













關于/dev/urandom 的流言終結
有很多關于 /dev/urandom 和 /dev/random 的流言在坊間不斷流傳。然而流言終究是流言。
本篇文章里針對的都是近來的 Linux 操作系統,其它類 Unix 操作系統不在討論范圍內。
/dev/urandom 不安全。加密用途必須使用 /dev/random
事實:/dev/urandom 才是類 Unix 操作系統下推薦的加密種子。
/dev/urandom 是偽隨機數生成器(PRND),而 /dev/random 是“真”隨機數生成器。
事實:它們兩者本質上用的是同一種 CSPRNG (一種密碼學偽隨機數生成器)。它們之間細微的差別和“真”“不真”隨機完全無關。(參見:“Linux 隨機數生成器的構架”一節)
/dev/random 在任何情況下都是密碼學應用更好地選擇。即便 /dev/urandom 也同樣安全,我們還是不應該用它。
事實:/dev/random 有個很惡心人的問題:它是阻塞的。(參見:“阻塞有什么問題?”一節)(LCTT 譯注:意味著請求都得逐個執行,等待前一個請求完成)
但阻塞不是好事嗎!/dev/random 只會給出電腦收集的信息熵足以支持的隨機量。/dev/urandom 在用完了所有熵的情況下還會不斷吐出不安全的隨機數給你。
事實:這是誤解。就算我們不去考慮應用層面后續對隨機種子的用法,“用完信息熵池”這個概念本身就不存在。僅僅 256 位的熵就足以生成計算上安全的隨機數很長、很長的一段時間了。(參見:“那熵池快空了的情況呢?”一節)
問題的關鍵還在后頭:/dev/random 怎么知道有系統會多少可用的信息熵?接著看!
但密碼學家老是討論重新選種子(re-seeding)。這難道不和上一條沖突嗎?
事實:你說的也沒錯!某種程度上吧。確實,隨機數生成器一直在使用系統信息熵的狀態重新選種。但這么做(一部分)是因為別的原因。(參見:“重新選種”一節)
這樣說吧,我沒有說引入新的信息熵是壞的。更多的熵肯定更好。我只是說在熵池低的時候阻塞是沒必要的。
好,就算你說的都對,但是 /dev/(u)random 的 man 頁面和你說的也不一樣啊!到底有沒有專家同意你說的這堆啊?
事實:其實 man 頁面和我說的不沖突。它看似好像在說 /dev/urandom 對密碼學用途來說不安全,但如果你真的理解這堆密碼學術語你就知道它說的并不是這個意思。(參見:“random 和 urandom 的 man 頁面”一節)
man 頁面確實說在一些情況下推薦使用 /dev/random (我覺得也沒問題,但絕對不是說必要的),但它也推薦在大多數“一般”的密碼學應用下使用 /dev/urandom 。
雖然訴諸權威一般來說不是好事,但在密碼學這么嚴肅的事情上,和專家統一意見是很有必要的。
所以說呢,還確實有一些專家和我的一件事一致的:/dev/urandom 就應該是類 UNIX 操作系統下密碼學應用的選擇。顯然的,是他們的觀點說服了我而不是反過來的。(參見:“正道”一節)
難以相信嗎?覺得我肯定錯了?讀下去看我能不能說服你。
我嘗試不講太高深的東西,但是有兩點內容必須先提一下才能讓我們接著論證觀點。
首當其沖的,什么是隨機性,或者更準確地:我們在探討什么樣的隨機性?(參見:“真隨機”一節)
另外一點很重要的是,我沒有嘗試以說教的態度對你們寫這段話。我寫這篇文章是為了日后可以在討論起的時候指給別人看。比 140 字長。這樣我就不用一遍遍重復我的觀點了。能把論點磨煉成一篇文章本身就很有助于將來的討論。(參見:“你是在說我笨?!”一節)
并且我非常樂意聽到不一樣的觀點。但我只是認為單單地說 /dev/urandom 壞是不夠的。你得能指出到底有什么問題,并且剖析它們。
你是在說我笨?!
絕對沒有!
事實上我自己也相信了 “/dev/urandom 是不安全的” 好些年。這幾乎不是我們的錯,因為那么德高望重的人在 Usenet、論壇跟我們重復這個觀點。甚至連 man 手冊都似是而非地說著。我們當年怎么可能鄙視諸如“信息熵太低了”這種看上去就很讓人信服的觀點呢?(參見:“random 和 urandom 的 man 頁面”一節)
整個流言之所以如此廣為流傳不是因為人們太蠢,而是因為但凡有點關于信息熵和密碼學概念的人都會覺得這個說法很有道理。直覺似乎都在告訴我們這流言講的很有道理。很不幸直覺在密碼學里通常不管用,這次也一樣。
真隨機
隨機數是“真正隨機”是什么意思?
我不想搞的太復雜以至于變成哲學范疇的東西。這種討論很容易走偏因為對于隨機模型大家見仁見智,討論很快變得毫無意義。
在我看來“真隨機”的“試金石”是量子效應。一個光子穿過或不穿過一個半透鏡。或者觀察一個放射性粒子衰變。這類東西是現實世界最接近真隨機的東西。當然,有些人也不相信這類過程是真隨機的,或者這個世界根本不存在任何隨機性。這個就百家爭鳴了,我也不好多說什么了。
密碼學家一般都會通過不去討論什么是“真隨機”來避免這種哲學辯論。他們更關心的是不可預測性。只要沒有任何方法能猜出下一個隨機數就可以了。所以當你以密碼學應用為前提討論一個隨機數好不好的時候,在我看來這才是最重要的。
無論如何,我不怎么關心“哲學上安全”的隨機數,這也包括別人嘴里的“真”隨機數。
兩種安全,一種有用
但就讓我們退一步說,你有了一個“真”隨機變量。你下一步做什么呢?
你把它們打印出來然后掛在墻上來展示量子宇宙的美與和諧?牛逼!我支持你。
但是等等,你說你要用它們?做密碼學用途?額,那這就廢了,因為這事情就有點復雜了。
事情是這樣的,你的真隨機、量子力學加護的隨機數即將被用進不理想的現實世界算法里去。
因為我們使用的幾乎所有的算法都并不是信息論安全性的。它們“只能”提供計算意義上的安全。我能想到為數不多的例外就只有 Shamir 密鑰分享和一次性密碼本(OTP)算法。并且就算前者是名副其實的(如果你實際打算用的話),后者則毫無可行性可言。
但所有那些大名鼎鼎的密碼學算法,AES、RSA、Diffie-Hellman、橢圓曲線,還有所有那些加密軟件包,OpenSSL、GnuTLS、Keyczar、你的操作系統的加密 API,都僅僅是計算意義上安全的。
那區別是什么呢?信息論安全的算法肯定是安全的,絕對是,其它那些的算法都可能在理論上被擁有計算力的窮舉破解。我們依然愉快地使用它們是因為全世界的計算機加起來都不可能在宇宙年齡的時間里破解,至少現在是這樣。而這就是我們文章里說的“不安全”。
除非哪個聰明的家伙破解了算法本身 —— 在只需要更少量計算力、在今天可實現的計算力的情況下。這也是每個密碼學家夢寐以求的圣杯:破解 AES 本身、破解 RSA 本身等等。
所以現在我們來到了更底層的東西:隨機數生成器,你堅持要“真隨機”而不是“偽隨機”。但是沒過一會兒你的真隨機數就被喂進了你極為鄙視的偽隨機算法里了!
真相是,如果我們哈希算法被破解了,或者分組加密算法被破解了,你得到的這些“哲學上不安全”的隨機數甚至無所謂了,因為反正你也沒有安全的應用方法了。
所以把計算性上安全的隨機數喂給你的僅僅是計算性上安全的算法就可以了,換而言之,用 /dev/urandom。
Linux 隨機數生成器的構架
一種錯誤的看法
你對內核的隨機數生成器的理解很可能是像這樣的:
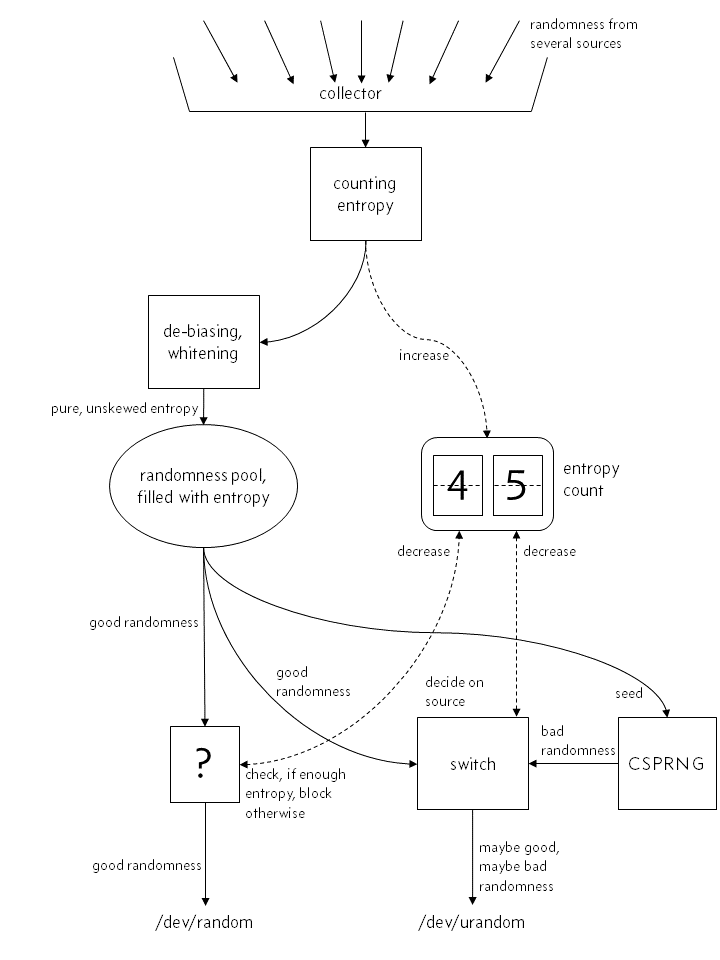
image: mythical structure of the kernel's random number generator
“真正的隨機性”,盡管可能有點瑕疵,進入操作系統然后它的熵立刻被加入內部熵計數器。然后經過“矯偏”和“漂白”之后它進入內核的熵池,然后 /dev/random 和 /dev/urandom 從里面生成隨機數。
“真”隨機數生成器,/dev/random,直接從池里選出隨機數,如果熵計數器表示能滿足需要的數字大小,那就吐出數字并且減少熵計數。如果不夠的話,它會阻塞程序直至有足夠的熵進入系統。
這里很重要一環是 /dev/random 幾乎只是僅經過必要的“漂白”后就直接把那些進入系統的隨機性吐了出來,不經扭曲。
而對 /dev/urandom 來說,事情是一樣的。除了當沒有足夠的熵的時候,它不會阻塞,而會從一直在運行的偽隨機數生成器(當然,是密碼學安全的,CSPRNG)里吐出“低質量”的隨機數。這個 CSPRNG 只會用“真隨機數”生成種子一次(或者好幾次,這不重要),但你不能特別相信它。
在這種對隨機數生成的理解下,很多人會覺得在 Linux 下盡量避免 /dev/urandom 看上去有那么點道理。
因為要么你有足夠多的熵,你會相當于用了 /dev/random。要么沒有,那你就會從幾乎沒有高熵輸入的 CSPRNG 那里得到一個低質量的隨機數。
看上去很邪惡是吧?很不幸的是這種看法是完全錯誤的。實際上,隨機數生成器的構架更像是下面這樣的。
更好地簡化
Linux 4.8 之前
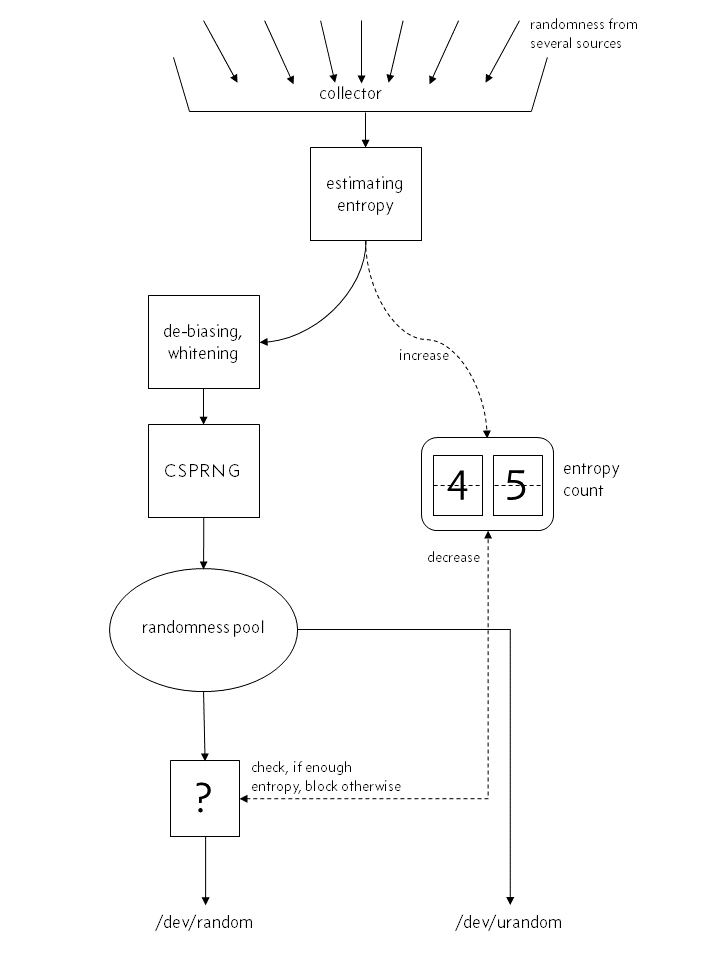
image: actual structure of the kernel's random number generator before Linux 4.8
你看到區別了嗎?CSPRNG 并不是和隨機數生成器一起跑的,它在 /dev/urandom 需要輸出但熵不夠的時候進行填充。CSPRNG 是整個隨機數生成過程的內部組件之一。從來就沒有什么 /dev/random 直接從池里輸出純純的隨機性。每個隨機源的輸入都在 CSPRNG 里充分混合和散列過了,這一切都發生在實際變成一個隨機數,被 /dev/urandom 或者 /dev/random 吐出去之前。
另外一個重要的區別是這里沒有熵計數器的任何事情,只有預估。一個源給你的熵的量并不是什么很明確能直接得到的數字。你得預估它。注意,如果你太樂觀地預估了它,那 /dev/random 最重要的特性——只給出熵允許的隨機量——就蕩然無存了。很不幸的,預估熵的量是很困難的。
這是個很粗糙的簡化。實際上不僅有一個,而是三個熵池。一個主池,另一個給
/dev/random,還有一個給/dev/urandom,后兩者依靠從主池里獲取熵。這三個池都有各自的熵計數器,但二級池(后兩個)的計數器基本都在 0 附近,而“新鮮”的熵總在需要的時候從主池流過來。同時還有好多混合和回流進系統在同時進行。整個過程對于這篇文檔來說都過于復雜了,我們跳過。
Linux 內核只使用事件的到達時間來預估熵的量。根據模型,它通過多項式插值來預估實際的到達時間有多“出乎意料”。這種多項式插值的方法到底是不是好的預估熵量的方法本身就是個問題。同時硬件情況會不會以某種特定的方式影響到達時間也是個問題。而所有硬件的取樣率也是個問題,因為這基本上就直接決定了隨機數到達時間的顆粒度。
至少現在看來,內核的熵預估還是不錯的。這也意味著它比較保守。有些人會具體地討論它有多好,這都超出我的腦容量了。就算這樣,如果你堅持不想在沒有足夠多的熵的情況下吐出隨機數,那你看到這里可能還會有一絲緊張。我睡的就很香了,因為我不關心熵預估什么的。
要明確一下:/dev/random 和 /dev/urandom 都是被同一個 CSPRNG 飼喂的。只有它們在用完各自熵池(根據某種預估標準)的時候,它們的行為會不同:/dev/random 阻塞,/dev/urandom 不阻塞。
Linux 4.8 以后
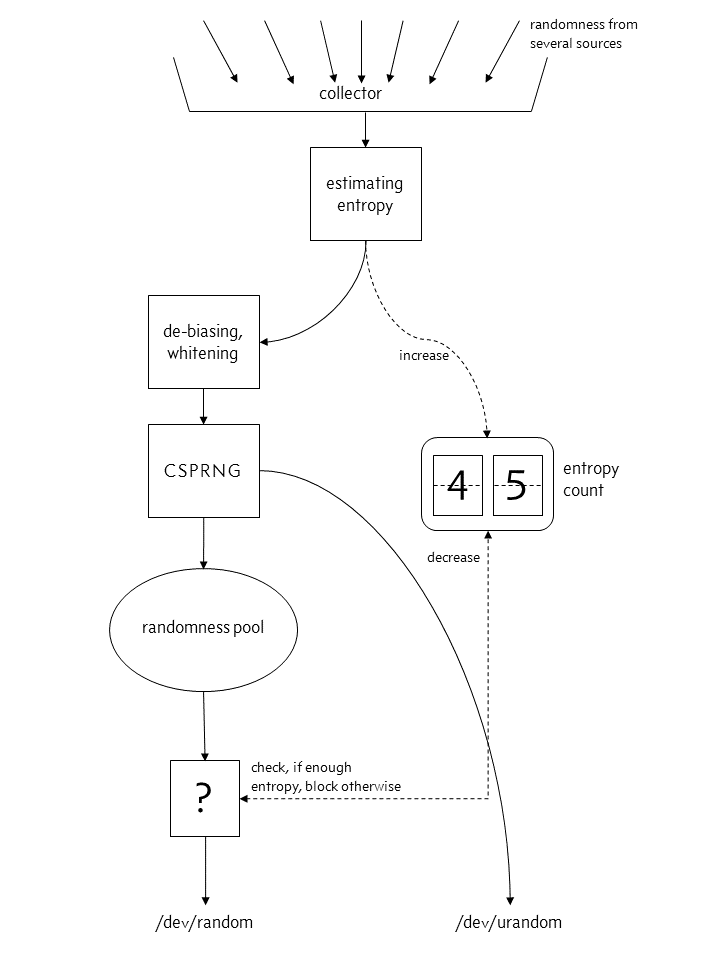
image: actual structure of the kernel's random number generator from Linux 4.8 onward
在 Linux 4.8 里,/dev/random 和 /dev/urandom 的等價性被放棄了。現在 /dev/urandom 的輸出不來自于熵池,而是直接從 CSPRNG 來。
我們很快會理解為什么這不是一個安全問題。(參見:“CSPRNG 沒問題”一節)
阻塞有什么問題?
你有沒有需要等著 /dev/random 來吐隨機數?比如在虛擬機里生成一個 PGP 密鑰?或者訪問一個在生成會話密鑰的網站?
這些都是問題。阻塞本質上會降低可用性。換而言之你的系統不干你讓它干的事情。不用我說,這是不好的。要是它不干活你干嘛搭建它呢?
我在工廠自動化里做過和安全相關的系統。猜猜看安全系統失效的主要原因是什么?操作問題。就這么簡單。很多安全措施的流程讓工人惱火了。比如時間太長,或者太不方便。你要知道人很會找捷徑來“解決”問題。
但其實有個更深刻的問題:人們不喜歡被打斷。它們會找一些繞過的方法,把一些詭異的東西接在一起僅僅因為這樣能用。一般人根本不知道什么密碼學什么亂七八糟的,至少正常的人是這樣吧。
為什么不禁止調用 random()?為什么不隨便在論壇上找個人告訴你用寫奇異的 ioctl 來增加熵計數器呢?為什么不干脆就把 SSL 加密給關了算了呢?
到頭來如果東西太難用的話,你的用戶就會被迫開始做一些降低系統安全性的事情——你甚至不知道它們會做些什么。
我們很容易會忽視可用性之類的重要性。畢竟安全重要對吧?所以比起犧牲安全,不可用、難用、不方便都是次要的?
這種二元對立的想法是錯的。阻塞不一定就安全了。正如我們看到的,/dev/urandom 直接從 CSPRNG 里給你一樣好的隨機數。用它不好嗎!
CSPRNG 沒問題
現在情況聽上去很慘淡。如果連高質量的 /dev/random 都是從一個 CSPRNG 里來的,我們怎么敢在高安全性的需求上使用它呢?
實際上,“看上去隨機”是現存大多數密碼學基礎組件的基本要求。如果你觀察一個密碼學哈希的輸出,它一定得和隨機的字符串不可區分,密碼學家才會認可這個算法。如果你生成一個分組加密,它的輸出(在你不知道密鑰的情況下)也必須和隨機數據不可區分才行。
如果任何人能比暴力窮舉要更有效地破解一個加密,比如它利用了某些 CSPRNG 偽隨機的弱點,那這就又是老一套了:一切都廢了,也別談后面的了。分組加密、哈希,一切都是基于某個數學算法,比如 CSPRNG。所以別害怕,到頭來都一樣。
那熵池快空了的情況呢?
毫無影響。
加密算法的根基建立在黑客不能預測輸出上,只要最一開始有足夠的隨機性(熵)就行了。“足夠”的下限可以是 256 位,不需要更多了。
介于我們一直在很隨意的使用“熵”這個概念,我用“位”來量化隨機性希望讀者不要太在意細節。像我們之前討論的那樣,內核的隨機數生成器甚至沒法精確地知道進入系統的熵的量。只有一個預估。而且這個預估的準確性到底怎么樣也沒人知道。
重新選種
但如果熵這么不重要,為什么還要有新的熵一直被收進隨機數生成器里呢?
djb 提到 太多的熵甚至可能會起到反效果。
首先,一般不會這樣。如果你有很多隨機性可以拿來用,用就對了!
但隨機數生成器時不時要重新選種還有別的原因:
想象一下如果有個黑客獲取了你隨機數生成器的所有內部狀態。這是最壞的情況了,本質上你的一切都暴露給黑客了。
你已經涼了,因為黑客可以計算出所有未來會被輸出的隨機數了。
但是,如果不斷有新的熵被混進系統,那內部狀態會再一次變得隨機起來。所以隨機數生成器被設計成這樣有些“自愈”能力。
但這是在給內部狀態引入新的熵,這和阻塞輸出沒有任何關系。
random 和 urandom 的 man 頁面
這兩個 man 頁面在嚇唬程序員方面很有建樹:
從
/dev/urandom讀取數據不會因為需要更多熵而阻塞。這樣的結果是,如果熵池里沒有足夠多的熵,取決于驅動使用的算法,返回的數值在理論上有被密碼學破解的可能性。發動這樣的步驟并沒有出現在任何公開文獻當中,但從理論上講是可能存在的。如果你的應用擔心這類情況,你應該使用/dev/random。實際上已經有
/dev/random和/dev/urandom的 Linux 內核 man 頁面的更新版本。不幸的是,隨便一個網絡搜索出現我在結果頂部的仍然是舊的、有缺陷的版本。此外,許多 Linux 發行版仍在發布舊的 man 頁面。所以不幸的是,這一節需要在這篇文章中保留更長的時間。我很期待刪除這一節!
沒有“公開的文獻”描述,但是 NSA 的小賣部里肯定賣這種威脅手段是吧?如果你真的真的很擔心(你應該很擔心),那就用 /dev/random 然后所有問題都沒了?
然而事實是,可能某個什么情報局有這種方式,或者某個什么邪惡黑客組織找到了方法。但如果我們就直接假設這種威脅一定存在也是不合理的。
而且就算你想給自己一個安心,我要給你潑個冷水:AES、SHA-3 或者其它什么常見的加密算法也沒有“公開文獻記述”的手段。難道你也不用這幾個加密算法了?這顯然是可笑的。
我們在回到 man 頁面說:“使用 /dev/random”。我們已經知道了,雖然 /dev/urandom 不阻塞,但是它的隨機數和 /dev/random 都是從同一個 CSPRNG 里來的。
如果你真的需要信息論安全性的隨機數(你不需要的,相信我),那才有可能成為一個你需要等足夠熵進入 CSPRNG 的理由。而且你也不能用 /dev/random。
man 頁面有毒,就這樣。但至少它還稍稍挽回了一下自己:
如果你不確定該用
/dev/random還是/dev/urandom,那你可能應該用后者。通常來說,除了需要長期使用的 GPG/SSL/SSH 密鑰以外,你總該使用/dev/urandom。該手冊頁的當前更新版本毫不含糊地說:
/dev/random接口被認為是遺留接口,并且/dev/urandom在所有用例中都是足夠的,除了在啟動早期需要隨機性的應用程序;對于這些應用程序,必須替代使用getrandom(2),因為它將阻塞,直到熵池初始化完成。
行。我覺得沒必要,但如果你真的要用 /dev/random 來生成 “長期使用的密鑰”,用就是了也沒人攔著!你可能需要等幾秒鐘或者敲幾下鍵盤來增加熵,但這沒什么問題。
但求求你們,不要就因為“你想更安全點”就讓連個郵件服務器要掛起半天。
正道
本篇文章里的觀點顯然在互聯網上是“小眾”的。但如果問一個真正的密碼學家,你很難找到一個認同阻塞 /dev/random 的人。
比如我們看看 Daniel Bernstein(即著名的 djb)的看法:
我們密碼學家對這種胡亂迷信行為表示不負責。你想想,寫
/dev/randomman 頁面的人好像同時相信:
- (1) 我們不知道如何用一個 256 位長的
/dev/random的輸出來生成一個隨機密鑰串流(這是我們需要/dev/urandom吐出來的),但與此同時- (2) 我們卻知道怎么用單個密鑰來加密一條消息(這是 SSL,PGP 之類干的事情)
對密碼學家來說這甚至都不好笑了
或者 Thomas Pornin 的看法,他也是我在 stackexchange 上見過最樂于助人的一位:
簡單來說,是的。展開說,答案還是一樣。
/dev/urandom生成的數據可以說和真隨機完全無法區分,至少在現有科技水平下。使用比/dev/urandom“更好的“隨機性毫無意義,除非你在使用極為罕見的“信息論安全”的加密算法。這肯定不是你的情況,不然你早就說了。urandom 的 man 頁面多多少少有些誤導人,或者干脆可以說是錯的——特別是當它說
/dev/urandom會“用完熵”以及 “/dev/random是更好的”那幾句話;
或者 Thomas Ptacek 的看法,他不設計密碼算法或者密碼學系統,但他是一家名聲在外的安全咨詢公司的創始人,這家公司負責很多滲透和破解爛密碼學算法的測試:
用 urandom。用 urandom。用 urandom。用 urandom。用 urandom。
/dev/urandom問題分兩層:
在 Linux 上,不像 FreeBSD,/dev/urandom 永遠不阻塞。記得安全性取決于某個最一開始決定的隨機性?種子?
Linux 的 /dev/urandom 會很樂意給你吐點不怎么隨機的隨機數,甚至在內核有機會收集一丁點熵之前。什么時候有這種情況?當你系統剛剛啟動的時候。
FreeBSD 的行為更正確點:/dev/random 和 /dev/urandom 是一樣的,在系統啟動的時候 /dev/random 會阻塞到有足夠的熵為止,然后它們都再也不阻塞了。
與此同時 Linux 實行了一個新的系統調用,最早由 OpenBSD 引入叫
getentrypy(2),在 Linux 下這個叫getrandom(2)。這個系統調用有著上述正確的行為:阻塞到有足夠的熵為止,然后再也不阻塞了。當然,這是個系統調用,而不是一個字節設備(LCTT 譯注:不在/dev/下),所以它在 shell 或者別的腳本語言里沒那么容易獲取。這個系統調用 自 Linux 3.17 起存在。
在 Linux 上其實這個問題不太大,因為 Linux 發行版會在啟動的過程中保存一點隨機數(這發生在已經有一些熵之后,因為啟動程序不會在按下電源的一瞬間就開始運行)到一個種子文件中,以便系統下次啟動的時候讀取。所以每次啟動的時候系統都會從上一次會話里帶一點隨機性過來。
顯然這比不上在關機腳本里寫入一些隨機種子,因為這樣的顯然就有更多熵可以操作了。但這樣做顯而易見的好處就是它不用關心系統是不是正確關機了,比如可能你系統崩潰了。
而且這種做法在你真正啟動系統的時候也沒法幫你隨機,不過好在 Linux 系統安裝程序一般會保存一個種子文件,所以基本上問題不大。
虛擬機是另外一層問題。因為用戶喜歡克隆它們,或者恢復到某個之前的狀態。這種情況下那個種子文件就幫不到你了。
但解決方案依然和用 /dev/random 沒關系,而是你應該正確的給每個克隆或者恢復的鏡像重新生成種子文件。
太長不看
別問,問就是用 /dev/urandom !














