PyTorch的4分鐘教程,手把手教你完成線性回歸
大數據文摘出品
編譯:洪穎菲、寧靜
PyTorch深度學習框架庫之一,是來自Facebook的開源深度學習平臺,提供研究原型到生產部署的無縫銜接。
本文旨在介紹PyTorch基礎部分,幫助新手在4分鐘內實現python PyTorch代碼的初步編寫。
下文出現的所有功能函數,均可以在中文文檔中查看具體參數和實現細節,先附上pytorch中文文檔鏈接:
https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch/
coding前的準備
需要在電腦上安裝Python包,導入一些科學計算包,如:numpy等,最最重要的,別忘記導入PyTorch,下文的運行結果均是在jupyter notebook上得到的,感興趣的讀者可以自行下載Anaconda,里面自帶有jupyter notebook。(注:Anaconda支持python多個版本的虛擬編譯環境,jupyter notebook是一個web形式的編譯界面,將代碼分割成一個個的cell,可以實時看到運行結果,使用起來非常方便!)
軟件的配置和安裝部分,網上有很多教程,這里不再贅述,紙上得來終覺淺,絕知此事要躬行。讓我們直接進入Pytorch的世界,開始coding吧!
Tensors
Tensor張量類型,是神經網絡框架中重要的基礎數據類型,可以簡單理解為一個包含單個數據類型元素的多維矩陣,tensor之間的通過運算進行連接,從而形成計算圖。
下面的代碼實例中創建了一個2*3的二維張量x,指定數據類型為浮點型(Float):
- import torch
- #Tensors
- x=torch.FloatTensor([[1,2,3],[4,5,6]])
- print(x.size(),"\n",x)
運行結果:

PyTorch包含許多關于tensors的數學運算。除此之外,它還提供了許多實用程序,如高效序列化Tensor和其他任意數據類型,以及其他有用的實用程序。
下面是Tensor的加法/減法的一個例子,其中torch.ones(*sizes, out=None) → Tensor返回一個全為1 的張量,形狀由可變參數sizes定義。在實例中,和變量x相加的是創建的兩個相應位置值為1的2*3的張量,相當于x每一維度的值+2,代碼和運行結果如下所示:
- #Add tensors
- x.add_(torch.ones([2,3])+torch.ones([2,3]))
運行結果:

同樣的,PyTorch也支持減法操作,實例如下,在上面的運行結果基礎上每一維度再減去2,x恢復到最初的值。
- #Subtract Tensor
- x.sub_(torch.ones([2,3])*2)
運行結果:
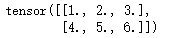
其他PyTorch運算讀者可以查閱上文給出的中文鏈接。
PyTorch and NumPy
用戶可以輕松地在PyTorch和NumPy之間來回轉換。
下面是將np.matrix轉換為PyTorch并將維度更改為單個列的簡單示例:
- #Numpy to torch tensors
- import numpy as np
- y=np.matrix([[2,2],[2,2],[2,2]])
- z=np.matrix([[2,2],[2,2],[2,2]],dtype="int16")
- x.short() @ torch.from_numpy(z)
運行結果:

其中@為張量乘法的重載運算符,x為2*3的張量,值為[[1,2,3],[4,5,6]],與轉換成tensor的z相乘,z的大小是3*2,結果為2*2的張量。(與矩陣乘法類似,不明白運行結果的讀者,可以看下矩陣的乘法運算)
除此外,PyTorch也支持張量結構的重構reshape,下面是將張量x重構成1*6的一維張量的實例,與numpy中的reshape功能類似。
- #Reshape tensors(similar to np.reshape)
- x.view(1,6)
運行結果:

GitHub repo概述了PyTorch到numpy的轉換,鏈接如下:
https://github.com/wkentaro/pytorch-for-numpy-users
CPU and GPUs
PyTorch允許變量使用 torch.cuda.device上下文管理器動態更改設備。以下是示例代碼:
- #move variables and copies across computer devices
- x=torch.FloatTensor([[1,2,3],[4,5,6]])
- y=np.matrix([[2,2,2],[2,2,2]],dtype="float32")
- if(torch.cuda.is_available()):
- xx=x.cuda();
- y=torch.from_numpy(y).cuda()
- z=x+y
- print(z)
- print(x.cpu())
運行結果:

PyTorch Variables
變量只是一個包裹著Tensor的薄層,它支持幾乎所有由Tensor定義的API,變量被巧妙地定義為自動編譯包的一部分。它提供了實現任意標量值函數自動區分的類和函數。
以下是PyTorch變量用法的簡單示例,將v1和v2相乘的結果賦值給v3,其中里面的參數requires_grad的屬性默認為False,若一個節點requires_grad被設置為True,那么所有依賴它的節點的requires_grad都為True,主要用于梯度的計算。
- #Variable(part of autograd package)
- #Variable (graph nodes) are thin wrappers around tensors and have dependency knowle
- #Variable enable backpropagation of gradients and automatic differentiations
- #Variable are set a 'volatile' flad during infrencing
- from torch.autograd import Variable
- v1 = Variable(torch.tensor([1.,2.,3.]), requires_grad=False)
- v2 = Variable(torch.tensor([4.,5.,6.]), requires_grad=True)
- v3 = v1*v2
- v3.data.numpy()
運行結果:
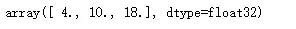
- #Variables remember what created them
- v3.grad_fn
運行結果:
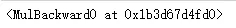
Back Propagation
反向傳播算法用于計算相對于輸入權重和偏差的損失梯度,以在下一次優化迭代中更新權重并最終減少損失,PyTorch在分層定義對于變量的反向方法以執行反向傳播方面非常智能。
以下是一個簡單的反向傳播計算方法,以sin(x)為例計算差分:
- #Backpropagation with example of sin(x)
- x=Variable(torch.Tensor(np.array([0.,1.,1.5,2.])*np.pi),requires_grad=True)
- y=torch.sin(x)
- x.grad
- y.backward(torch.Tensor([1.,1.,1.,1]))
- #Check gradient is indeed cox(x)
- if( (x.grad.data.int().numpy()==torch.cos(x).data.int().numpy()).all() ):
- print ("d(sin(x)/dx=cos(x))")
運行結果:
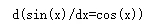
對于pytorch中的變量和梯度計算可參考下面這篇文章:
https://zhuanlan.zhihu.com/p/29904755
SLR: Simple Linear Regression
現在我們了解了基礎知識,可以開始運用PyTorch 解決簡單的機器學習問題——簡單線性回歸。我們將通過4個簡單步驟完成:
第一步:
在步驟1中,我們創建一個由方程y = wx + b產生的人工數據集,并注入隨機誤差。請參閱以下示例:
- #Simple Liner Regression
- # Fit a line to the data. Y =w.x+b
- #Deterministic behavior
- np.random.seed(0)
- torch.manual_seed(0)
- #Step 1:Dataset
- w=2;b=3
- x=np.linspace(0,10,100)
- y=w*x+b+np.random.randn(100)*2
- xx=x.reshape(-1,1)
- yy=y.reshape(-1,1)
第二步:
在第2步中,我們使用forward函數定義一個簡單的類LinearRegressionModel,使用torch.nn.Linear定義構造函數以對輸入數據進行線性轉換:
- #Step 2:Model
- class LinearRegressionModel(torch.nn.Module):
- def __init__(self,in_dimn,out_dimn):
- super(LinearRegressionModel,self).__init__()
- self.model=torch.nn.Linear(in_dimn,out_dimn)
- def forward(self,x):
- y_pred=self.model(x);
- return y_pred;
- model=LinearRegressionModel(in_dimn=1, out_dimn=1)
torch.nn.Linear參考網站:
https://pytorch.org/docs/stable/_modules/torch/nn/modules/linear.html
第三步:
下一步:使用 MSELoss 作為代價函數,SGD作為優化器來訓練模型。
- #Step 3: Training
- cost=torch.nn.MSELoss()
- optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
- inputs=Variable(torch.from_numpy(x.astype("float32")))
- outputs=Variable(torch.from_numpy(y.astype("float32")))
- for epoch in range(100):
- #3.1 forward pass:
- y_pred=model(inputs)
- #3.2 compute loss
- loss=cost(y_pred,outputs)
- #3.3 backward pass
- optimizer.zero_grad();
- loss.backward()
- optimizer.step()
- if((epoch+1)%10==0):
- print("epoch{},loss{}".format(epoch+1,loss.data))
運行結果:

- MSELoss參考網站:https://pytorch.org/docs/stable/_modules/torch/nn/modules/loss.html
- SGD參考網站:https://pytorch.org/docs/stable/_modules/torch/optim/sgd.html
第四步:
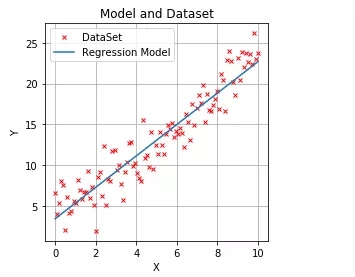
現在訓練已經完成,讓我們直觀地檢查我們的模型:
- #Step 4:Display model and confirm
- import matplotlib.pyplot as plt
- plt.figure(figsize=(4,4))
- plt.title("Model and Dataset")
- plt.xlabel("X");plt.ylabel("Y")
- plt.grid()
- plt.plot(x,y,"ro",label="DataSet",marker="x",markersize=4)
- plt.plot(x,model.model.weight.item()*x+model.model.bias.item(),label="Regression Model")
- plt.legend();plt.show()
運行結果:
現在你已經完成了PyTorch的第一個線性回歸例子的編程了,對于后續希望百尺竿頭,更進一步的讀者來說,可以參考PyTorch的官方文檔鏈接,完成大部分的編碼應用。
相關鏈接:
https://medium.com/towards-artificial-intelligence/pytorch-in-2-minutes-9e18875990fd
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】