













萬億數據下 Hadoop 的核心競爭力
1. 前言
在大數據時代,Hadoop 有著得天獨厚的優勢。然而,每個企業的技術儲備和需求特點不同,他們希望從海量的客戶數據中挖掘真正的商業價值,像 Google 、Facebook 、Twitter 等這樣的企業更是 Hadoop 的最早獲益者。那么,今天我們就來聊一聊,萬億數據下 Hadoop 的核心競爭力。
2. 什么是 Hadoop ?
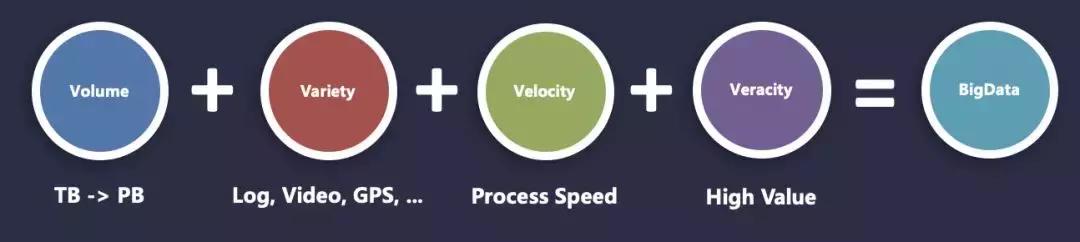
在了解 Hadoop 之前,不得不說的一個名詞—— “ 大數據 ” 。大數據是時代發展和技術進步的產物,大數據的特征如下:
- 龐大的數據容量
- 結構化、半結構化、非結構化的數據類型
- 高效的處理速度
- 高質量的數據
Hadoop 由 Apache 基金會孵化并開源的分布式系統,用戶可以在不了解分布式底層設計的情況下,開發分布式應用程序,充分利用集群的優勢來進行高速的運算和存儲。自從 Hadoop 作為 Apache 基金會開源項目發布以來,它一直備受青睞,這得益于 Hadoop 的可擴展性、低成本、靈活的處理模式等特點。
3. 萬億數據下的難點?
數據量達到萬億規模,這已經是一個很龐大的數據量了。這里難點我們可以分為兩種情況,一種是原理上不知道怎么處理,沒有具體的實施方案,這個屬于技術難題。另一種,雖然有具體的實施方案,也明白其中的原理,但是數據規模太過龐大,這個屬于工程上的難點。
數據規模龐大帶來的難點主要體現在分布式的要求,因為單個節點不足以在有效的成本和規定的時間內處理完所有的數據。簡而言之:
- 并行化問題:處理數據的應用程序要改造成適合并行的方式;
- 資源分配管理問題:如何有效的管理提交任務的資源,內存、網絡、磁盤等;
- 容錯問題:隨著機器數量的增加,可靠性如何保證,例如部分機器硬件出錯導致不可用,最終結果的完整性和正確性如何保證。
4. Hadoop 的組成部分有哪些?能做什么?
截止至本篇文章,Hadoop 社區發布了 Hadoop-3.2.0 版本,其核心組成部分包含:基礎公共庫 ( Common ) 、分布式文件存儲系統 ( HDFS ) 、分布式計算框架 ( MapReduce ) 、分布式資源調度與管理系統 ( YARN ) 、分布式對象存儲框架 ( OZone ) 、機器學習引擎 ( Submarine ) 。
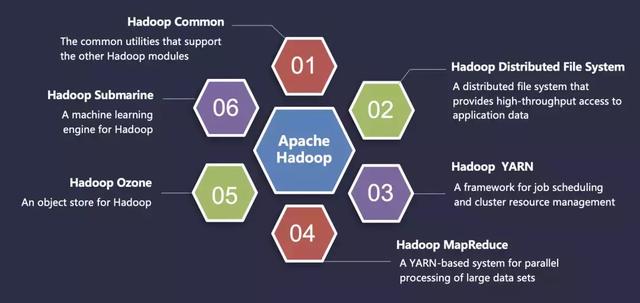
4.1 Hadoop Common
Hadoop Common 屬于基礎公共庫,它是 Hadoop ***層的一個模塊,為 Hadoop 各個子項目提供各種工具,例如配置文件、操作日志等。
4.2 Hadoop Distributed File System
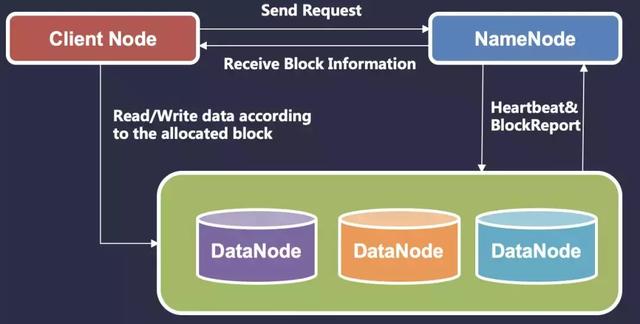
Hadoop Distributed File System 簡稱 HDFS,它是 Hadoop 的一個分布式文件系統,類似于 Amazon 的 S3 系統,Google 的 GFS 系統。
HDFS 可以處理分布在集群中的大文件,它通過將文件分成數據塊來完成此操作。同時,我們可以并行訪問分布式數據 ( 例如,在進行數據處理時 ) ,各個數據節點進行數據交互形成數據塊的副本。
4.3 Hadoop YARN
YARN 是 Hadoop 的一個分布式資源管理框架,可以為上層應用提供統一的資源管理與調度。通過引入 YARN,Hadoop 集群在資源利用率、資源統一管理、數據共享等方面帶來了巨大的好處。
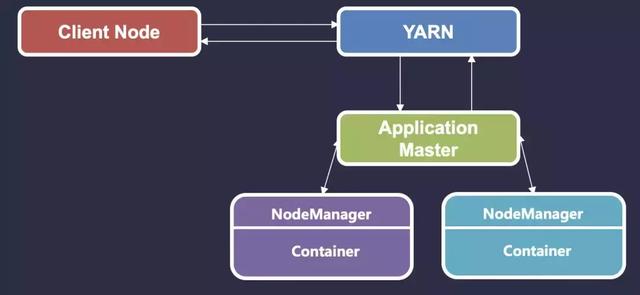
Client 應用提交任務到 YARN ,流程如下:
- Client 發送請求給 RM
- ResourceManager ( 簡稱 RM ) 返回 ApplicationId 給 Client
- Client 發送 ApplicationId 、QueueName 、用戶等信息給 RM
- RM 尋找合適的 Container ,并將 Client 提交的信息給 NodeManager ( 簡稱 NM )
- 然后在 NM 中啟動 AM ,RM 給 AM 分配***最小資源
- AM 從 RM 那里獲取的可使用資源來申請一些 Container
- Job 在 Container 中執行,由 AM 返回任務進度,任務執行完成后,AM 向 RM 發送結束任務信息然后退出
4.4 Hadoop MapReduce
MapReduce 是 Hadoop 的一個分布式計算框架,用來處理海量數據。同時,還可以使用 MapReduce 框架來實現一些算法,例如統計單詞頻率、數據去重、排序、分組等。
4.5 Hadoop OZone
Ozone 是 Hadoop 的可擴展、冗余和分布式對象存儲。除了擴展到數十億不同大小的對象外,OZone 還能在 Kubernetes 和 YARN 等容器環境中有效發揮作用。
- 可擴展性:OZone設計之初能夠擴展到數百億個文件和數據塊,并且在將來會擴展到更多;
- 一致性:OZone是一個強一致性對象存儲,它所使用的協議是類似于RAFT來實現的;
- 云集成:OZone設計之初能夠與YARN和Kubernetes集成使用;
- 安全性:OZone能夠與Kerberos集成,用于控制訪問權限,并支持TDE和線上加密;
- 多協議支持:OZone能夠支持不同的協議,例如S3、HDFS;
- 高可用:OZone是一個多副本系統,用于保證數據高可用性。
4.6 Hadoop Submarine
Submarine 是一個允許基礎設施工程師 / 數據科學家在資源管理平臺 ( 如 YARN ) 上運行深度學習應用程序 ( Tensorflow ,Pytorch 等 ) 的項目。
- 在已有集群運行:Submarine 支持在 YARN 、Kubernetes 或者其他類似的調度框架中使用;
- 支持多種框架:Submarine 支持多種機器學習框架,例如 TensorFlow 、Pytorch 、MxNet 等;
- 覆蓋整個ML:Submarine 不僅僅是一個機器學習引擎,它涵蓋了整個機器學習過程,例如算法開發、模型批量訓練、模型增量訓練、模型在線服務和模型管理。
5. Hadoop 的核心競爭力在哪?
Hadoop 如此受人喜歡,很大程度上取決于用戶對大數據存儲、管理和分析需求的迫切。大數據是目前很多企業面臨的一個挑戰,由于數據量的龐大、數據類型的復雜 ,特別是非結構化或者半結構化的數據遠遠多于結構化的數據,一些傳統的基于關系型數據庫的存儲和分析難以滿足時,且關系型數據庫巨大成本壓力也是很多企業考慮的問題,而 Hadoop 給人們提供了解決大數據問題的技術手段。
大數據時代需要 Hadoop ,那么 Hadoop 的核心競爭力在哪呢?
5.1 降低大數據成本
Hadoop 使企業可以高效的管理數據,以降低數據成本,其中包含業務成本、硬件成本、人工成本、存儲成本等。通過易用性、權威性、時效性等特性,Hadoop 還可以幫助用戶增加數據價值。目前 Hadoop 社區的支持,以及各大 Hadoop 廠商的支持,使得 Hadoop 從一個單獨的開源軟件逐步演變成一個具有一定規模的生態系統,這些廠商包含 Cloudera 、MapR 、Hortonworks 等,他們在這一生態系統中扮演著不同的角色,例如有系統廠商、監控服務商、數據分析商等。
而使用者可以從這些廠商中提供的系統來簡化 Hadoop 的學習成本,快速構建符合自身要求的大數據平臺,同時合理利用廠商提供的附屬組件來開發出高效、易用的的大數據應用。
5.2 成熟的 Hadoop 生態圈
Hadoop 不是一個 “ 孤島 ” 系統,它擁有成熟的 Hadoop 生態圈。
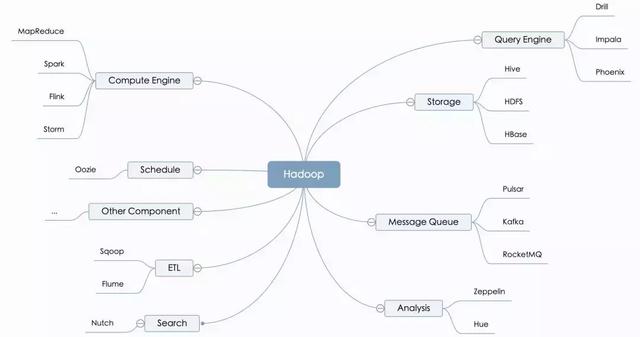
利用 Hadoop 生態圈設計滿足自身需求的方案,需要考慮一些關鍵要素:
- 從需求的最終結果開始分析,而不是從可用的工具開始。例如,可用性、一致性等;
- 對數據處理時效性的評估,例如離線任務 ( MapReduce 、Hive ) 、實時任務 ( Flink、Spark Streaming );
- 盡可能使用成熟的方案。
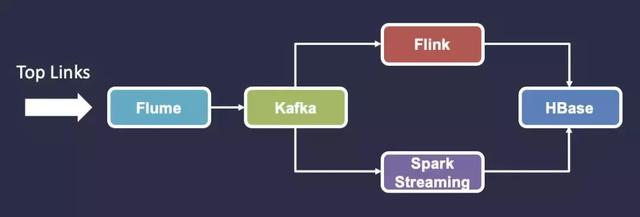
案例一:獲取***一小時的熱門鏈接
將熱門鏈接集中收集,使用 Flume 將鏈接發送到 Kafka ,然后使用 Flink 或者 Spark Streaming 計算引擎在1小時的窗口內分析數據,***將計算后的結果寫入到 HBase 進行存儲。
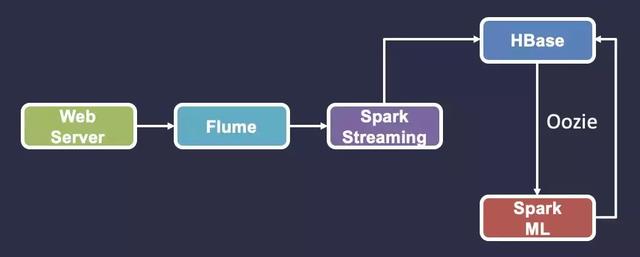
案例二:為用戶推薦電影
這是一個實時場景,用戶喜歡電影,那么用戶應立即看到相關電影。
解決思路:每次用戶給出評級時,計算建議都是包含權重的,因此我們應該定期根據現有用戶行為計算建議。根據對用戶行為的理解,可以為給定用戶預測所有電影的推薦,然后對其進行排序,并過濾用戶已經開過的內容。
組件選取:數據庫可以使用 NoSQL 數據庫,例如 HBase 。來存儲用戶評級。計算引擎方面可以選擇 Flink 或者 Spark ML 通過 Oozie 定時調度來重新計算用戶電影推薦。然后,使用 Flume 和 Spark Streaming 用于流式傳輸和處理實時用戶行為。
工作流程:Web 服務器將用戶評級發送給 Flume ,后者將其傳遞給 Spark Streaming ,然后將結果保存到 HBase 中。接著,使用 Oozie 定時調度執行 Spark ML 應用來重新計算電影推薦并將結果保存到 HBase 中。
6. 是否一定要選擇 Hadoop ?
與傳統數據庫系統相比較,開源的 Hadoop 有自己的優勢。尤其是 Hadoop 既能處理關系型數據庫中的結構化數據,也能處理視頻、音頻、圖片等非結構化數據。并且 Hadoop 還能夠根據數據的規模和問題的復雜度輕松的擴展。那是不是一定要用 Hadoop ?
每個企業都有自己的特殊需求,都有自己的技能棧,如果已經購買了成熟的數據庫產品,沒有必要舍棄這些產品,要確保對 Hadoop 足夠的了解,不要盲目的 “ 跟風 ” 。
然而,Hadoop 是解決大數據的一種技術手段,這個是一個趨勢,例如 Hadoop 與 AI 、IoT 等領域的結合使用。了解和掌握 Hadoop 是有所必要的,可以從一些小的項目嘗試積累更多經驗。
7. 結束語
這篇文章就和大家分享到這里,如果大家在研究學習的過程當中有什么問題,可以發送郵件給我,我會盡我所能為您解答,與君共勉!
作者介紹:
哥不是小蘿莉,知名博主,著有《 Kafka 并不難學 》和《 Hadoop 大數據挖掘從入門到進階實戰 》。











