













想讓機器學習與商業結合,最重要的是什么?
純學術性地建立機器學習模型與為企業提供端對端的數據科學解決方案(如生產制造、金融服務、零售、娛樂、醫療保健)之間存在著巨大差異。
在機器學習方面,企業最常面臨的問題是什么呢?除了培養機器學習模型,我們還能做什么?如何準備數據?如何擴大數據集?為什么特征工程如此關鍵?如何將模型運用到生產實踐,成為完全可行的系統呢中?如果能從開源軟件中獲取所有的數據科學工具,數據科學平臺還有存在的意義嗎?
本文將回答以上部分問題,并揭示目前機器學習遇到的挑戰和困難,進一步通過具體行業案例提出最佳解決方案。
機器學習不僅僅是培養模型
不少數據科學家對機器學習還存在普遍誤解。
“假設你拿到一組有某種特征的數據集,并需要推測其中某個變量,你會怎么做?”
很多數據科學家都會做如下回答:
“我會把數據集拆分成培養/測試兩部分,運行LogisticRegression, Random Forest, SVM, Deep Learning, XGBoost程序……然后計算精確度、查全率、F1分數……最終挑選出最佳模型。”
但是,還有些問題被忽略了:
“這個過程中你有看過數據本身嗎?要是你遺漏了一些數值怎么辦?如果你拿到錯誤的數值或是不良數據呢?你怎么設置分類變量?你是怎么做特征工程的?”
本文中將介紹成功創建端對端機器學習系統的七個必要步驟,包括數據收集、數據監管、數據探查、特征抽取、模型培養、估值和部署。
給我數據!
作為數據科學家,主要資源很明顯是數據。但有時數據采集本身也有困難。一個數據科學團隊可能會花費幾周甚至幾個月的時間來獲取合適的數據集。其中的困難包括:
- 獲取途徑:大部門企業數據都很敏感,尤其是政府、醫療保健和金融領域的相關數據。要共享數據集,簽署保密協議是常規流程。
- 數據分散:數據在組織內不同部門間散布是很常見的。要拿到整體數據,需要各部門的同意。
- 專業指導:能獲取數據往往還不夠。由于獲取的數據太多,需要一位領域專家指導團隊從龐大的數據庫中挑選出合適的數據集。有時專家的缺席也會成為項目瓶頸,因為核心企業運營已使他們應接不暇。
- 隱私:模糊處理和匿名操作已經成為兩項獨立的研究領域,在處理敏感數據時這二者尤為重要。
- 標記:通常了解實際情況或標記會很有幫助,因為這讓團隊能夠應用很多可監控的學習算法。然而,有時標記數據成本高昂,或由于法律限制團隊無法得到標記。在這些情況下,可以應用數據聚類等不可監控的方案。
- 數據生成器:如無法獲得數據或標記,可以去模擬它們。了解數據結構的相關信息會對使用數據生成器很有幫助,除此以外,還可以了解數值變數的可能性分布和名義變量的類別分布。如果數據結構比較散亂,可借助湯不熱(Tumblr)平臺,其上有許多標記圖像。此外,推特(Twitter)可提供大量自由文本,卡歌網(Kaggle)則擁有特定領域和行業相關的數據集和解決方案。
大數據并不大
近十年,大數據供應商賣力宣傳,強調對大數據規模和功能的需求,掀起了一股大數據熱潮。也因此,“大數據并不大”這一觀點引發了更大的爭議。然而,我們需要明確區分原始數據(包括對所有對當前問題無幫助的數據)和特征集(機器學習算法的輸入矩陣)。將原始數據處理成特征集的過程稱為數據處理,包含以下步驟:
- 丟棄無效/不完整/臟數據。根據我們的經驗,此類數據可占所有數據的一半。
- 聚合一個或多個數據集,包括數據連接和組類聚合等操作。
- 特征選取/抽除。比如,除去唯一性標識等可能無關的特征,并應用其它降維技術,如主成分分析。
- 使用稀疏數據表示法或功能散列法,以減少存在許多零值數據集的內存占用。
完成數據準備后,不難發現最終的特征集——即機器學習模型的輸入內容——比初始的小很多;另一種常見情況是R或scikit-learn等內存框架足以培養模型。若特征集規模仍十分龐大,可以使用ApacheSpark等大數據工具,盡管其算法選擇有限。
臟數據!

臟數據很常見
人們當然希望能學習一些尚不了解的東西,但這一點非常重要:臟數據很常見。在企業合作中,很多客戶經常自豪于他們的數據湖泊建設,比如數據湖泊有多壯觀、他們可從中得出多少洞見等。因此,作為數據科學家,以下就是我們腦海中的景象:
但是,當客戶拿出實際數據時,情況更像是這樣:
在這種情況下,Apache Spark等大規模框架就顯得尤為重要,因為所有的數據監管轉化過程都需要在全部原始數據上完成。以下是幾個典型的監管案例:
- 異常檢測:負數年齡、浮點郵編和零值信用評分等都是無效數據,不修正這些數值會在培養模型時產生深刻的偏見。
- 缺失/錯誤數值填充:顯然,處理錯誤/缺失數值最常用的方法就是丟棄它們。另一個選擇是填充。比如,用相應特征的平均數、中位數或眾數來代替缺失/錯誤數值。還有一種方法是插值,如建構模型來預測缺失數值的情況下的特征。另外,填充中也可以運用領域知識。比方說處理病人數據時,有一項特征是推斷病人是否患有癌癥。如果缺失此類信息,可以參考其問診數據,以確定此病人是否曾看過腫瘤科醫生。
- 虛擬編碼和功能散列:這兩種方法能很有效地把類別數據轉換成數值,尤其在基于系數的算法中。比方說,有一項特征是州名,顯示美國的各州名稱(如FL,CA,AZ)。將FL編碼為1,CA編碼為2,AZ編碼為3,會顯示出秩序感和重量級。這意味著AZ會比FL面積更大,而CA的面積是FL的兩倍大。一位獨熱編碼——也稱虛擬編碼——提供的解決方案是將類別欄映射到多個雙欄中,其中一欄為類別數值。
- 歸一化:若存在不同等級的特征,系數相關的算法就會產生偏見。比方說,特征年齡在[0,100]范圍內用年表示,然而工資在[0,100,000]范圍內用美元表示。優化算法可能僅僅因為工資的絕對數量級更大而更側重工資。因此,更推薦常態化算法以及其他常用方法,如Z值推測、標準化(如果數據正常)及min-max特征歸一化。
- 分箱:將實值欄映射到不同類別極為有效,如將一個回歸問題轉化為分類問題。比方說,你想推測航班進港延誤的分鐘數。一個選擇是推測該航班是否會提前、準時抵達或延誤,并確定各類別的數值范圍。
特征工程無處不在
總而言之,特征就是機器學習算法需要學習的特點。正如人們設想的那樣,干擾或無關數據會影響模型的質量,因此掌握好的特征就十分關鍵。以下是幾個特征工程中可使用的策略:
- 確定預測內容。每一個實例代表什么?顧客?交易?病人?還是票據?確保特征集的每一行都對應一個實例。
- 避免唯一性標識。它們不僅在大多數情況下不起作用,還有可能導致嚴重的過度擬合,尤其是在使用XGBoost等算法時。
- 運用領域知識來導出幫助衡量成功/失敗的新特征。通過去醫院的次數可以推斷醫患風險;上月跨國交易的總量可推斷詐騙的可能性;申請貸款數額與年收入的比例可推斷信用風險。
- 運用自然語言處理技術從散亂自由文本中導出特征。比如LDA,TF-IDF,word2vec和doc2vec。
- 若存在大量特征,可使用降維方法,如主成分分析和t-分布領域嵌入算法。
異常檢測無處不在
如果要在企業機器學習的應用案例中挑選出最常見的一個,那就是異常檢測。無論是否研究詐騙偵查、生產測試、客戶流失、醫患風險、客戶失信抑或是系統崩潰預測,面臨的問題總是:我們能否大海撈針?這就引出了另一個與非平衡數據集有關的話題。
以下是幾個用于異常檢測的常見算法:
- 自動編碼器
- 一類分類算法,如單類支持向量機。
- 信賴區間
- 聚類
- 運用過采樣和欠采樣法分類
- 非平衡數據很常見
非平衡數據
比方說,你有一組數據集,標記有信用卡交易信息。交易中的0.1%為不實信息,而其余99.9%均為正常交易。如果要創建一個從無虛假交易的模型,會發生什么呢?這個模型在99.9%的情況下都會給出正確答案,所以其精確度為99.9%。這個常見的精確度謬誤可以通過考慮不同的度量標準來避免,如精準度、查全率。這些通過真陽性(TP,true positives)、真陰性(TN,true negatives)、假陽性(FP,false positives)、假陰性(FN,false negatives)等術語來表示:
- 真陽性 = 全部實例正確推斷為正
- 真陰性 = 全部實例正確推斷為負
- 假陽性 = 全部實例錯誤推斷為正
- 假陰性 = 全部實例錯誤推斷為負
在一個異常檢測的典型案例中,我們試圖將假陰性最小化——比如,忽略一筆虛假交易,忽略一塊有問題芯片,或將一個病人視為健康的——同時不會導致大量假陽性實例。
- 精準度 = 真陽性/(真陽性+假陽性)
- 查全率 = 真陽性/(真陽性+假陰性)
要注意精準度不利于假陽性,而查全率不利于假陰性。一個從不推測出虛假信息的模型查全率為零,而精準度則未知。相反,一個總是推測出虛假信息的模型則有著100%的查全率和極低的精準度——這是由于大量假陽性實例的存在。
非常不推薦在異常檢測中使用受試者工作特征曲線(FPR)。因為假陽性率——FPR的基礎——很大程度上是基于數據集中的陰性實例數量(如假陽性+真陰性),使得在假陽性實例數量龐大的情況下FPR仍然很小。
受試者工作特征曲線 = 假陽性/(假陽性+真陰性)
相反,錯誤發現率(FDR)有助于更好理解假陽性實例對于異常檢測模型的影響:
錯誤發現率 = 1 – 精準度 = 假陽性/(真陽性+假陽性)
別預測了,直接解釋原因!
一些項目并不旨在創建一個實時預測模型,而是解釋假設或分析哪些因素可以解釋特定行為,因為大多數機器學習算法是基于相關性,而不是因果性。以下是一些例子:
- 什么因素導致一位病人患病風險增加?
- 哪些藥品對血檢結果影響最大?
- 哪些保險規劃參數值可使利益最大化?
- 失信客戶有什么特點?
- 流失客戶的簡況是什么?
處理此類問題的一個可行辦法是計算特征重要度,從Random Forests, Decision Trees和XGBoot等算法中可以得到此數據。另外,LIME或SHAP等算法則有助于解釋模型和預測,即使其源于神經網絡或其它“黑盒”模型。
調整超參數
機器學習算法有參數和超參數兩類參數。其不同之處在于:前者直接由算法進行估測——如,回歸的系數或神經網絡的權值——而后者則并非如此,須由用戶手動設置——如,某片森林的樹木總數,神經網絡的正則化方法,或支持向量機的內核功能。
為機器學習模型設置正確的超參數值十分重要。舉例而言,一個支持向量機的線性內核不能對無法線性分離的數據進行分類。再比如,如果最大深度和分裂數量設置得過高,一個樹型分類器可能出現過度擬合的情況;而最大特征數量設置過低,其可能無法充分擬合。
為超參數找到最優數值是一個極為復雜的優化問題。以下是幾點建議:
- 了解超參數的優先項。一片森林中,最相關的參數可能是樹木的數量和最大深度。然而,對于深度學習而言,優先項可能是學習率和層次數量。
- 運用搜索技巧:gridsearch和random search。后者優先。
- 運用交叉驗證:設置一個單獨測試組,將其余數據分為k層并將其迭代k次,每一層都進行驗證(如,調整超參數),其余的進行學習培養。最終,對全部層級進行平均質量度量標準的計算。
深度學習:萬金油?
過去幾年,深度學習一直是學術研究和行業發展的聚焦點。TensorFlow, Keras和Caffe等框架使復雜的神經網絡通過高層級的應用程序接口(API)得以快速運用。應用程序不計其數,包括計算機視覺,聊天機器人,無人駕駛汽車,機器翻譯,甚至游戲——同時打敗了全世界最頂級的圍棋手和國際象棋計算機玩家!
深度學習最主要的前提之一是數據增加后持續學習的能力,而這在大數據時代尤為有效(見下圖)。這種持續學習的能力與近來硬件方面的發展(如圖形處理器)互相結合,使大型深度學習工作的執行成為可能。而從前,由于資源限制,這是明令禁止的。
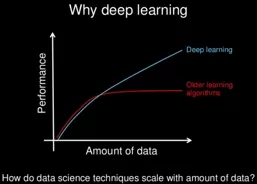
那么,這是否意味著深度學習是處理所有機器學習問題的萬金油呢?并不是。原因如下:
- 簡潔性:神經網絡模型的結果十分依賴其結構以及超參數。大多數情況下,要正確調整模型,你需要有網絡建構方面專業知識。另外,在此方面試錯的步驟也非常重要。
- 可解釋性:如上文提到,相當一部分實際案例不僅需要做出預測,還需要解釋預測背后的原因:為什么貸款申請被拒絕?為什么保險政策價格提高?盡管基于樹型結構和基于系數的算法可以解釋,神經網絡卻不行。
- 質量:從經驗來看,對于大多數結構化的數據集,神經網絡模型的質量并不一定比RandomForests和XGBoot的模型質量更好。當涉及散亂數據(如圖像、文本、音頻)時,深度學習的優勢更為突出。底線是:不要用獵槍去打蒼蠅。RandomForests和XGBoot等機器學習算法已經足以處理大多數結構化的可監測的問題,而這些算法也更容易調整、運用和解釋。深度學習在散亂數據問題和強化學習方面的作用不言而喻。
別泄露數據
處理一個預測航班到達時間延誤的項目時,如果使用數據集里所有可用的特征時,模型的精確度可以達到99%。不過,希望你會意識到,你可能用啟程延誤時間來推測進港延誤時間。這是數據泄露的典型案例。如果我們使用了任何預測時不可用或未知的特征,就會造成數據泄露。大家要當心!
開源軟件里能找到一切資源,平臺還有什么用處?
構建機器學習模型從未像今天這樣簡單。幾行R語言或Python語言代碼足以建構一個模型,在網上甚至還能找到大量培養復雜神經網絡的資源和課程。如今,Apache Spark十分有助于數據準備,它甚至能對大型數據集進行歸一處理。另外,docker和plumber等工具通過超文本傳輸協議(HTTP)簡化了機器學習模型的部署。似乎完全依靠開源平臺資源,就能構建一個端到端的機器學習系統。
就概念驗證而言,可能的確是這樣。一個大學生完全可以依靠開放源代碼完成畢業論文。但于企業而言,事情就沒有這么簡單了。
畢竟開源軟件也存在不少缺陷。以下是幾項企業選擇大數據科學平臺的原因:
- 開放資源整合:幾分鐘內就能開啟運行,支持多種環境,版本更新信息透明。
- 團隊協作:易于共享數據集、數據連結、代碼、模型、環境和部署。
- 管理和安全:不僅能管理數據,還可以對所有分析資產進行管理。
- 模型管理、部署和再陪養
- 模型偏見:檢測并修正有性別或年齡偏見的模型。
- 輔助的數據管理:通過視覺工具來解決數據科學中最困難的問題。
- 圖形處理器:對深度學習框架進行快速部署和配置,以促成其最優表現,如TensorFlow。
- 無代碼建模:專為不會編碼但想建構視覺模型的統計學家、項目專家以及管理人員設計。
















