快速讀懂InnoDB存儲引擎
什么是存儲引擎
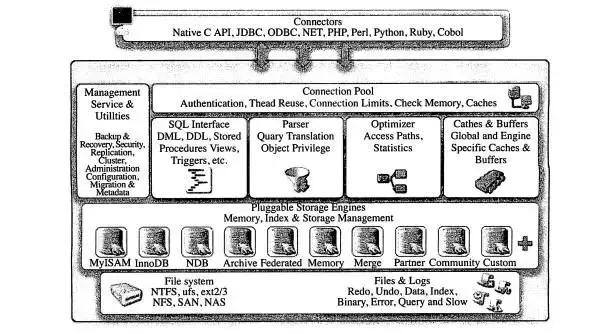
存儲引擎位于文件系統(各種數據,二進制形式)之上,各種管理工具(連接池、語義分析器、優化器、緩存區、SQL接口)之下。
存儲引擎功能設計
功能豐富性(或者SQL語義支持):
事務(和文件系統的最大區別),鎖的粒度(行或者表),全文索引,簇索引,外鍵(這是什么)
事務:
事務的隔離性由鎖實現,其他ACD由redo log和undo logo實現。redo log保證事務原子性(怎么理解?由于數據庫設計是先寫redo,再執行真正修改數據頁。所以redo一定是個完整的事務,才會修改數據頁)和持久性(怎么理解?持久化到硬盤)。undo log保證事務一致性(數據沖突時的恢復)。
redo 寫法是數據庫一直順序寫,無需讀。由于沒有使用O_DIRECT裸寫盤,所以每次寫redo 必須fsync到硬盤。
另外這里還有提到的是binlog,區分的是binlog是數據庫容災的范籌(記錄的是sql語句,在事務提交的時候才會寫)。而redo是innodb產生的(修改頁的物理二進制日志,隨事務進行而并發寫)。而且在寫redo是以日志塊大小和磁盤扇區一樣。都是512字節。所以重寫日志寫入具有原子性。redo的物理二進制日志,以不記錄sql語句執行過程,而記錄sql執行后的頁結果。由此具有冪等性(執行多次等同于執行一次,分布式網絡的不可靠 由于多次重新調用接口,必須保證冪等性)。
一個問題是,基于硬盤的數據庫會把數據寫在內存中,同時對數據庫的修改最初也是改在內存上,怎么落地呢(checkpoint檢查點機制)。事務數據庫為了保證ACID的D一般會使用先寫redo log,在修改頁。
undo幫助事務回滾和MVCC功能。
表鎖、行鎖:
鎖機制分為latch(輕量級的鎖,分為mutex和rwlock。這個是內部鎖機制,保證并發線程操作臨界資源的正確性,通常沒有死鎖檢測機制, 比如查看mutex的方法是show engine innodb mutex;)和lock(粒度為事務,可以是表、頁、行,有死鎖檢測機制)。
死鎖檢測機制有:順序獲取多個鎖(latch只有這個機制),waits-for graph(圖死鎖檢測),過期機制。
MVCC機制(解決鎖帶來爭用的分布式并發訪問問題)
自增長鎖:給每個插入賦予一個唯一增加的id,每個插入獲取到這個id,就可以釋放表鎖。通過減少鎖的持有時間,提高并發插入效率。
查看當前事務隔離級別:
- mysql> SELECT @@tx_isolationG;
- *************************** 1. row ***************************
- @@tx_isolation: REPEATABLE-READ
幻讀和臟讀:臟讀都不好嗎?在slave節點可以修改innodb的默認事務隔離級別REPEATEDLY READ為READ UNCONMITTED,允許讀到不那么準確的數據。
不可重復讀:一般不可重復讀是可以接受的,因為他讀到的是提交的數據,而臟讀是讀到未提交的數據。如Oracle和SQL Server設置的事務隔離級別是READ CONMIITTED,則會出現不可重復讀現象。
丟失更新:一個事務更新會被另一個事務更新所覆蓋,從而產生數據不一致。基本數據庫任何隔離級別,不會產生。
數據存儲設計:
支持B樹索引,支持hash索引,數據壓縮存儲,數據表緩存(或者只索引緩存),數據文件加密,存儲效率,內存消耗,硬盤消耗,塊插入速度,查詢緩存,MVCC(解決并發數據一致性問題)。
B+樹索引/自適應hash索引:
B樹(Blance樹或者平衡樹):關系型數據庫最常用拿來做索引的。從AVL(平衡二叉樹演化而來)。
B+樹=B樹+索引順序訪問。包含樹枝節點和葉子節點。所有的數據放在葉子節點。每一個葉子節點互相有序順序連接。樹根節點指引著查找到葉子節點的路徑。由于不斷的插入和刪除,同時B+樹會通過旋轉保持平衡。
B+索引本身并不是找到具體的一條記錄,而是找到該記錄所在的頁。數據頁把載入到內中,然后通過頁目錄在進行二叉查找。因為在內存查找很快。
聚集索引:按照表的主鍵構建的B+樹。
輔助縮影:葉子節點存放的不是數據,而是捷徑,指引到找到所有數據的地方。
數據的區分度:Cardinality
自適應哈希索引:innodb根據查找頻度,創建hash索引。將o(logn)的查找復雜度提高最快o(0)(最慢o(n))的速度。哈希索引不對范圍查找有效。
壓縮空間和加密安全:
記錄在文件可以是普通模式或者reduction模式。
容災機制:
備份機制,備份恢復(備份快照點記錄)。熱備,冷備,溫備。
新上一臺備機的備份順序是記住當前主數據庫的LSN(log squence number),導出主數據庫的當前數據庫并在備機導入。設置LSN同步點。
innodb特性
特性:
- innodb架構:多線程模型(Master,IO,Purge,Page Cleaner),數據刷新到硬盤才是sql(事務)執行完的標志嗎。purge是完成事務提交后情況undo log。
- 內存的消耗大(大在哪里?)。內存消耗在具體在緩沖區。緩沖區除了保護有數據頁,索引頁,還有undo頁,插入緩沖。自適應hash索引、鎖信息、字典信息。為什么innodb的內存會比其他的存儲引擎大呢?
- 什么是數據庫實例(類似于服務器的進程,數據庫是數據文件)
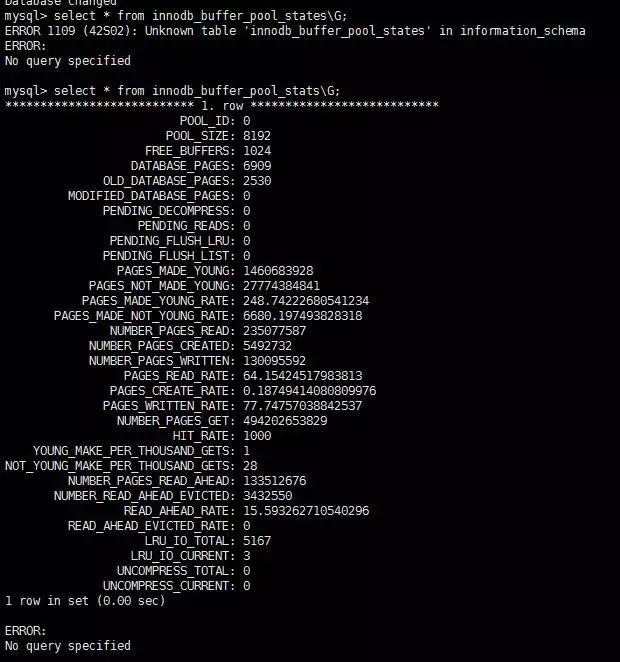
- 緩沖區的基本管理思路是LRU。37為距離LRU追加尾部的37%位置,并且只有在mid位置當超過block_times的時候才要可以會被移到mid的熱點。當然用戶預估自己的熱點數據,適當得增加mid之前的熱點區域。其中page made young和page not made young就表示了頁從old移到new或者由于block_time的限制,old沒能移到new。從information_schema數據庫的select * from innodb_buffer_pool_statsG;可以獲取到。可以看到這里還是很多old往new的遷移過程當中被block住。(我覺得這里made yong的過程中,是不是有很多熱點數據,有沒有必要把mid位置調長些)。第一個實例:緩沖區空間size:8192*16K=128M。LRU表項用DATABASE_PAGES表示。FREE_BUFFERS是可利用的頁。
- 主線程:每秒鐘循環和每10秒鐘循環
- 重做日志的LSN(Log Sequeence Number)標記版本。
- Sharp Checkpoint和Fuzzy Checkpoint(主線程定時的刷新,LRU頁不夠必須刪除尾巴頁,重做日志不可用,臟頁太多)
- 數據庫的容災:重做日志+LRU。LRU溢出需要寫磁盤。重做日志由于磁盤空間必須部分刪除需要寫磁盤
innodb關鍵特性:
- 插入緩沖:針對非聚集索引的插入或者更新。針對非唯一輔助索引。
- 兩次寫:寫的壓力大不大,總共寫內存多少Innodb_dblwr_pages_written(真實反映數據庫的),硬盤持久化多少次Innodb_dblwr_writes
- 自適應hash索引:要求訪問模式比較單一
- AIO:AIO的好處和壞處。:| innodb_flush_neighbors | 1 |
- 刷新鄰接頁(預讀)。但是如果是本來 就是iops比較高的存儲設備還需要這個嗎,因為這個是對機械硬盤相鄰數據寫入做優化,或者有沒有可能領接頁寫入刷新了 又很快變為臟頁。
查看當前數據庫運行性能
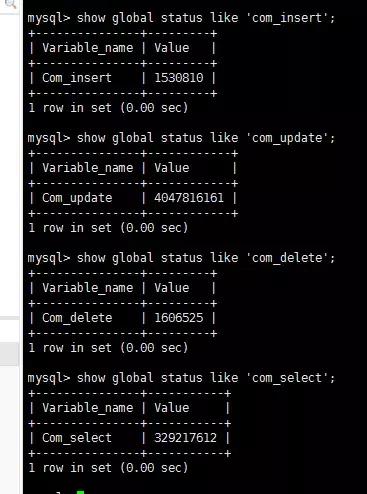
- show global status like 'com_select';列出 自數據庫啟動以來的所有連接
查看數據庫的線程數據來窺探性能
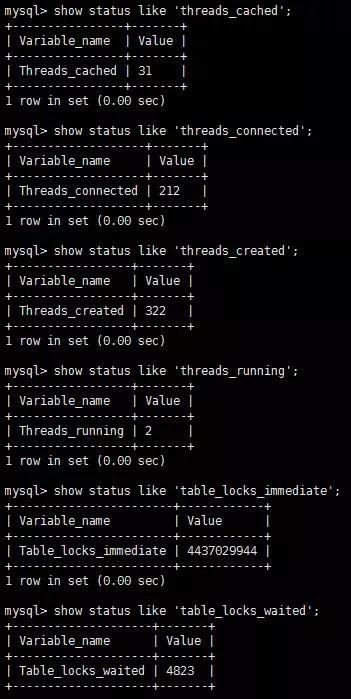
查看緩存區狀態
LRU查看
- mysql> show variables like '%old_block%';
- +------------------------+-------+
- | Variable_name | Value |
- +------------------------+-------+
- | innodb_old_blocks_pct | 37 |
- | innodb_old_blocks_time | 1000 |
- +------------------------+-------+
查看當前數據庫的運行狀態還有
- show engine innodb status。
- show variables;
- show status;
備份相關
- show binlog events in 'bin-log.000004'G
- show master status
- show slave status
- show binary logs;查看所有的二進制日志
- show variables like '%sync_binlog%'
- binlog文件轉換
- 每次服務器啟動都開啟一個新的二進制日志。文件大小超過限制將會創建一個新的文件。