













緩沖池(buffer pool),這次徹底懂了!!!
應(yīng)用系統(tǒng)分層架構(gòu),為了加速數(shù)據(jù)訪問,會(huì)把最常訪問的數(shù)據(jù),放在緩存(cache)里,避免每次都去訪問數(shù)據(jù)庫(kù)。
操作系統(tǒng),會(huì)有緩沖池(buffer pool)機(jī)制,避免每次訪問磁盤,以加速數(shù)據(jù)的訪問。
MySQL作為一個(gè)存儲(chǔ)系統(tǒng),同樣具有緩沖池(buffer pool)機(jī)制,以避免每次查詢數(shù)據(jù)都進(jìn)行磁盤IO。
今天,和大家聊一聊InnoDB的緩沖池。
InnoDB的緩沖池緩存什么?有什么用?
緩存表數(shù)據(jù)與索引數(shù)據(jù),把磁盤上的數(shù)據(jù)加載到緩沖池,避免每次訪問都進(jìn)行磁盤IO,起到加速訪問的作用。
速度快,那為啥不把所有數(shù)據(jù)都放到緩沖池里?
凡事都具備兩面性,拋開數(shù)據(jù)易失性不說(shuō),訪問快速的反面是存儲(chǔ)容量小:
- 緩存訪問快,但容量小,數(shù)據(jù)庫(kù)存儲(chǔ)了200G數(shù)據(jù),緩存容量可能只有64G;
- 內(nèi)存訪問快,但容量小,買一臺(tái)筆記本磁盤有2T,內(nèi)存可能只有16G;
因此,只能把“最熱”的數(shù)據(jù)放到“最近”的地方,以“***限度”的降低磁盤訪問。
如何管理與淘汰緩沖池,使得性能***化呢?
在介紹具體細(xì)節(jié)之前,先介紹下“預(yù)讀”的概念。
什么是預(yù)讀?
磁盤讀寫,并不是按需讀取,而是按頁(yè)讀取,一次至少讀一頁(yè)數(shù)據(jù)(一般是4K),如果未來(lái)要讀取的數(shù)據(jù)就在頁(yè)中,就能夠省去后續(xù)的磁盤IO,提高效率。
預(yù)讀為什么有效?
數(shù)據(jù)訪問,通常都遵循“集中讀寫”的原則,使用一些數(shù)據(jù),大概率會(huì)使用附近的數(shù)據(jù),這就是所謂的“局部性原理”,它表明提前加載是有效的,確實(shí)能夠減少磁盤IO。
按頁(yè)(4K)讀取,和InnoDB的緩沖池設(shè)計(jì)有啥關(guān)系?
- 磁盤訪問按頁(yè)讀取能夠提高性能,所以緩沖池一般也是按頁(yè)緩存數(shù)據(jù);
- 預(yù)讀機(jī)制啟示了我們,能把一些“可能要訪問”的頁(yè)提前加入緩沖池,避免未來(lái)的磁盤IO操作;
InnoDB是以什么算法,來(lái)管理這些緩沖頁(yè)呢?
最容易想到的,就是LRU(Least recently used)。
畫外音:memcache,OS都會(huì)用LRU來(lái)進(jìn)行頁(yè)置換管理,但MySQL的玩法并不一樣。
傳統(tǒng)的LRU是如何進(jìn)行緩沖頁(yè)管理?
最常見的玩法是,把入緩沖池的頁(yè)放到LRU的頭部,作為最近訪問的元素,從而最晚被淘汰。這里又分兩種情況:
- 頁(yè)已經(jīng)在緩沖池里,那就只做“移至”LRU頭部的動(dòng)作,而沒有頁(yè)被淘汰;
- 頁(yè)不在緩沖池里,除了做“放入”LRU頭部的動(dòng)作,還要做“淘汰”LRU尾部頁(yè)的動(dòng)作;
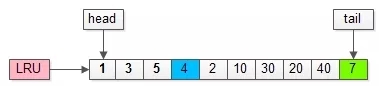
如上圖,假如管理緩沖池的LRU長(zhǎng)度為10,緩沖了頁(yè)號(hào)為1,3,5…,40,7的頁(yè)。
假如,接下來(lái)要訪問的數(shù)據(jù)在頁(yè)號(hào)為4的頁(yè)中:
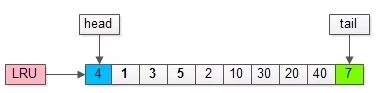
- 頁(yè)號(hào)為4的頁(yè),本來(lái)就在緩沖池里;
- 把頁(yè)號(hào)為4的頁(yè),放到LRU的頭部即可,沒有頁(yè)被淘汰;
畫外音:為了減少數(shù)據(jù)移動(dòng),LRU一般用鏈表實(shí)現(xiàn)。
假如,再接下來(lái)要訪問的數(shù)據(jù)在頁(yè)號(hào)為50的頁(yè)中:
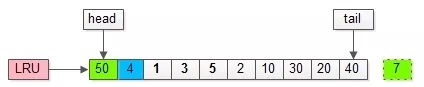
- 頁(yè)號(hào)為50的頁(yè),原來(lái)不在緩沖池里;
- 把頁(yè)號(hào)為50的頁(yè),放到LRU頭部,同時(shí)淘汰尾部頁(yè)號(hào)為7的頁(yè);
傳統(tǒng)的LRU緩沖池算法十分直觀,OS,memcache等很多軟件都在用,MySQL為啥這么矯情,不能直接用呢?
這里有兩個(gè)問題:
- 預(yù)讀失效;
- 緩沖池污染;
什么是預(yù)讀失效?
由于預(yù)讀(Read-Ahead),提前把頁(yè)放入了緩沖池,但最終MySQL并沒有從頁(yè)中讀取數(shù)據(jù),稱為預(yù)讀失效。
如何對(duì)預(yù)讀失效進(jìn)行優(yōu)化?
要優(yōu)化預(yù)讀失效,思路是:
- 讓預(yù)讀失敗的頁(yè),停留在緩沖池LRU里的時(shí)間盡可能短;
- 讓真正被讀取的頁(yè),才挪到緩沖池LRU的頭部;
以保證,真正被讀取的熱數(shù)據(jù)留在緩沖池里的時(shí)間盡可能長(zhǎng)。
具體方法是:
(1)將LRU分為兩個(gè)部分:
- 新生代(new sublist)
- 老生代(old sublist)
(2)新老生代收尾相連,即:新生代的尾(tail)連接著老生代的頭(head);
(3)新頁(yè)(例如被預(yù)讀的頁(yè))加入緩沖池時(shí),只加入到老生代頭部:
- 如果數(shù)據(jù)真正被讀取(預(yù)讀成功),才會(huì)加入到新生代的頭部
- 如果數(shù)據(jù)沒有被讀取,則會(huì)比新生代里的“熱數(shù)據(jù)頁(yè)”更早被淘汰出緩沖池
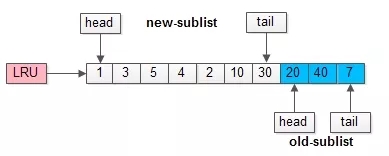
舉個(gè)例子,整個(gè)緩沖池LRU如上圖:
- 整個(gè)LRU長(zhǎng)度是10;
- 前70%是新生代;
- 后30%是老生代;
- 新老生代首尾相連;
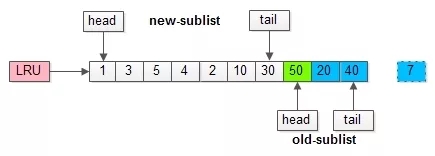
假如有一個(gè)頁(yè)號(hào)為50的新頁(yè)被預(yù)讀加入緩沖池:
- 50只會(huì)從老生代頭部插入,老生代尾部(也是整體尾部)的頁(yè)會(huì)被淘汰掉;
- 假設(shè)50這一頁(yè)不會(huì)被真正讀取,即預(yù)讀失敗,它將比新生代的數(shù)據(jù)更早淘汰出緩沖池;
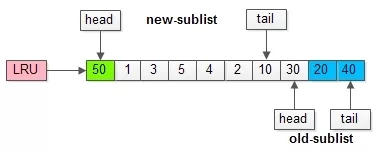
假如50這一頁(yè)立刻被讀取到,例如SQL訪問了頁(yè)內(nèi)的行row數(shù)據(jù):
- 它會(huì)被立刻加入到新生代的頭部;
- 新生代的頁(yè)會(huì)被擠到老生代,此時(shí)并不會(huì)有頁(yè)面被真正淘汰;
改進(jìn)版緩沖池LRU能夠很好的解決“預(yù)讀失敗”的問題。
畫外音:但也不要因噎廢食,因?yàn)楹ε骂A(yù)讀失敗而取消預(yù)讀策略,大部分情況下,局部性原理是成立的,預(yù)讀是有效的。
新老生代改進(jìn)版LRU仍然解決不了緩沖池污染的問題。
什么是MySQL緩沖池污染?
當(dāng)某一個(gè)SQL語(yǔ)句,要批量掃描大量數(shù)據(jù)時(shí),可能導(dǎo)致把緩沖池的所有頁(yè)都替換出去,導(dǎo)致大量熱數(shù)據(jù)被換出,MySQL性能急劇下降,這種情況叫緩沖池污染。
例如,有一個(gè)數(shù)據(jù)量較大的用戶表,當(dāng)執(zhí)行:
select * from user where name like "%shenjian%";
雖然結(jié)果集可能只有少量數(shù)據(jù),但這類like不能***索引,必須全表掃描,就需要訪問大量的頁(yè):
- 把頁(yè)加到緩沖池(插入老生代頭部);
- 從頁(yè)里讀出相關(guān)的row(插入新生代頭部);
- row里的name字段和字符串shenjian進(jìn)行比較,如果符合條件,加入到結(jié)果集中;
- …直到掃描完所有頁(yè)中的所有row…
如此一來(lái),所有的數(shù)據(jù)頁(yè)都會(huì)被加載到新生代的頭部,但只會(huì)訪問一次,真正的熱數(shù)據(jù)被大量換出。
怎么這類掃碼大量數(shù)據(jù)導(dǎo)致的緩沖池污染問題呢?
MySQL緩沖池加入了一個(gè)“老生代停留時(shí)間窗口”的機(jī)制:
- 假設(shè)T=老生代停留時(shí)間窗口;
- 插入老生代頭部的頁(yè),即使立刻被訪問,并不會(huì)立刻放入新生代頭部;
- 只有滿足“被訪問”并且“在老生代停留時(shí)間”大于T,才會(huì)被放入新生代頭部;
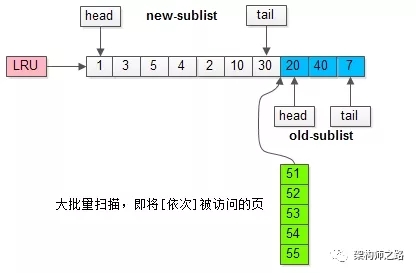
繼續(xù)舉例,假如批量數(shù)據(jù)掃描,有51,52,53,54,55等五個(gè)頁(yè)面將要依次被訪問。
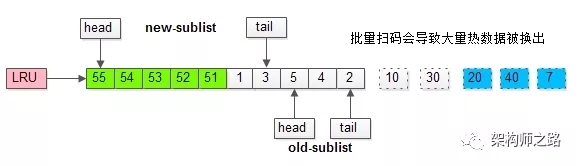
如果沒有“老生代停留時(shí)間窗口”的策略,這些批量被訪問的頁(yè)面,會(huì)換出大量熱數(shù)據(jù)。
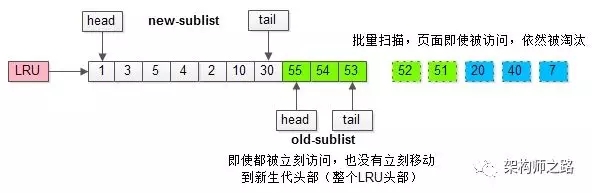
加入“老生代停留時(shí)間窗口”策略后,短時(shí)間內(nèi)被大量加載的頁(yè),并不會(huì)立刻插入新生代頭部,而是優(yōu)先淘汰那些,短期內(nèi)僅僅訪問了一次的頁(yè)。
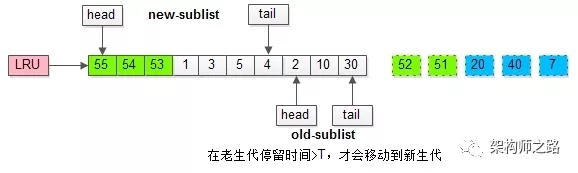
而只有在老生代呆的時(shí)間足夠久,停留時(shí)間大于T,才會(huì)被插入新生代頭部。
上述原理,對(duì)應(yīng)InnoDB里哪些參數(shù)?
有三個(gè)比較重要的參數(shù)。
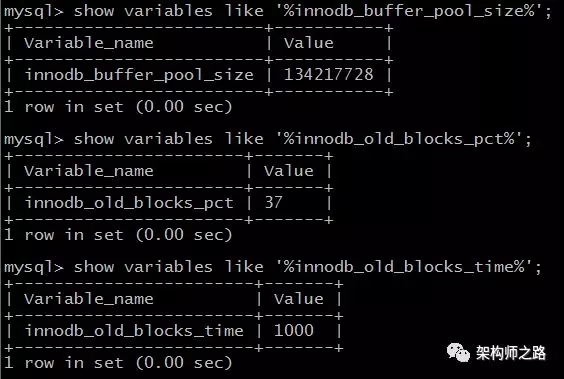
(1) 參數(shù):innodb_buffer_pool_size
介紹:配置緩沖池的大小,在內(nèi)存允許的情況下,DBA往往會(huì)建議調(diào)大這個(gè)參數(shù),越多數(shù)據(jù)和索引放到內(nèi)存里,數(shù)據(jù)庫(kù)的性能會(huì)越好。
(2) 參數(shù):innodb_old_blocks_pct
介紹:老生代占整個(gè)LRU鏈長(zhǎng)度的比例,默認(rèn)是37,即整個(gè)LRU中新生代與老生代長(zhǎng)度比例是63:37。
畫外音:如果把這個(gè)參數(shù)設(shè)為100,就退化為普通LRU了。
(3) 參數(shù):innodb_old_blocks_time
介紹:老生代停留時(shí)間窗口,單位是毫秒,默認(rèn)是1000,即同時(shí)滿足“被訪問”與“在老生代停留時(shí)間超過1秒”兩個(gè)條件,才會(huì)被插入到新生代頭部。
總結(jié)
(1) 緩沖池(buffer pool)是一種常見的降低磁盤訪問的機(jī)制;
(2) 緩沖池通常以頁(yè)(page)為單位緩存數(shù)據(jù);
(3) 緩沖池的常見管理算法是LRU,memcache,OS,InnoDB都使用了這種算法;
(4) InnoDB對(duì)普通LRU進(jìn)行了優(yōu)化:
- 將緩沖池分為老生代和新生代,入緩沖池的頁(yè),優(yōu)先進(jìn)入老生代,頁(yè)被訪問,才進(jìn)入新生代,以解決預(yù)讀失效的問題
- 頁(yè)被訪問,且在老生代停留時(shí)間超過配置閾值的,才進(jìn)入新生代,以解決批量數(shù)據(jù)訪問,大量熱數(shù)據(jù)淘汰的問題
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉(zhuǎn)載請(qǐng)聯(lián)系原作者】

戳這里,看該作者更多好文
























