怎樣才能減少軟件中的Bug?數據顯示程序員才是制造 Bug 的“元兇”
代碼的 Bug 到底與什么有關?代碼的行數?項目的規模?還是開發者的人數?在本文中,將基于機器學習模型繪制的圖形,告訴你諸多 Bug 的由來!
以下為譯文:
怎樣才能減少軟件中的Bug?本文將告訴你傳統觀點是錯誤的,下列數據會讓你感到驚訝。
軟件開發人員普遍認為,代碼量越大Bug就越多。雖然許多人并不是很清楚這兩者之間的確切關系,但他們認為二者是線性的關系,即每千行代碼中的Bug數與代碼量成正比。然而,根據對GitHub中10萬個代碼庫的研究發現,代碼行數與Bug之間并不存在這種恒定的關系。而且,代碼行數并不是Bug數的可靠指標。
注:在本文中,我用“bug”來指代軟件中從一些從用戶的角度來看的異常行為,例如:死機、視覺異常、不正確的數據等。“Bug”也常用于描述軟件中可利用的缺陷,但這是從黑客的角度來看。本文不涉及安全漏洞,因為安全漏洞可能需要別的模型來分析。
相反,我們發現了兩個更可靠的指標:貢獻代碼的開發人員數量和提交代碼的次數。本文中的圖片使用了一個擁有兩個變量的模型,而且這個模型在預測Bug數目時,與我另一個擁有16個變量的模型表現幾乎相同。我會詳細解釋這些模型的建模過程,但是首先:
如果存在這種因果關系,那么這對減少Bug意味著什么?
如果你需要可靠的軟件,那么請不要使用會產生Bug的方法論。例如,敏捷主張直接寫代碼,然后通過迭代這些代碼來優化需求,所以會產生很多提交(而提交次數與bug數息息相關)。
原型可以減少bug,但是你必須在使用完后丟棄這些原型。你需要通過數次提交來學習技術和客戶的需求,然后編寫一個非原型版本,其中包含更少量的提交次數和/或更小的團隊。
刻意保障系統可靠性的工作可能會產生相反的效果。在采用測試驅動的開發和單元測試的情況下,如果提交的代碼次數,或需要的開發人員的話,那么bug數也會,這可能與你的直覺恰恰相反。
對于個人而言,你應該將時間花費在寫代碼之外的事情上,例如思考、設計、和制作原型等等。
對于企業而言,雇傭的開發人員數量越少越好,當然開發人員的經驗越多越好。
收集數據
首先,我通過GitHub API,查詢了10萬個項目(超過135顆星的項目)。這些項目并不是隨機抽樣,它們占據了GitHub上高端0.1%,所以我們更加自信會有很多人發現和報告bug。對于每個項目,我提取了項目的創建日期(GitHub上的日期),給星數量,問題數量,提交PR的次數,以及issue tracker是否被禁用。
接下來,我克隆了所有非私有的代碼庫,并直接從Git和文件系統收集了以下統計信息:

我針對每個代碼庫的HEAD信息,收集了Tokei的統計信息:每種檢測到的語言的代碼行數、注釋、空格等等。然后,對于每種Tokei檢測到的語言,我計算了總字節數和LZMA壓縮后的字節數。
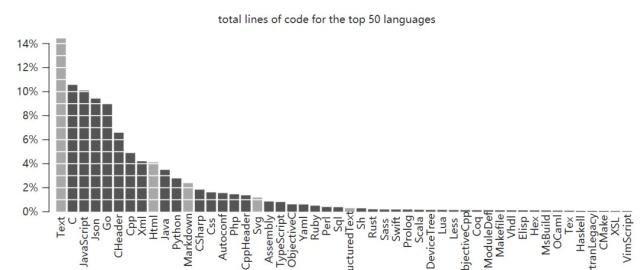
排名前50的總代碼行數。被排除的語言(文本和標記)用灰色顯示(Text、Html、Markdown、Sg、ReStructuredText)
控制受歡迎度等差異
我們以為,舊項目和受歡迎項目的平均bug數會更偏高。為了控制這些差異以及其他差異,我使用了如下模型:
ln(issues) = β1created age + β2first commit age + β3ln(stars) + β4ln(contributors) + β5ln(all commits) +β6ln(code) + β7ln(comments + 1) + β8ln(pull requests + 1) + β9ln(files) + ε
我通過這個模型做了擬合,并通過10折交叉驗證測試了模型與線性回歸的擬合度,然后在一個組合圖中繪制了每個折疊的預測誤差。在此之前,我刪除了所有私有、歸檔、鏡像和分叉項目,沒有啟用issue tracker的項目,以及數據集中bug數為零的項目。
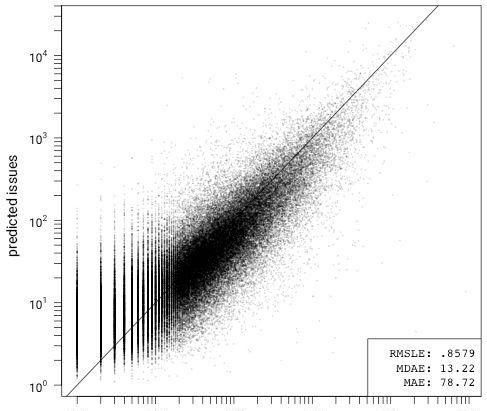
9個變量模型的預測誤差
這個模型有一些偏差,但其他方面的擬合度還不錯。它高估了GitHub上問題數量很少(<10)的項目的bug數(相反低估了問題數量偏高的項目)。我懷疑這是由于github的api中沒有將分叉項目標記出來,還有一些包含第三方代碼的項目導致的。這些項目夸大了與issue>
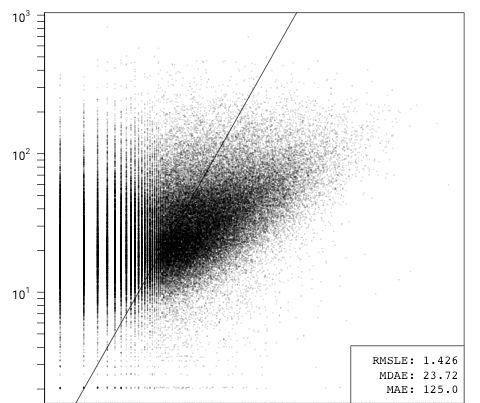
ln(issues) = β1ln(code) + ε
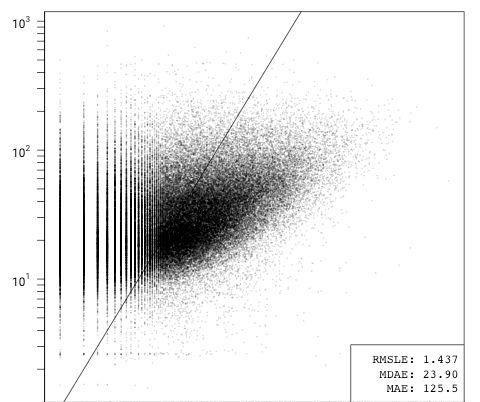
ln(issues) = β1ln(lzma bytes) + ε
僅包含代碼行或lzma壓縮的代碼字節的模型(說明了語言之間代碼密度的差異)表現同樣糟糕。
用9個變量的模型擬合完整的數據集后,得出了以下近似值:
ln(issues) = 0.022created age – 0.017first commit age + 0.315ln(stars) + 0.071ln(contributors) + 0.266ln(all commits) +0.072ln(code) + 0.034ln(comments + 1) + 0.413ln(pull requests + 1) – 0.069ln(files) – 1.690
我們可以看出,模型中的主導變量是PR數(0.413)、給星數(0.315)和提交次數(0.266)。將這二者與代碼行數(0.072)和注釋(0.034)相比較,就會發現這些差異更加明顯,尤其是再考慮到變量尚未規范化,而且幾乎所有項目中代碼行數都會高于PR數、給星數或提交次數。
由于PR數和給星數是GitHub特有的功能,我還構建了一個沒有這兩個數據項的模型。然后,根據擬合模型的系數,再進一步將其簡化為只包含提交代碼的人數和提交次數。這種只有3個變量的模型的表現幾乎與其他模型完全相同,而且還可以顯示成3G圖形:
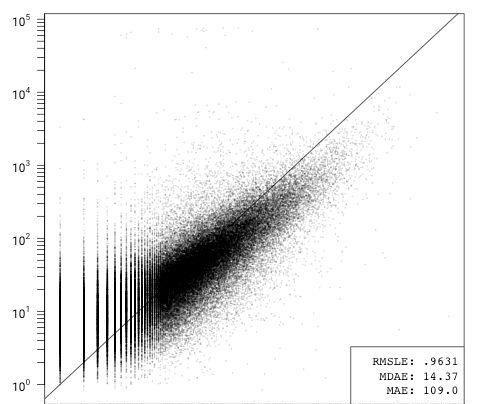
ln(issues) = β1first commit age + β2ln(contributors) + β3ln(all commits) + β4ln(code) + β5ln(comments + 1) + β6ln(files) + ε
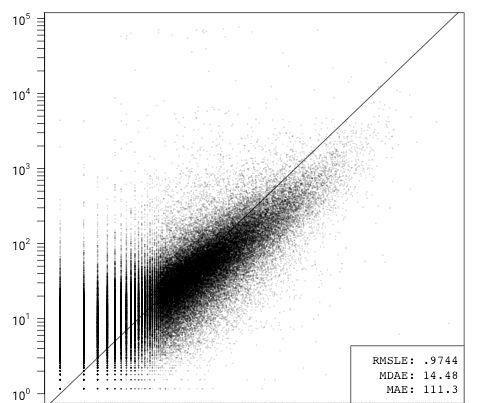
ln(issues) = β1ln(contributors) + β2ln(all commits) + ε
在刪除了GitHub特有的數據項后,提交代碼的人數和提交次數就占據了主導地位,從刪除所有其他變量時錯誤數輕微的減少就可以看出。
會不會是這個模型搞錯了?
現在我們知道了提交代碼的人數和提交次數的影響,下面我們來看看,如果不采用任何根據提交代碼的人數和提交次數繪制圖形的模型,那么代碼行數與問題數量之間有何關系。
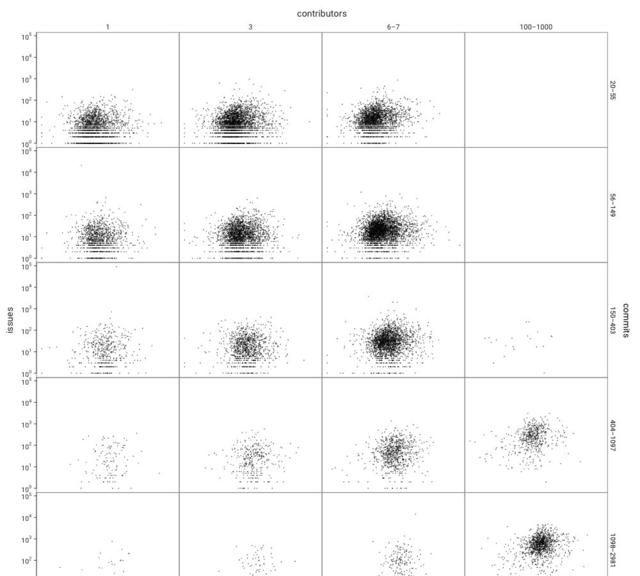
針對GitHub,繪制代碼行數(x軸)與GitHub上的問題數(y軸)的關系圖,并根據提交代碼的人數和提交次數分組。
為了節省空間,我沒有顯示所有的10萬個項目。我按照提交代碼的人數和提交次數進行了分組,因為我覺得這種分組方式最有意思,且具代表性。為了避免選擇偏差,我只在選擇分組之后進行繪圖。
你只看到了一團團雜亂的點,對吧?這就對了:上圖證實了代碼行數與bug數之間的關聯性非常弱。而且請記住,這些圖是用對數繪制的,而且這個模型使用的是ln(code)(代碼行數的對數):因為相關性會隨著代碼行數的大小而變化。
隨著代碼行數的增加,bug數卻增長緩慢
我見過有人說每千行代碼的bug數在0.5-50個。但是我發現得出這樣的結論的人只研究了1-2個成熟的軟件項目在某一個時間點或兩個版本之間的代碼。只查看某個項目在一個時間點的快照,憑什么認為這個項目在早期或后期的情況會保持不變?
根據上述數據,認為bug數和代碼行數之間存在任何常量的關系是不明智的。相反,我們應該認識到bug數目增長的速度會隨著項目的成熟而越來越慢。原因是了什么?我認為:
我們觀察到的頻率呈對數分布,而不是正常分布。一小部分bug能被更快、更頻繁地發現,而系統中處于“長尾”的bug發現速度和頻率要低得多。
bug數量與功能數有關,而跟代碼行數無關,而代碼行數與功能數呈超線性分布。(隨著項目的增長,添加新功能所需的代碼行數會增加。)
項目的核心應該隨著時間的推移變得更加穩定,因為我們會修復bug,但不會做出重大改變。隨著項目的成熟,新來的開發人員不太可能改動關鍵的代碼,而且新功能的開發需要的核心變化更少。
那么哪些不是問題的bug和不是bug的問題呢?
對于這種大小和范圍的研究,GitHub的issue是我所知道的記錄bug的形式。自動bug檢測軟件僅適用于某些語言,而且只能檢測到“結構性”的bug(比如無效的內存訪問),而卻無法檢測到邏輯錯誤(例如錯誤的計算),而且手動統計bug數是不切實際的(或者根本不可能)。我們必須假設處于開放狀態的issue能夠代表用戶遇到的bug數。
異常值和替代假設
在查看這些數據之前,我沒有猜到僅靠提交代碼的人數就可以預測bug數。這表明項目的開發人員數量蘊含了有關項目的其他大量信息。一種合理的解釋是“大型開發團隊有向平均數回歸的趨勢”:即隨著團隊開發人員數量的增加,項目的提交次數/功能/代碼行數與開發人數的比率傾向于一個平均值。
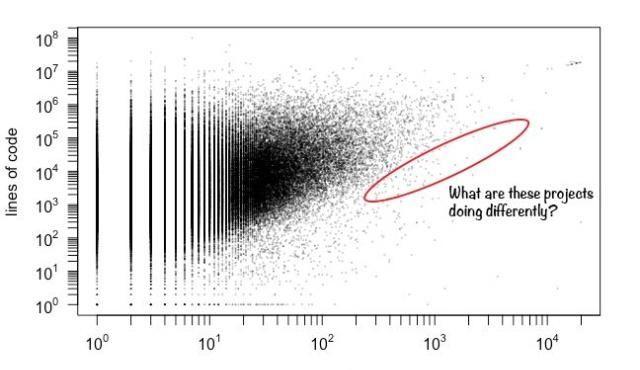
隨著開發人員數量的增加,代碼行數的范圍變窄。
在瀏覽異常值時,我遇到了一個特別有趣的類別:游戲機模擬器。該類軟件擁有測試輸入(游戲),測試人員(游戲玩家)和其他實現(其他模擬器和系統本身)等數據,可以為將來的軟件bug數的比較研究提供更加可控的實驗環境。