CPU通俗演義及代碼級性能優化實例分析
做任何事情要形成自己的方法體系,這樣在做事情的時候才能游刃有余。前面文章我們簡單介紹了一個簡單的例子,說明了代碼開發中應該如何保證程序的性能。今天我們將更加深入的介紹如何在代碼層面提升程序的性能。并且我們總結為幾種情況,這樣在以后開發中就可以套用。另外,本節我們主要介紹的是代碼級的性能優化,關于涉及操作系統甚至整個分布式大系統的性能優化我們另外單獨介紹。
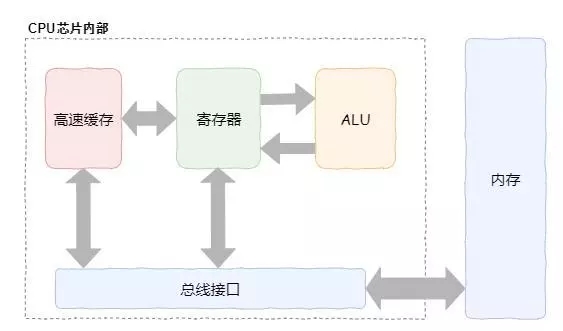
程序是運行在CPU之上的,因此在介紹性能優化之前我們有必要介紹一下CPU的內核結構。在前文中我們對CPU進行了簡化處理(如圖1),實際上CPU的結構非常復雜,畢竟一顆CPU由幾十億個晶體管組成的。
CPU通俗演義
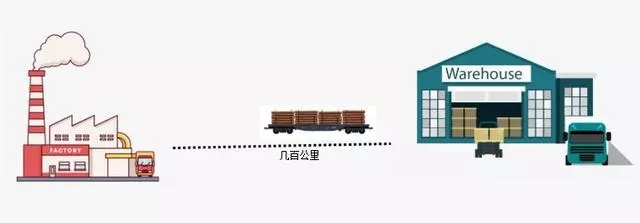
CPU的作用很好理解,它就是一個數據加工部件。CPU就像一個大型的工廠,它將原料(數據)加工成半成品和成品;而內存則像一個大型的倉庫。雖然CPU與內存都在機箱中,但CPU訪問內存中的數據并不是非常方便,就好像工廠和大型倉庫之間的距離,有幾百公里。從倉庫向工廠運算原材料需要用火車才行,運輸一次材料可能要幾個小時。
在這個大型工廠(CPU)里面有很多東西,最為重要的就是車間(CPU核)、生產線(ALU)、物料暫存區(寄存器)、工廠小倉庫(緩存)等內容。為了更好理解上面這些內容的關系,這里做了一個簡化的平面圖。

工廠加工產品所需要的原材料需要從外面的大型倉庫運輸過來。由于從工廠外大型倉庫到工廠的距離比較遠,耗時比較長,因此總是有計劃的,批量的將物料從工廠外的大倉庫運輸到工廠內的小倉庫。工廠的車間突然需要一些原材料,那就只能讓火車重新跑一趟了。
運輸過來的原材料不能亂放,否則要是下雨刮風啥的不就損壞了。因此,原材料會被統一的放在工廠內的小倉庫(CPU緩存)里面,各個車間根據需要從小倉庫運輸原材料到車間。
在車間有個暫存區(寄存器),用于存放從小倉庫運過來的材料。當然暫存區除了放原材料之外,還會放一些半成品和成品。車間有車間的秩序,不能亂放,否則會出問題的。暫存區是很有必要的,要不然需要點材料就去倉庫拿,那不得類似工人啊。
有了原材料之后,工人就可以將原材料放到生產線(ALU)上進行生產了。生產完成的成品又會放回暫存區,然后運輸出去。暫存區和生產線都在車間里面,搬運原材料和成品都很快,幾乎是一兩分鐘就可以完成。
關于流水線
為了提高產品生產速度,在一個車間里面通常是有多個生產線的。每一個生產線的大概流程是運輸原材料、原材料預處理(比如撕掉包裝或者切成小塊等)、原材料加工和成品運回暫存區等步驟。CPU也是有類似的流水線的,任何一個指令都要經過讀取指令、譯碼、執行和寫回(寄存器或者內存)等。
以一個生產黃桃罐頭的車間為例,在這個車間里面要同時生產罐頭瓶、罐頭瓶蓋和糖水黃桃(這里是假設,實際工廠不是這樣)。因此,也就有生產罐頭瓶的流水線、生產罐頭瓶蓋的流水線和生產糖水黃桃的流水線。通常我們安排的流程是先生產罐頭瓶和瓶蓋,這樣生產的糖水黃桃就可以裝瓶完成成品了。但是,有的時候可能運送暫存區或者工廠的小倉庫沒有玻璃了,這樣就沒法生產罐頭瓶。不過沒關系,車間還是可以先生產糖水黃桃的,生產完之后先放到暫存區,等什么時候罐頭瓶生產完之后在裝瓶。
上面這個流程其實就是所謂的指令亂序。也就是CPU在執行指令的時候并不是按我們寫代碼的順序執行的,而可能會打亂順序。比如下面這段代碼,由于兩行代碼之間沒有任何依賴,因此在CPU中可能會先執行b=2,后執行a=1。
- int a = 1;
- int b = 2;
存儲的金字塔結構
另外一個比較重要的知識點是需要知道軟件開發涉及的存儲金字塔。具體如圖所示,其中寄存器、一級緩存、二級緩存和三級緩存是CPU內部的部件,然后是內存和磁盤。最后是遠程存儲,比如SAN、NAS或者對象存儲或者云計算中的云盤等存儲都屬于遠程存儲。
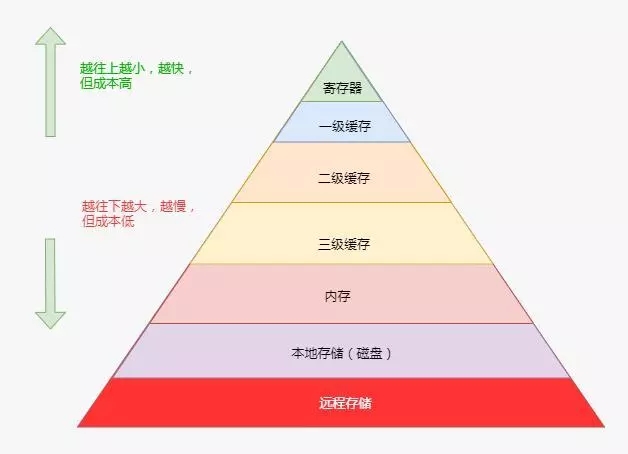
通常來說越往金字塔底部,容量越大,但延遲也越大,性能越差。這里面有個特例,就是本地存儲和遠程存儲,如果遠程存儲采用的介質與本地相同,則肯定遠程存儲性能要差一些。但當前有些分布式存儲,通信鏈路采用RDMA,存儲介質采用SSD,那么本地的機械磁盤就要比遠程存儲性能差了。
了解了這個結構之后,我們總結一下。其實性能問題總結起來就是一句話,盡量少的使用計算資源(比如不同的排序算法),盡量多的用金字塔頂部的部件存儲要訪問數據(比如文件系統的緩存)。
程序性能分析工具
正所謂:“欲善其事,必先利其器”。因此,要想進行性能優化,自然需要有相應的工具進行分析。本文僅針對Linux操作系統進行介紹,其它操作系統實在是不熟悉。在Linux操作系統下面,用的最多的性能分析工具恐怕非top莫屬。
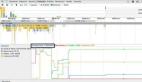
(1) top命令
top命令可以實時的觀察進程的計算資源使用情況(CPU利用率)和整個系統的綜合負載。如圖是我們通過一個Python腳本模擬高負債程序,可以看到起CPU利用率已經達到100%。
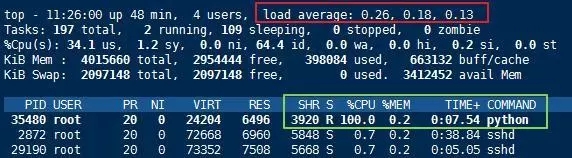
top工具可以幫助我們分析高度消耗計算資源的程序的性能。另外還有其它性能分析工具,比如ps、vmstat、mpstat和prstat等等。工具比較多,限于篇幅問題,本文暫時就不做介紹了。
性能優化方法總結
有了前面的準備知識后,下面我們進入正題。本節內容總結了在程序代碼級別常見的問題,并結合實例給出了解決方法,下面我們逐個分析一下。
1. 優化程序代碼結構
這種問題的原因在于程序代碼結構不合理,導致過度使用計算資源。如果往高大上的說,那就是算法不行。比如下面兩段程序,前一段程序在for循環的條件判斷中有一個strlen調用,用于判斷字符串的長度。而后一段代碼則將strlen移到條件判斷外面。
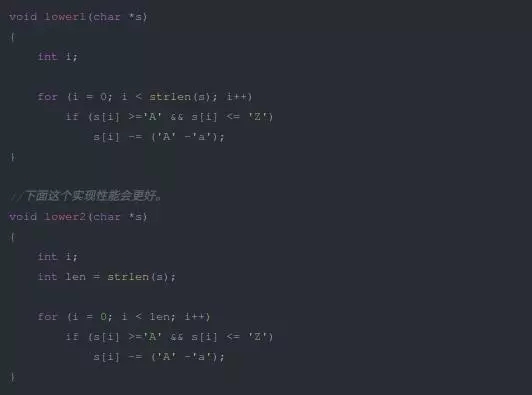
如果字符串大的情況下,這兩個程序的性能差異可能有百倍。這個主要是因為strlen函數其實是個循環判斷,需要消耗大量的計算資源。
另外一種最為常見例子是關于排序算法的,比如冒泡排序的性能比快速排序差。因為兩者計算量(時間復雜度)不同,所以算法的性能自然就不同。
2. 運算符合理選擇
這部分也是針對計算資源消耗的優化。在介紹這部分內容之前,我們腦子里要有個概念。就是不同的運算(加減乘除)消耗的計算資源是不同的,其中加減、位運算和移位操作最低,可以認為是1,那么乘法則是3-4,而除法則大概是10-30左右。
了解上上面的內容之后,那我們在程序開發中就要盡量少用除法運算,因為它的性價比實在不高(太消耗計算資源)。有人可能會想怎么可能?有的時候就要用除法怎么辦?下面我們看一個例子,這個例子是JDK中關于Hashmap的實現。
Hashmap是通過哈希表實現的,哈希表的概念這里就不啰嗦了。在查找或者存儲的時候需要根據Key值取模,定位元素的位置。通常我們能想到的方法就是取模的運算符(計算量類似除法),但在Hashmap中卻沒有用取模運算符,而是用的位運算。這樣,整個性能就會有十倍以上的提升,如下是它的代碼。
- static int indexFor(int h, int length) {
- return h & (length-1);
- }
3. 減少對內存的訪問
通過前面的準備知識我們知道內存的訪問比寄存器慢100倍,因此在寫代碼的時候盡量減少對內存的訪問。那么怎么減少對內存的訪問呢?我們仍然看一個例子,比如一個簡單的累加運算(這個例子比較極端)。前者是通過全局變量存儲累加和,而后者是通過局部變量。
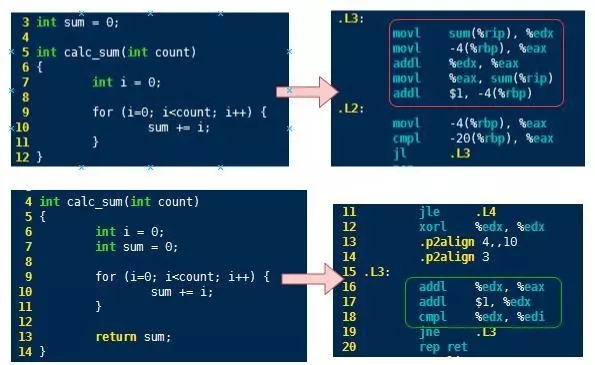
為了深入的了解兩者差異,我們需要對程序進行反匯編,然后對比一下反匯編代碼。對比上線代碼可以看出前者每次計算都有訪問多次內存(其中帶圓括弧的匯編語句),而后者則將其轉換成了寄存器訪問。
雖然我們通常認為局部變量在函數棧中(內存空間),但實際上編譯器在進行程序編譯的時候會對代碼進行優化,將局部變量優化為寄存器。因此,我們在實際開發的時候盡量使用局部變量,減少對內存的訪問。
4. 減少對磁盤的訪問
道理跟前面一個是一樣的,還是那個存儲金字塔。如果你的程序有很多對磁盤的訪問,性能通常不會好到那去。通常的方法是使用內存作為緩存。在磁盤方面性能優化最經典的例子恐怕就是文件系統的頁緩存了。也就是文件系統寫入的數據不會馬上寫到磁盤,而是先寫到緩存(內存)中。而讀數據的時候則是通過預讀機制提前將數據讀入內存,文件系統從內存讀數據,而不是從磁盤。由于內存的性能是機械磁盤的十萬倍以上,因此文件系統的性能得以大大提高(這里有場景限制,我們后面再詳細介紹)。
另外一個經典案例還是文件系統相關的,這個就是Linux的虛擬文件系統(VFS)。我們知道文件系統每個文件都對應著一個inode,而inode也是存儲在磁盤上的。如果我們要打開一個文件,首先需要從磁盤找到inode,然后讀取到內存,然后才能進行后續的讀寫操作。
在VFS中,在文件打開的時候,VFS會將inode放入一個內存中的哈希表中,而且在關閉文件的情況下并不釋放。這樣,當應用程序再次打開文件的時候就可以直接從內存找到該inode,而不用重新讀磁盤了。
上面這些都是特例,大家要融會貫通,希望對大家的軟件設計有所幫助。最后,性能優化本質,還是那一句話,盡量少的使用計算資源,盡量多的用金字塔頂部的部件存儲要訪問數據。