一篇超實(shí)用的服務(wù)異常處理指南
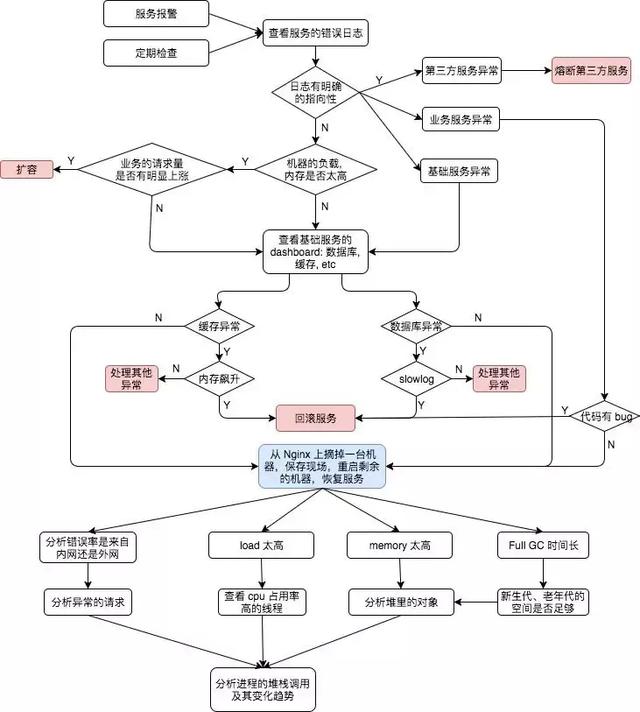
1. 服務(wù)異常的處理流程
2. 負(fù)載
2.1 查看機(jī)器 cpu 的負(fù)載
top -b -n 1 |grep java|awk '{print "VIRT:"$5,"RES:"$6,"cpu:"$9"%","mem:"$10"%"}'
2.2 查找 cpu 占用率高的線程
- top -p 25603 -H
- printf 0x%x 25842
- jstack 25603 | grep 0x64f2
- cat /proc/interrupts
(1)CPU
(2)Memory
(3)IO
(4)Network
可以從以下幾個(gè)方面監(jiān)控CPU的信息:
(1)中斷;
(2)上下文切換;
(3)可運(yùn)行隊(duì)列;
(4)CPU 利用率。
3. 內(nèi)存
3.1 系統(tǒng)內(nèi)存
free 命令
- [root@server ~]# free
- total used free shared buffers cached
- Mem: 3266180 3250000 10000 0 201000 3002000
- -/+ buffers/cache: 47000 3213000
- Swap: 2048276 80160 1968116
這里的默認(rèn)顯示單位是 kb。
各項(xiàng)指標(biāo)解釋
- total:總計(jì)物理內(nèi)存的大小。
- used:已使用多大。
- free:可用有多少。
- Shared:多個(gè)進(jìn)程共享的內(nèi)存總額。
- buffers: 磁盤緩存的大小。
- cache:磁盤緩存的大小。
- -/+ buffers/cached): used:已使用多大,free:可用有多少。
- 已用內(nèi)存 = 系統(tǒng)used memory - buffers - cached
- (47000 = 3250000-201000-3002000)
- 可用內(nèi)存 = 系統(tǒng)free memory + buffers + cached
- (3213000 = 10000+201000+3002000)
什么是buffer/cache?
- buffer 指 Linux 內(nèi)存的:Buffer cache,緩沖區(qū)緩
- cache 指 Linux內(nèi)存中的:Page cache,頁面緩存
page cache
page cache 主要用來作為文件系統(tǒng)上的文件數(shù)據(jù)的緩存來用,尤其是針對(duì)當(dāng)進(jìn)程對(duì)文件有 read/write 操作的時(shí)候。
如果你仔細(xì)想想的話,作為可以映射文件到內(nèi)存的系統(tǒng)調(diào)用:mmap是不是很自然的也應(yīng)該用到 page cache?在當(dāng)前的系統(tǒng)實(shí)現(xiàn)里,page cache 也被作為其它文件類型的緩存設(shè)備來用,所以事實(shí)上 page cache 也負(fù)責(zé)了大部分的塊設(shè)備文件的緩存工作。
buffer cache
buffer cache 主要用來在系統(tǒng)對(duì)塊設(shè)備進(jìn)行讀寫的時(shí)候,對(duì)塊進(jìn)行數(shù)據(jù)緩存的系統(tǒng)來使用。這意味著某些對(duì)塊的操作會(huì)使用 buffer cache 進(jìn)行緩存,比如我們?cè)诟袷交募到y(tǒng)的時(shí)候。
一般情況下兩個(gè)緩存系統(tǒng)是一起配合使用的,比如當(dāng)我們對(duì)一個(gè)文件進(jìn)行寫操作的時(shí)候,page cache 的內(nèi)容會(huì)被改變,而 buffer cache 則可以用來將 page 標(biāo)記為不同的緩沖區(qū),并記錄是哪一個(gè)緩沖區(qū)被修改了。這樣,內(nèi)核在后續(xù)執(zhí)行臟數(shù)據(jù)的回寫(writeback)時(shí),就不用將整個(gè) page 寫回,而只需要寫回修改的部分即可。
在當(dāng)前的內(nèi)核中,page cache 是針對(duì)內(nèi)存頁的緩存,說白了就是,如果有內(nèi)存是以page進(jìn)行分配管理的,都可以使用page cache作為其緩存來管理使用。
當(dāng)然,不是所有的內(nèi)存都是以頁(page)進(jìn)行管理的,也有很多是針對(duì)塊(block)進(jìn)行管理的,這部分內(nèi)存使用如果要用到 cache 功能,則都集中到 buffer cache中來使用。(從這個(gè)角度出發(fā),是不是buffer cache改名叫做block cache更好?)然而,也不是所有塊(block)都有固定長度,系統(tǒng)上塊的長度主要是根據(jù)所使用的塊設(shè)備決定的,而頁長度在X86 上無論是 32位還是 64位都是 4k。
3.2 進(jìn)程內(nèi)存
3.2.1 進(jìn)程內(nèi)存統(tǒng)計(jì)
/proc/[pid]/status
通過/proc//status可以查看進(jìn)程的內(nèi)存使用情況,包括虛擬內(nèi)存大小(VmSize),物理內(nèi)存大小(VmRSS),數(shù)據(jù)段大小(VmData),棧的大小(VmStk),代碼段的大小(VmExe),共享庫的代碼段大小(VmLib)等等。
- Name: gedit /*進(jìn)程的程序名*/
- State: S (sleeping) /*進(jìn)程的狀態(tài)信息,具體參見http://blog.chinaunix.net/u2/73528/showart_1106510.html*/
- Tgid: 9744 /*線程組號(hào)*/
- Pid: 9744 /*進(jìn)程pid*/
- PPid: 7672 /*父進(jìn)程的pid*/
- TracerPid: 0 /*跟蹤進(jìn)程的pid*/
- VmPeak: 60184 kB /*進(jìn)程地址空間的大小*/
- VmSize: 60180 kB /*進(jìn)程虛擬地址空間的大小reserved_vm:進(jìn)程在預(yù)留或特殊的內(nèi)存間的物理頁*/
- VmLck: 0 kB /*進(jìn)程已經(jīng)鎖住的物理內(nèi)存的大小.鎖住的物理內(nèi)存不能交換到硬盤*/
- VmHWM: 18020 kB /*文件內(nèi)存映射和匿名內(nèi)存映射的大小*/
- VmRSS: 18020 kB /*應(yīng)用程序正在使用的物理內(nèi)存的大小,就是用ps命令的參數(shù)rss的值 (rss)*/
- VmData: 12240 kB /*程序數(shù)據(jù)段的大小(所占虛擬內(nèi)存的大小),存放初始化了的數(shù)據(jù)*/
- VmStk: 84 kB /*進(jìn)程在用戶態(tài)的棧的大小*/
- VmExe: 576 kB /*程序所擁有的可執(zhí)行虛擬內(nèi)存的大小,代碼段,不包括任務(wù)使用的庫 */
- VmLib: 21072 kB /*被映像到任務(wù)的虛擬內(nèi)存空間的庫的大小*/
- VmPTE: 56 kB /*該進(jìn)程的所有頁表的大小*/
- Threads: 1 /*共享使用該信號(hào)描述符的任務(wù)的個(gè)數(shù)*/
3.2.2 JVM 內(nèi)存分配
java內(nèi)存組成介紹:堆(Heap)和非堆(Non-heap)內(nèi)存
按照官方的說法:“Java 虛擬機(jī)具有一個(gè)堆,堆是運(yùn)行時(shí)數(shù)據(jù)區(qū)域,所有類實(shí)例和數(shù)組的內(nèi)存均從此處分配。堆是在 Java 虛擬機(jī)啟動(dòng)時(shí)創(chuàng)建的。” “在JVM中堆之外的內(nèi)存稱為非堆內(nèi)存(Non-heap memory)”。
可以看出JVM主要管理兩種類型的內(nèi)存:堆和非堆。
簡單來說堆就是Java代碼可及的內(nèi)存,是留給開發(fā)人員使用的;非堆就是JVM留給自己用的。
所以方法區(qū)、JVM內(nèi)部處理或優(yōu)化所需的內(nèi)存(如JIT編譯后的代碼緩存)、每個(gè)類結(jié)構(gòu)(如運(yùn)行時(shí)常數(shù)池、字段和方法數(shù)據(jù))以及方法和構(gòu)造方法 的代碼都在非堆內(nèi)存中。
- JVM 本身需要的內(nèi)存,包括其加載的第三方庫以及這些庫分配的內(nèi)存
- NIO 的 DirectBuffer 是分配的 native memory
- 內(nèi)存映射文件,包括 JVM 加載的一些 JAR 和第三方庫,以及程序內(nèi)部用到的。上面 pmap 輸出的內(nèi)容里,有一些靜態(tài)文件所占用的大小不在 Java 的 heap 里,因此作為一個(gè)Web服務(wù)器,趕緊把靜態(tài)文件從這個(gè)Web服務(wù)器中人移開吧,放到nginx或者CDN里去吧。
- JIT, JVM會(huì)將Class編譯成native代碼,這些內(nèi)存也不會(huì)少,如果使用了Spring的AOP,CGLIB會(huì)生成更多的類,JIT的內(nèi)存開銷也會(huì)隨之變大,而且Class本身JVM的GC會(huì)將其放到Perm Generation里去,很難被回收掉,面對(duì)這種情況,應(yīng)該讓JVM使用ConcurrentMarkSweep GC,并啟用這個(gè)GC的相關(guān)參數(shù)允許將不使用的class從Perm Generation中移除, 參數(shù)配置:
- -XX:+UseConcMarkSweepGC -X:+CMSPermGenSweepingEnabled -X:+CMSClassUnloadingEnabled,如果不需要移除而Perm Generation空間不夠,可以加大一點(diǎn):-X:PermSize=256M -X:MaxPermSize=512M
- JNI,一些JNI接口調(diào)用的native庫也會(huì)分配一些內(nèi)存,如果遇到JNI庫的內(nèi)存泄露,可以使用valgrind等內(nèi)存泄露工具來檢測(cè)
- 線程棧,每個(gè)線程都會(huì)有自己的棧空間,如果線程一多,這個(gè)的開銷就很明顯了
- jmap/jstack 采樣,頻繁的采樣也會(huì)增加內(nèi)存占用,如果你有服務(wù)器健康監(jiān)控,記得這個(gè)頻率別太高,否則健康監(jiān)控變成致病監(jiān)控了。
1.方法區(qū)
也稱”***代” 、“非堆”,它用于存儲(chǔ)虛擬機(jī)加載的類信息、常量、靜態(tài)變量、是各個(gè)線程共享的內(nèi)存區(qū)域。默認(rèn)最小值為 16 MB,***值為 64 MB,可以通過-XX: PermSize 和 -XX: MaxPermSize 參數(shù)限制方法區(qū)的大小。
運(yùn)行時(shí)常量池:是方法區(qū)的一部分,Class文件中除了有類的版本、字段、方法、接口等描述信息外,還有一項(xiàng)信息是常量池,用于存放編譯器生成的各種符號(hào)引用,這部分內(nèi)容將在類加載后放到方法區(qū)的運(yùn)行時(shí)常量池中。
2.虛擬機(jī)棧
描述的是java 方法執(zhí)行的內(nèi)存模型:每個(gè)方法被執(zhí)行的時(shí)候 都會(huì)創(chuàng)建一個(gè)“棧幀”用于存儲(chǔ)局部變量表(包括參數(shù))、操作棧、方法出口等信息。
每個(gè)方法被調(diào)用到執(zhí)行完的過程,就對(duì)應(yīng)著一個(gè)棧幀在虛擬機(jī)棧中從入棧到出棧的過程。聲明周期與線程相同,是線程私有的。
局部變量表存放了編譯器可知的各種基本數(shù)據(jù)類型(boolean、byte、char、short、int、float、long、double)、對(duì)象引用(引用指針,并非對(duì)象本身),其中64位長度的long和double類型的數(shù)據(jù)會(huì)占用2個(gè)局部變量的空間,其余數(shù)據(jù)類型只占1個(gè)。
局部變量表所需的內(nèi)存空間在編譯期間完成分配,當(dāng)進(jìn)入一個(gè)方法時(shí),這個(gè)方法需要在棧幀中分配多大的局部變量是完全確定的,在運(yùn)行期間棧幀不會(huì)改變局部變量表的大小空間。
3.本地方法棧
與虛擬機(jī)棧基本類似,區(qū)別在于虛擬機(jī)棧為虛擬機(jī)執(zhí)行的java方法服務(wù),而本地方法棧則是為Native方法服務(wù)。
4.堆
也叫做java 堆、GC堆是java虛擬機(jī)所管理的內(nèi)存中***的一塊內(nèi)存區(qū)域,也是被各個(gè)線程共享的內(nèi)存區(qū)域,在JVM啟動(dòng)時(shí)創(chuàng)建。
該內(nèi)存區(qū)域存放了對(duì)象實(shí)例及數(shù)組(所有 new 的對(duì)象)。其大小通過 -Xms (最小值) 和 -Xmx (***值) 參數(shù)設(shè)置,-Xms為 JVM 啟動(dòng)時(shí)申請(qǐng)的最小內(nèi)存,默認(rèn)為操作系統(tǒng)物理內(nèi)存的 1/64 但小于 1G;
-Xmx 為 JVM 可申請(qǐng)的***內(nèi)存,默認(rèn)為物理內(nèi)存的1/4但小于 1G,默認(rèn)當(dāng)空余堆內(nèi)存小于 40% 時(shí),JVM 會(huì)增大 Heap 到 -Xmx 指定的大小,可通過 -XX:MinHeapFreeRation= 來指定這個(gè)比列;
當(dāng)空余堆內(nèi)存大于70%時(shí),JVM 會(huì)減小 heap 的大小到 -Xms 指定的大小,可通過XX:MaxHeapFreeRation= 來指定這個(gè)比列,對(duì)于運(yùn)行系統(tǒng),為避免在運(yùn)行時(shí)頻繁調(diào)整 Heap 的大小,通常 -Xms 與 -Xmx 的值設(shè)成一樣。
由于現(xiàn)在收集器都是采用分代收集算法,堆被劃分為新生代和老年代。新生代主要存儲(chǔ)新創(chuàng)建的對(duì)象和尚未進(jìn)入老年代的對(duì)象。老年代存儲(chǔ)經(jīng)過多次新生代GC(Minor GC)任然存活的對(duì)象。
5.程序計(jì)數(shù)器
是最小的一塊內(nèi)存區(qū)域,它的作用是當(dāng)前線程所執(zhí)行的字節(jié)碼的行號(hào)指示器,在虛擬機(jī)的模型里,字節(jié)碼解釋器工作時(shí)就是通過改變這個(gè)計(jì)數(shù)器的值來選取下一條需要執(zhí)行的字節(jié)碼指令,分支、循環(huán)、異常處理、線程恢復(fù)等基礎(chǔ)功能都需要依賴計(jì)數(shù)器完成。
3.2.3 直接內(nèi)存
直接內(nèi)存并不是虛擬機(jī)內(nèi)存的一部分,也不是Java虛擬機(jī)規(guī)范中定義的內(nèi)存區(qū)域。jdk1.4中新加入的NIO,引入了通道與緩沖區(qū)的IO方式,它可以調(diào)用Native方法直接分配堆外內(nèi)存,這個(gè)堆外內(nèi)存就是本機(jī)內(nèi)存,不會(huì)影響到堆內(nèi)存的大小。
3.2.4 JVM 內(nèi)存分析
查看 JVM 堆內(nèi)存情況
jmap -heap [pid]
- [root@server ~]$ jmap -heap 837
- Attaching to process ID 837, please wait...
- Debugger attached successfully.
- Server compiler detected.
- JVM version is 24.71-b01
- using thread-local object allocation.
- Parallel GC with 4 thread(s)//GC 方式
- Heap Configuration: //堆內(nèi)存初始化配置
- MinHeapFreeRatio = 0 //對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:MinHeapFreeRatio設(shè)置JVM堆最小空閑比率(default 40)
- MaxHeapFreeRatio = 100 //對(duì)應(yīng)jvm啟動(dòng)參數(shù) -XX:MaxHeapFreeRatio設(shè)置JVM堆***空閑比率(default 70)
- MaxHeapSize = 2082471936 (1986.0MB) //對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:MaxHeapSize=設(shè)置JVM堆的***大小
- NewSize = 1310720 (1.25MB)//對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:NewSize=設(shè)置JVM堆的‘新生代’的默認(rèn)大小
- MaxNewSize = 17592186044415 MB//對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:MaxNewSize=設(shè)置JVM堆的‘新生代’的***大小
- OldSize = 5439488 (5.1875MB)//對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:OldSize=<value>:設(shè)置JVM堆的‘老生代’的大小
- NewRatio = 2 //對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:NewRatio=:‘新生代’和‘老生代’的大小比率
- SurvivorRatio = 8 //對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:SurvivorRatio=設(shè)置年輕代中Eden區(qū)與Survivor區(qū)的大小比值
- PermSize = 21757952 (20.75MB) //對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:PermSize=<value>:設(shè)置JVM堆的‘永生代’的初始大小
- MaxPermSize = 85983232 (82.0MB)//對(duì)應(yīng)jvm啟動(dòng)參數(shù)-XX:MaxPermSize=<value>:設(shè)置JVM堆的‘永生代’的***大小
- G1HeapRegionSize = 0 (0.0MB)
- Heap Usage://堆內(nèi)存使用情況
- PS Young Generation
- Eden Space://Eden區(qū)內(nèi)存分布
- capacity = 33030144 (31.5MB)//Eden區(qū)總?cè)萘?/span>
- used = 1524040 (1.4534378051757812MB) //Eden區(qū)已使用
- free = 31506104 (30.04656219482422MB) //Eden區(qū)剩余容量
- 4.614088270399305% used //Eden區(qū)使用比率
- From Space: //其中一個(gè)Survivor區(qū)的內(nèi)存分布
- capacity = 5242880 (5.0MB)
- used = 0 (0.0MB)
- free = 5242880 (5.0MB)
- 0.0% used
- To Space: //另一個(gè)Survivor區(qū)的內(nèi)存分布
- capacity = 5242880 (5.0MB)
- used = 0 (0.0MB)
- free = 5242880 (5.0MB)
- 0.0% used
- PS Old Generation //當(dāng)前的Old區(qū)內(nèi)存分布
- capacity = 86507520 (82.5MB)
- used = 0 (0.0MB)
- free = 86507520 (82.5MB)
- 0.0% used
- PS Perm Generation//當(dāng)前的 “永生代” 內(nèi)存分布
- capacity = 22020096 (21.0MB)
- used = 2496528 (2.3808746337890625MB)
- free = 19523568 (18.619125366210938MB)
- 11.337498256138392% used
- 670 interned Strings occupying 43720 bytes.
關(guān)于這里的幾個(gè)generation網(wǎng)上資料一大把就不細(xì)說了,這里算一下求和可以得知前者總共給Java環(huán)境分配了644M的內(nèi)存,而ps輸出的VSZ和RSS分別是7.4G和2.9G,這到底是怎么回事呢?
前面jmap輸出的內(nèi)容里,MaxHeapSize 是在命令行上配的,-Xmx4096m,這個(gè)java程序可以用到的***堆內(nèi)存。
VSZ是指已分配的線性空間大小,這個(gè)大小通常并不等于程序?qū)嶋H用到的內(nèi)存大小,產(chǎn)生這個(gè)的可能性很多,比如內(nèi)存映射,共享的動(dòng)態(tài)庫,或者向系統(tǒng)申請(qǐng)了更多的堆,都會(huì)擴(kuò)展線性空間大小,要查看一個(gè)進(jìn)程有哪些內(nèi)存映射,可以使用 pmap 命令來查看:
pmap -x [pid]
- [root@server ~]$ pmap -x 837
- 837: java
- Address Kbytes RSS Dirty Mode Mapping
- 0000000040000000 36 4 0 r-x-- java
- 0000000040108000 8 8 8 rwx-- java
- 00000000418c9000 13676 13676 13676 rwx-- [ anon ]
- 00000006fae00000 83968 83968 83968 rwx-- [ anon ]
- 0000000700000000 527168 451636 451636 rwx-- [ anon ]
- 00000007202d0000 127040 0 0 ----- [ anon ]
- ...
- ...
- 00007f55ee124000 4 4 0 r-xs- az.png
- 00007fff017ff000 4 4 0 r-x-- [ anon ]
- ffffffffff600000 4 0 0 r-x-- [ anon ]
- ---------------- ------ ------ ------
- total kB 7796020 3037264 3023928
這里可以看到很多anon,這些表示這塊內(nèi)存是由mmap分配的。
RSZ是Resident Set Size,常駐內(nèi)存大小,即進(jìn)程實(shí)際占用的物理內(nèi)存大小, 在現(xiàn)在這個(gè)例子當(dāng)中,RSZ和實(shí)際堆內(nèi)存占用差了2.3G,這2.3G的內(nèi)存組成分別為:
查看 JVM 堆各個(gè)分區(qū)的內(nèi)存情況
jstat -gcutil [pid]
- [root@server ~]$ jstat -gcutil 837 1000 20
- S0 S1 E O P YGC YGCT FGC FGCT GCT
- 0.00 80.43 24.62 87.44 98.29 7101 119.652 40 19.719 139.371
- 0.00 80.43 33.14 87.44 98.29 7101 119.652 40 19.719 139.371
分析 JVM 堆內(nèi)存中的對(duì)象
查看存活的對(duì)象統(tǒng)計(jì)
jmap -histo:live [pid]
dump 內(nèi)存
jmap -dump:format=b,file=heapDump [pid]
然后用jhat命令可以參看
jhat -port 5000 heapDump
在瀏覽器中訪問:http://localhost:5000/ 查看詳細(xì)信息
4. 服務(wù)指標(biāo)
4.1 響應(yīng)時(shí)間(RT)
響應(yīng)時(shí)間是指系統(tǒng)對(duì)請(qǐng)求作出響應(yīng)的時(shí)間。直觀上看,這個(gè)指標(biāo)與人對(duì)軟件性能的主觀感受是非常一致的,因?yàn)樗暾赜涗浟苏麄€(gè)計(jì)算機(jī)系統(tǒng)處理請(qǐng)求的時(shí)間。
由于一個(gè)系統(tǒng)通常會(huì)提供許多功能,而不同功能的處理邏輯也千差萬別,因而不同功能的響應(yīng)時(shí)間也不盡相同,甚至同一功能在不同輸入數(shù)據(jù)的情況下響應(yīng)時(shí)間也不相同。
所以,在討論一個(gè)系統(tǒng)的響應(yīng)時(shí)間時(shí),人們通常是指該系統(tǒng)所有功能的平均時(shí)間或者所有功能的***響應(yīng)時(shí)間。
當(dāng)然,往往也需要對(duì)每個(gè)或每組功能討論其平均響應(yīng)時(shí)間和***響應(yīng)時(shí)間。
對(duì)于單機(jī)的沒有并發(fā)操作的應(yīng)用系統(tǒng)而言,人們普遍認(rèn)為響應(yīng)時(shí)間是一個(gè)合理且準(zhǔn)確的性能指標(biāo)。需要指出的是,響應(yīng)時(shí)間的絕對(duì)值并不能直接反映軟件的性能的高低,軟件性能的高低實(shí)際上取決于用戶對(duì)該響應(yīng)時(shí)間的接受程度。
對(duì)于一個(gè)游戲軟件來說,響應(yīng)時(shí)間小于100毫秒應(yīng)該是不錯(cuò)的,響應(yīng)時(shí)間在1秒左右可能屬于勉強(qiáng)可以接受,如果響應(yīng)時(shí)間達(dá)到3秒就完全難以接受了。
而對(duì)于編譯系統(tǒng)來說,完整編譯一個(gè)較大規(guī)模軟件的源代碼可能需要幾十分鐘甚至更長時(shí)間,但這些響應(yīng)時(shí)間對(duì)于用戶來說都是可以接受的。
4.2 吞吐量(Throughput)
吞吐量是指系統(tǒng)在單位時(shí)間內(nèi)處理請(qǐng)求的數(shù)量。對(duì)于無并發(fā)的應(yīng)用系統(tǒng)而言,吞吐量與響應(yīng)時(shí)間成嚴(yán)格的反比關(guān)系,實(shí)際上此時(shí)吞吐量就是響應(yīng)時(shí)間的倒數(shù)。
前面已經(jīng)說過,對(duì)于單用戶的系統(tǒng),響應(yīng)時(shí)間(或者系統(tǒng)響應(yīng)時(shí)間和應(yīng)用延遲時(shí)間)可以很好地度量系統(tǒng)的性能,但對(duì)于并發(fā)系統(tǒng),通常需要用吞吐量作為性能指標(biāo)。
對(duì)于一個(gè)多用戶的系統(tǒng),如果只有一個(gè)用戶使用時(shí)系統(tǒng)的平均響應(yīng)時(shí)間是t,當(dāng)有你n個(gè)用戶使用時(shí),每個(gè)用戶看到的響應(yīng)時(shí)間通常并不是n×t,而往往比n×t小很多(當(dāng)然,在某些特殊情況下也可能比n×t大,甚至大很多)。
這是因?yàn)樘幚砻總€(gè)請(qǐng)求需要用到很多資源,由于每個(gè)請(qǐng)求的處理過程中有許多不走難以并發(fā)執(zhí)行,這導(dǎo)致在具體的一個(gè)時(shí)間點(diǎn),所占資源往往并不多。也就是說在處理單個(gè)請(qǐng)求時(shí),在每個(gè)時(shí)間點(diǎn)都可能有許多資源被閑置,當(dāng)處理多個(gè)請(qǐng)求時(shí),如果資源配置合理,每個(gè)用戶看到的平均響應(yīng)時(shí)間并不隨用戶數(shù)的增加而線性增加。
實(shí)際上,不同系統(tǒng)的平均響應(yīng)時(shí)間隨用戶數(shù)增加而增長的速度也不大相同,這也是采用吞吐量來度量并發(fā)系統(tǒng)的性能的主要原因。
一般而言,吞吐量是一個(gè)比較通用的指標(biāo),兩個(gè)具有不同用戶數(shù)和用戶使用模式的系統(tǒng),如果其***吞吐量基本一致,則可以判斷兩個(gè)系統(tǒng)的處理能力基本一致。
4.3 并發(fā)用戶數(shù)
并發(fā)用戶數(shù)是指系統(tǒng)可以同時(shí)承載的正常使用系統(tǒng)功能的用戶的數(shù)量。與吞吐量相比,并發(fā)用戶數(shù)是一個(gè)更直觀但也更籠統(tǒng)的性能指標(biāo)。
實(shí)際上,并發(fā)用戶數(shù)是一個(gè)非常不準(zhǔn)確的指標(biāo),因?yàn)橛脩舨煌氖褂媚J綍?huì)導(dǎo)致不同用戶在單位時(shí)間發(fā)出不同數(shù)量的請(qǐng)求。
一網(wǎng)站系統(tǒng)為例,假設(shè)用戶只有注冊(cè)后才能使用,但注冊(cè)用戶并不是每時(shí)每刻都在使用該網(wǎng)站,因此具體一個(gè)時(shí)刻只有部分注冊(cè)用戶同時(shí)在線,在線用戶就在瀏覽網(wǎng)站時(shí)會(huì)花很多時(shí)間閱讀網(wǎng)站上的信息,因而具體一個(gè)時(shí)刻只有部分在線用戶同時(shí)向系統(tǒng)發(fā)出請(qǐng)求。
這樣,對(duì)于網(wǎng)站系統(tǒng)我們會(huì)有三個(gè)關(guān)于用戶數(shù)的統(tǒng)計(jì)數(shù)字:注冊(cè)用戶數(shù)、在線用戶數(shù)和同時(shí)發(fā)請(qǐng)求用戶數(shù)。由于注冊(cè)用戶可能長時(shí)間不登陸網(wǎng)站,使用注冊(cè)用戶數(shù)作為性能指標(biāo)會(huì)造成很大的誤差。而在線用戶數(shù)和同事發(fā)請(qǐng)求用戶數(shù)都可以作為性能指標(biāo)。
相比而言,以在線用戶作為性能指標(biāo)更直觀些,而以同時(shí)發(fā)請(qǐng)求用戶數(shù)作為性能指標(biāo)更準(zhǔn)確些。
4.4 QPS每秒查詢率(Query Per Second)
每秒查詢率QPS是對(duì)一個(gè)特定的查詢服務(wù)器在規(guī)定時(shí)間內(nèi)所處理流量多少的衡量標(biāo)準(zhǔn),在因特網(wǎng)上,作為域名系統(tǒng)服務(wù)器的機(jī)器的性能經(jīng)常用每秒查詢率來衡量。對(duì)應(yīng)fetches/sec,即每秒的響應(yīng)請(qǐng)求數(shù),也即是***吞吐能力。
從以上概念來看吞吐量和響應(yīng)時(shí)間是衡量系統(tǒng)性能的重要指標(biāo),QPS雖然和吞吐量的計(jì)量單位不同,但應(yīng)該是成正比的,任何一個(gè)指標(biāo)都可以含量服務(wù)器的并行處理能力。當(dāng)然Throughput更關(guān)心數(shù)據(jù)量,QPS更關(guān)心處理筆數(shù)。
4.5 CPU利用率
CPU Load Average < CPU個(gè)數(shù) 核數(shù) 0.7
Context Switch Rate
就是Process(Thread)的切換,如果切換過多,會(huì)讓CPU忙于切換,也會(huì)導(dǎo)致影響吞吐量。
《高性能服務(wù)器架構(gòu) 》這篇文章的第2節(jié)就是說的是這個(gè)問題的。
究竟多少算合適?google 了一大圈,沒有一個(gè)確切的解釋。
Context Switch大體上由兩個(gè)部分組成:中斷和進(jìn)程(包括線程)切換,一次中斷(Interrupt)會(huì)引起一次切換,進(jìn)程(線程)的創(chuàng)建、激活之類的也會(huì)引起一次切換。CS的值也和TPS(Transaction Per Second)相關(guān)的,假設(shè)每次調(diào)用會(huì)引起N次CS,那么就可以得出
Context Switch Rate = Interrupt Rate + TPS* N
CSR減掉IR,就是進(jìn)程/線程的切換,假如主進(jìn)程收到請(qǐng)求交給線程處理,線程處理完畢歸還給主進(jìn)程,這里就是2次切換。
也可以用CSR、IR、TPS的值代入公式中,得出每次事物導(dǎo)致的切換數(shù)。因此,要降低CSR,就必須在每個(gè)TPS引起的切換上下功夫,只有N這個(gè)值降下去,CSR就能降低,理想情況下N=0,但是無論如何如果N >= 4,則要好好檢查檢查。另外網(wǎng)上說的CSR<5000,我認(rèn)為標(biāo)準(zhǔn)不該如此單一。
這三個(gè)指標(biāo)在 LoadRunner 中可以監(jiān)控到;另外,在 linux 中,也可以用 vmstat 查看r(Load Arerage),in(Interrupt)和cs(Context Switch)
5. 工具
uptime
dmesg
top
查看進(jìn)程活動(dòng)狀態(tài)以及一些系統(tǒng)狀況
vmstat
查看系統(tǒng)狀態(tài)、硬件和系統(tǒng)信息等
iostat
查看CPU 負(fù)載,硬盤狀況
sar
綜合工具,查看系統(tǒng)狀況
mpstat
查看多處理器狀況
netstat
查看網(wǎng)絡(luò)狀況
iptraf
實(shí)時(shí)網(wǎng)絡(luò)狀況監(jiān)測(cè)
tcpdump
抓取網(wǎng)絡(luò)數(shù)據(jù)包,詳細(xì)分析
mpstat
查看多處理器狀況
tcptrace
數(shù)據(jù)包分析工具
netperf
網(wǎng)絡(luò)帶寬工具
dstat
綜合工具,綜合了 vmstat, iostat, ifstat, netstat 等多個(gè)信息