到4096個數據,這種在測量空間的原始數據通過變換獲得在特征空間最能反映分類本質的特征。這就是特征提取和選擇的過程。
4. 分類器設計:
分類器設計的主要功能是通過訓練確定判決規則,使按此類判決規則分類時,錯誤率***。
5. 分類決策:
在特征空間中對被識別對象進行分類。
***,探討人工智能平臺分析引擎的深度學習,它是如何針對多層神經網絡上運用各種機器學習算法解決圖像、文本等問題?深度學習從大類上可以歸入神經網絡,不過在具體實現上有許多變化。深度學習的核心是特征學習,旨在通過分層網絡獲取分層次的特征信息,從而解決以往需要人工設計特征的重要難題。深度學習是一個框架,包含多個重要算法: CNN卷積神經網絡、AutoEncoder自動編碼器、Sparse Coding稀疏編碼、RBM限制波爾茲曼機、DBN深信度網絡、RNN多層反饋循環神經網絡神經網絡,對于不同問題(圖像,語音,文本),需要選用不同網絡模型才能達到更好效果。
04
重點講一下卷積神經網絡,它就是至少包含一層的神經網絡,該層的功能是:計算輸入f與可配置的卷積核g的卷積,生成輸出。卷積的目的就是把卷積核應用到某個張量的所有點上,通過卷積核的滑動生成新的濾波后的張量。卷積的價值在于對輸入降維能力,通過降維改變卷積核的跨度strides參數實現。設置跨度是調整輸入張量維數的方法,strides參數格式與輸入向量相同,面臨挑戰:如果應對輸入在邊界,可以采用對圖像邊界填充方式。數據格式NHWC(數目,高度,寬度,通道數)。卷積核的作用常常是增強卷積核中心位置像素的灰度。卷積神經網絡CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。
由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特征抽取,而隱式地從訓練數據中進行學習;再者由于同一特征映射面上的神經元權值相同,所以網絡可以并行學習,這也是卷積網絡相對于神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有著獨特的優越性,其布局更接近于實際的生物神經網絡,權值共享降低了網絡的復雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。
激活函數:為神經網絡的輸入引入非線性,通過曲線能夠刻畫輸入中更為復雜的變化,設計模型常推薦tf.nn.relu,tf.sigmoid,tf.tanh,tf.nn.dropout,性能較為突出,評價一個激活函數是否有用的因素如下:單調,采用梯度下降法尋找局部極值點;可微分,保證任何一個點可以求導數,可以使梯度下降法用到激活函數的輸出上。模型的評價指標是敏感度、特異度和精度。靈敏度(敏感度,召回率recall,查全率sensitive)=TP/P =TPR;特異度(特效度specificity)=TN/N;精度(查準率,準確率precision)=TP/TP+FP。
總之,人工智能的框架時代已經成熟了,不是我們科學家和技術專家的主戰場,我們是要重新定義一些計算模型和算法實現,來創新網絡結構和訓練方法,這樣的深度學習算法會更加有效,能夠在普通的移動設備端工作,甚至不需要多余的硬件支持或抑制內存開銷,會觸發人工智能技術進入大規模商用階段,人工智能產品全面進入消費級市場。
【本文為51CTO專欄作者“移動Labs”原創稿件,轉載請聯系原作者】