資深程序員經典總結:MySQL的并發(fā)控制原理
MySQL是主流的開源關系型數據庫,提供高性能的數據存儲服務。我們在做后端開發(fā)時,性能瓶頸往往不是應用本身,而是數據庫層面。所以掌握MySQL的一些底層原理有助于我們更好地理解MySQL,對MySQL進行性能調優(yōu),從而開發(fā)高性能的后端服務。
MySQL的邏輯架構
MySQL的邏輯架構如下圖:
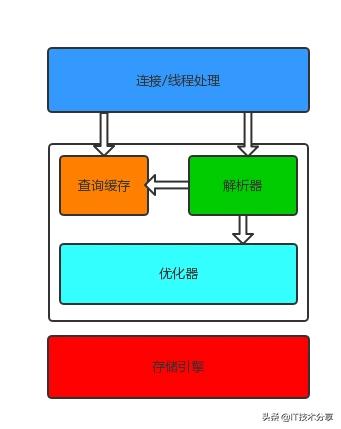
最上層是處理客戶端過來的連接的。主要做連接處理、授權認證、安全等。MySQL在這一層維護了一個線程池,用于處理來自客戶端的連接。MySQL可以使用用戶名密碼認證,也可以使用SSL基于X.509證書認證。
第二層由三部分組成:查詢緩存、解析器、優(yōu)化器。解析器用來解析SQL語句,優(yōu)化器會對解析之后的語句進行優(yōu)化。在解析查詢前,服務器會先檢查查詢緩存,如果能在其中找到對應的查詢結果,則無需再進行查詢解析、優(yōu)化等過程,直接返回查詢結果。存儲過程、觸發(fā)器、視圖等都在這一層實現。
第三層是存儲引擎,存儲引擎負責在MySQL中存儲數據、提取數據、開啟一個事務等等。存儲引擎通過API與上層進行通信,這些API屏蔽了不同存儲引擎之間的差異,使得這些差異對上層查詢過程透明。存儲引擎不會去解析SQL。
Mysql最常用的存儲引擎是InnoDB
Mysql的并發(fā)控制
如果多個線程同時操作數據,就有可能引發(fā)并發(fā)控制的問題。本文接下來將介紹MySQL是如何控制并發(fā)讀寫的。
讀寫鎖
如果多個線程都只是讀數據,其實可以一起讀,不會互相影響,這個時候應該使用“讀鎖”,也稱為共享鎖。獲取讀鎖的線程之間互相不會阻塞,可以同時讀取一個資源。
如果有一個線程需要寫數據,則應該使用“寫鎖”,也成為排它鎖。寫鎖會阻塞其它的寫鎖和讀鎖,直至寫操作完成。
鎖粒度
首先明確一個概念:在給定的資源上,需要加鎖的數據越少,系統(tǒng)能夠承載的并發(fā)量就越高。但加鎖也是需要消耗資源的,如果系統(tǒng)花費大量的時間來管理鎖,而不是存取數據,那么系統(tǒng)的性能可能會因此受影響。
所以一個好的“鎖策略”就是要在鎖的開銷和數據的安全性之間尋求平衡,Mysql支持多個存儲引擎的架構,每種存儲引擎都可以實現自己的鎖策略和鎖粒度。
表鎖和行鎖
表鎖顧名思義就是鎖住整張表。表鎖開銷比較小。對表加寫鎖后,其它用戶對這張表的所有讀寫操作都會被阻塞。在MySQL中,盡管存儲引擎可以提供自己的鎖,但MySQL有時候也會使用表鎖,比如 ALTER TABLE 之類的語句。
寫鎖比讀鎖有更高的優(yōu)先級,因此一個寫鎖請求可能會被插入到讀鎖隊列的前面。
行級鎖即鎖住整行,可以最大程度地支持并發(fā)處理,但加解鎖的開銷也會比較大。行級鎖只在儲存引擎層實現,所有的存儲引擎都以自己的方式實現了行級鎖。
MVCC
MVCC即“多版本并發(fā)控制”,可以認為MVCC是行級鎖的一個變種,但是它在很多情況下避免了加鎖操作,因此開銷更低。
主流的關系型數據庫都實現了MVCC,但實現機制各有不同。實際上MVCC也沒有一個統(tǒng)一的標準。但大都實現了非阻塞的讀操作,寫操作也只是鎖定必要的行。
MVCC保證的是每個事務里面在執(zhí)行期間看到的數據都是一致的。但不同的事務由于開始的時間不同,所以可能對同一張表,同一時刻看到的數據是不一樣的。
在MySQL的InnoDB引擎,是通過給每行記錄后面保存兩個隱藏的列來實現的。一個是保存行的創(chuàng)建時間,另一個保存了行的過期時間(或刪除時間)。
實際上存儲的并不是實際的一個時間戳,而是“系統(tǒng)版本號”。
每次開啟一個事務,系統(tǒng)版本號都會遞增。事務開始時,系統(tǒng)版本號會作為事務的版本號,用來和查詢到的行的版本號進行比較。下面分別介紹常見的CRUD操作中版本號是怎么工作的:
INSERT
保存當前系統(tǒng)版本號作為行版本號
DELETE
保存當前的系統(tǒng)版本號到這行數據的“刪除版本”。
UPDATE
插入一行新紀錄,保存當前系統(tǒng)版本號作為行版本號,同時保存當前系統(tǒng)版本號到原來的行的“刪除版本”。
SELECT
- 只查找版本早于當前事務版本的行。這樣可以保證事務讀取都的行,要么之前就存在,要么是這個事務本身自己插入或者修改的。
- 行的“刪除版本”要么未定義,要么大于當前事務版本號。這樣可以確保事務讀取到的行,在事務之前沒有被刪除。
MVCC只在REPEATABLE READ和READ COMMITTED兩個隔離級別下工作,其它兩個隔離級別不能工作。因為READ UNCOMMITTED總是讀取最新的數據防,而不是符合當前事務版本的數據行。而SERIALIZABLE則會對所有讀取的行都加鎖。