機器學習算法在IDS中的應用
譯文【51CTO.com快譯】得益于近年來機器學習技術的飛速發展,人們正在將各種自動化且具有擴容預測能力的技術,運用到網絡安全系統的加固上。
眾所周知,網絡安全的最常見風險來自入侵,其中包括:蠻力破解、拒絕服務、網絡滲透等方面。而現如今,隨著網絡行為模式的改變,業界普遍認為單憑靜態數據集的策略,是無法捕獲流量的具體組成、并予以攔截的。因此我們有必要采用一種動態的方式,來檢測和防御各種入侵。
也就是說:我們需要可修改的、可重復且可擴展的數據集,來學習和處理那些能夠輕松繞過傳統入侵檢測系統(IDS)的復雜攻擊源。下面,讓我們一起討論機器學習如何能夠在入侵檢測中發揮作用,以構建出更為強大與健壯的IDS。
與IDS相關的機器學習相關概念
在機器學習的各種算法中,無監督(Unsupervised)式學習算法可以從網絡中“學到”各種典型的模式,并且能夠在沒有任何已標記數據集的情況下,報告異常情況。雖然它可以檢測出各種新型的入侵,但是很容易出現誤報(false positive alarms)的情況。因此,我們在此只討論無監督式的K-均值聚類算法。另外,為了減少誤報,我們可以引入已標記的數據集,并建立監督式機器學習模型,進而訓練出網絡中正常數據包與攻擊流量之間的特征差異。此類監督式的模型能夠熟練地處置各種已知攻擊,并且能夠識別出此類攻擊的變種。因此,我們下面會討論到的標準監督式算法包括:貝葉斯網絡、隨機森林、隨機樹、MLP、以及決策表。
數據集
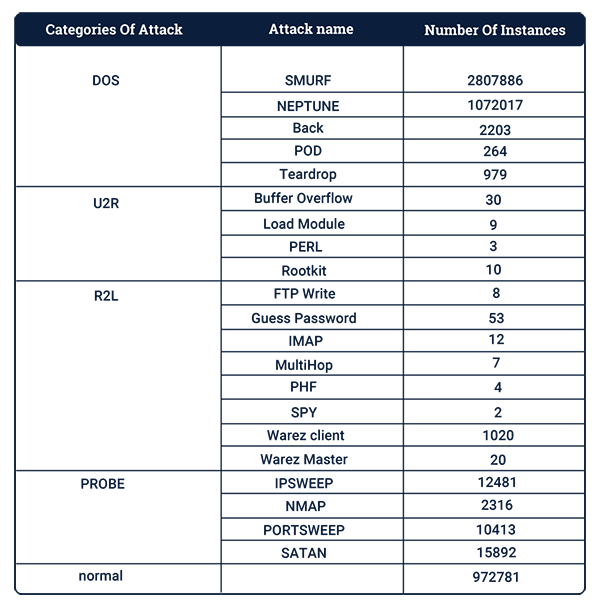
在機器學習模型的開始階段,最重要也是最繁瑣的過程便是獲得各種可靠的數據。在此,我們使用KDD Cup 1999的數據,來建立預測模型,從而區分入侵類攻擊與真正有價值的流量連接。KDD Cup 1999是一個標準的數據集,它包括了在軍事網絡環境中所模擬出的各種干預模型,由4898431個實例和41種屬性所組成。
它會跟蹤如下四種攻擊類型,每一個連接都會被標記為正常、或是具有攻擊性。而且每一條連接記錄大約都是由100個字節所組成。
- 拒絕服務:denial-of-service
- R2L:來自遠程機器的未經授權的訪問
- U2R:來自本地root特權的未經授權的訪問
- 探測:監視并需要另一種檢查
如下表所示,每一種類型都包含了具體的攻擊形式,一共有21種。
KDD集合
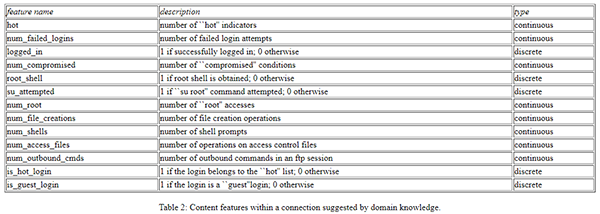
如下表所示,我們總結出了任意一種基于TCP/IP協議的連接集的基礎分類特征:

數據在能夠被機器學習算法所使用之前,必須經過被特征選擇等處理。有些元素特征很容易被發現,而其他的特征則需要通過實驗和測試才能被找到。當然,由于某些特征是冗余的,而且將不同的類別予以區分可能意義不大,因此在IDS中使用數據集的所有特征并不一定能獲得最佳的性能,有時甚至會增加系統的計算成本與錯誤率。
此處,數據集的主要貢獻是通過引入專家建議的屬性,有助于系統理解不同類型的攻擊行為,包括上述提及的:檢測DoS、探測、R2L和U2R等基本特性。下表便是來自不同領域的知識庫所給出的內容特征列表。
機器學習算法的簡述
K-均值聚類(K-means clustering)
如前所述,K-均值聚類是一種無監督式的學習技術。這是最簡單、也是最流行的機器學習算法之一。它在數據中尋找不同的組,其中組的數量由變量K所表示。該算法基于數據集的特征,將不同的數據點分配給K中的一個組。基于不同的特征相似性,各個數據點會被采取聚類。
貝葉斯網絡(Bayes Network)
貝葉斯網絡是一種概率圖形模型。它的原理是通過繪制出有向圖形邊上的依賴關系,進而充分利用到條件的依賴性。它假定所有沒有被邊緣所連接的節點,都是具有條件獨立。而且它在創建有向無環圖時,就利用到了該事實基礎。
隨機森林分類器(Random Forest Classifier)
隨機森林是一種集成式的分類器,它通過合并多種算法來實現分類。這些算法在數據的隨機子集上創建多個決策樹,然后通過聚合每棵樹的總票數,來決定測試的類別。同時,它也會給個別樹的貢獻程度分配權重值。
多層感知(MLP)
MLP是一種前饋式神經網絡。它至少由三個層次所組成:輸入層、隱藏層和輸出層。在訓練期間,我們可以通過調整各種權重或參數,來最小化分類中的錯誤。該算法在每個隱藏節點中引入了非線性(Non-linearity)。而反向傳播則是用來通過參照錯誤,進而調整權重與偏差。
實現
下面,我們將使用Python及其廣泛的庫來實現IDS。當然,我們需要事先安裝好Pandas(基于Python的大型數據集分析庫)、NumPy(Python的一種開源類數值計算擴展)和Scipy(可用于數學、科學、工程領域的常用軟件包,常用于計算Numpy矩陣,能與Numpy協同工作)。如果您使用的是Ubuntu系統,那么其對應的shell命令應該是:
- sudo pip install numpy scipy pandas
首先,我們需要對數據集進行預處理,也就是說:數據集需要被下載并提取到程序對應的文件夾中。同時,該數據集應該是.csv格式,以方便Python的讀取。因此具體命令如下:
- # Import pandas
- import pandas as pd
- # reading csv
- file dataset = pd.read_csv("filename.csv")
前面提到的各種機器學習算法都應當被存放在“神奇”的Scipy庫中。通過以下步驟,您可以使用不同的模型,來快速運行目標數據集:
K-均值
- import numpy as np
- from sklearn.cluster
- import KMeans
- print(dataset.describe())
- # to view the summary of the dataset loaded
- kmeans = KMeans(n_clusters=2)
- # You want cluster the threats into 5: Normal, DOS,PROBE, R2L and U2R
- kmeans.fit(X)
- prediction = kmeans.predict(dataset[0])
- # predicts the type for the first entry
- 隨機森林
- #Import Random Forest Model
- from sklearn.ensemble
- import RandomForestClassifier
- #Create a Gaussian
- Classifier clf=RandomForestClassifier(n_estimators=50)
- #Train the model using the training
- dataset clf.fit(dataset,dataset[:,LAST_COLUMN])
- #LAST_COLUMN is the index of the column with the labelled type of threat or normal
- pred=clf.predict(dataset)
樸素貝葉斯網絡
- from sklearn.naive_bayes
- import GaussianNB
- #Create a Gaussian Naive Bayes Classifier
- gnb = GaussianNB()
- gnb.fit(dataset,dataset[:,LAST_COLMN])
- pred=predict(gnb,dataset[0])
多層感知
- From sklearn.neural_network
- import MLPClassifier
- #Create a Multi-Layer Perceptron
- clf = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5, 2), random_state=1)
- clf.fit(dataset,dataset[:,LAST_COLMN])
- pred=clf.predict(dataset[0]);
結果
為了衡量機器學習模型的準確性,我們會引入諸如:平均準確度(Average Accuracy)、誤報率(False Positive Rates)和漏報率(False Negative Rates)等不同衡量維度的參考指標。由于K-均值是一種無監督式算法,因此它被排除在了該指標之外。
如下面公式所示,平均準確度定義為:被正確分類的數據點與數據點總數的比。
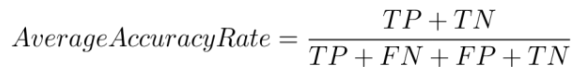
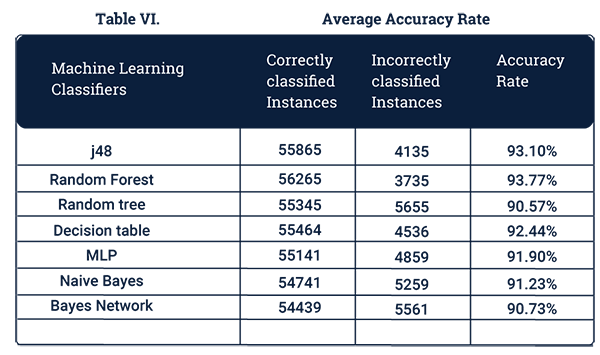
顯而易見,此處的“誤報”是指那些被判定為威脅,而實際上并非為如此的數據流量。同理,“漏報”是指那些確實為威脅,但未被IDS所查出并報告的流量。

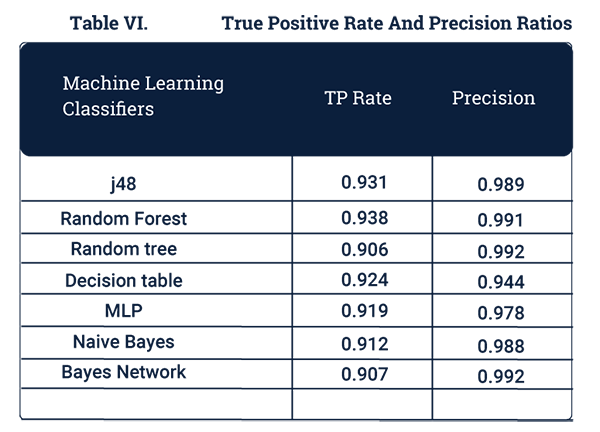
另一些可以參考與度量的指標還包括:精度和真陽性。其中:
- 精度是指發現的威脅與威脅總量的比率。
- 真陽性是指那些能夠被成功地識別為威脅包,與全部能被識別和判定的數據包的比率。
應用的意義
從某種程度上說,當前所有的IDS都應該引入機器學習技術,以應對日益增加的網絡安全威脅。具備機器學習的IDS,能夠實現細粒度、高精度的自動化檢測。籍此,企業可以使用各種檢測結果來跟蹤攻擊源,阻止它們的進一步滲透,并優化自身的網絡。另外,用戶公司也不必再通過訂購威脅特征簽名,來被迫與新產生的攻擊進行“時間賽跑”。當然,在不同的應用與檢測場景中,不同的機器學習算法會各有所長。我們應該根據網絡及用戶流量的特性,選用最適合自身環境的基于機器學習的IDS方案。
原文標題:Evaluation of ML Algorithms for Intrusion Detection Systems,作者:Aman Juneja
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】