













從小白到大師,這里有一份Pandas入門指南
通過本文,你將有望發現一到多種用 pandas 編碼的新方法。
本文包括以下內容:
- Pandas 發展現狀;
- 內存優化;
- 索引;
- 方法鏈;
- 隨機提示。
在閱讀本文時,我建議你閱讀每個你不了解的函數的文檔字符串(docstrings)。簡單的 Google 搜索和幾秒鐘 Pandas 文檔的閱讀,都會使你的閱讀體驗更加愉快。
一、Pandas 的定義和現狀
1. 什么是 Pandas?
Pandas 是一個「開源的、有 BSD 開源協議的庫,它為 Python 編程語言提供了高性能、易于使用的數據架構以及數據分析工具」。總之,它提供了被稱為 DataFrame 和 Series(對那些使用 Panel 的人來說,它們已經被棄用了)的數據抽象,通過管理索引來快速訪問數據、執行分析和轉換運算,甚至可以繪圖(用 matplotlib 后端)。
Pandas 的當前最新版本是 v0.25.0
(https://github.com/pandas-dev/pandas/releases/tag/v0.25.0)

Pandas 正在逐步升級到 1.0 版,而為了達到這一目的,它改變了很多人們習以為常的細節。Pandas 的核心開發者之一 Marc Garcia 發表了一段非常有趣的演講——「走向 Pandas 1.0」。
演講鏈接:https://www.youtube.com/watch?v=hK6o_TDXXN8
用一句話來總結,Pandas v1.0 主要改善了穩定性(如時間序列)并刪除了未使用的代碼庫(如 SparseDataFrame)。
2. 數據
讓我們開始吧!選擇「1985 到 2016 年間每個國家的自殺率」作為玩具數據集。這個數據集足夠簡單,但也足以讓你上手 Pandas。
數據集鏈接:
https://www.kaggle.com/russellyates88/suicide-rates-overview-1985-to-2016
在深入研究代碼之前,如果你想重現結果,要先執行下面的代碼準備數據,確保列名和類型是正確的。
- import pandas as pd
- import numpy as np
- import os
- # to download https://www.kaggle.com/russellyates88/suicide-rates-overview-1985-to-2016
- data_path = 'path/to/folder/'
- df = (pd.read_csv(filepath_or_buffer=os.path.join(data_path, 'master.csv'))
- .rename(columns={'suicides/100k pop' : 'suicides_per_100k', ' gdp_for_year ($) ' : 'gdp_year', 'gdp_per_capita ($)' : 'gdp_capita', 'country-year' : 'country_year'})
- .assign(gdp_year=lambda _df: _df['gdp_year'].str
- .replace(',','').astype(np.int64)) )
提示:如果你讀取了一個大文件,在 read_csv(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html)中參數設定為 chunksize=N,這會返回一個可以輸出 DataFrame 對象的迭代器。
這里有一些關于這個數據集的描述:
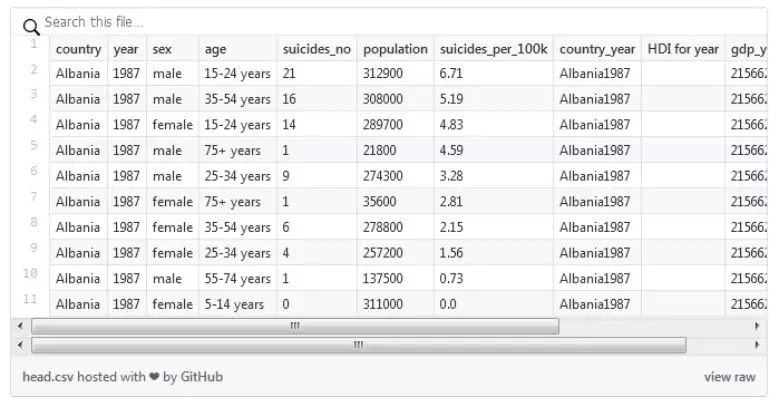
- >>> df.columnsIndex(['country', 'year', 'sex', 'age', 'suicides_no', 'population', 'suicides_per_100k', 'country_year', 'HDI for year', 'gdp_year', 'gdp_capita', 'generation'], dtype='object')
這里有 101 個國家、年份從 1985 到 2016、兩種性別、六個年代以及六個年齡組。有一些獲得這些信息的方法:
可以用 unique() 和 nunique() 獲取列內唯一的值(或唯一值的數量);
- >>> df['generation'].unique()
- array(['Generation X', 'Silent', 'G.I. Generation', 'Boomers', 'Millenials', 'Generation Z'], dtype=object)
- >>> df['country'].nunique()
- 101
可以用 describe() 輸出每一列不同的統計數據(例如最小值、最大值、平均值、總數等),如果指定 include='all',會針對每一列目標輸出唯一元素的數量和出現最多元素的數量;
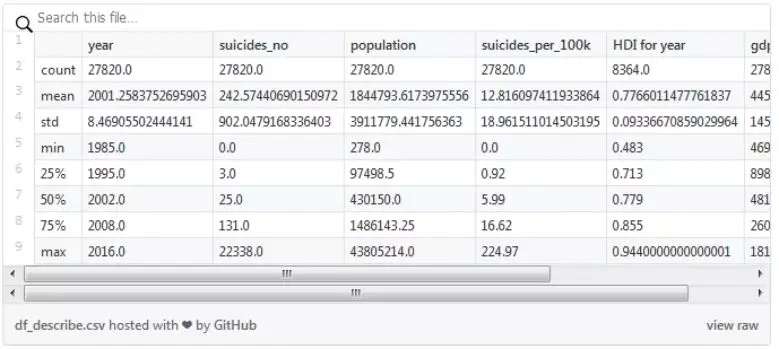
可以用 head() 和 tail() 來可視化數據框的一小部分。
通過這些方法,你可以迅速了解正在分析的表格文件。
二、內存優化
在處理數據之前,了解數據并為數據框的每一列選擇合適的類型是很重要的一步。
在內部,Pandas 將數據框存儲為不同類型的 numpy 數組(比如一個 float64 矩陣,一個 int32 矩陣)。
有兩種可以大幅降低內存消耗的方法。
- import pandas as pd
- def mem_usage(df: pd.DataFrame) -> str:
- """This method styles the memory usage of a DataFrame to be readable as MB. Parameters ---------- df: pd.DataFrame Data frame to measure. Returns ------- str Complete memory usage as a string formatted for MB. """
- return f'{df.memory_usage(deep=True).sum() / 1024 ** 2 : 3.2f} MB'
- def convert_df(df: pd.DataFrame, deep_copy: bool = True) -> pd.DataFrame:
- """Automatically converts columns that are worth stored as ``categorical`` dtype. Parameters ---------- df: pd.DataFrame Data frame to convert. deep_copy: bool Whether or not to perform a deep copy of the original data frame. Returns ------- pd.DataFrame Optimized copy of the input data frame. """
- return df.copy(deep=deep_copy).astype({ col: 'category' for col in df.columns if df[col].nunique() / df[col].shape[0] < 0.5})
Pandas 提出了一種叫做 memory_usage() 的方法,這種方法可以分析數據框的內存消耗。在代碼中,指定 deep=True 來確保考慮到了實際的系統使用情況。
memory_usage():
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.memory_usage.html
了解列的類型
(https://pandas.pydata.org/pandas-docs/stable/getting_started/basics.html#basics-dtypes)很重要。它可以通過兩種簡單的方法節省高達 90% 的內存使用:
- 了解數據框使用的類型;
- 了解數據框可以使用哪種類型來減少內存的使用(例如,price 這一列值在 0 到 59 之間,只帶有一位小數,使用 float64 類型可能會產生不必要的內存開銷)
除了降低數值類型的大小(用 int32 而不是 int64)外,Pandas 還提出了分類類型:https://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html
如果你是用 R 語言的開發人員,你可能覺得它和 factor 類型是一樣的。
這種分類類型允許用索引替換重復值,還可以把實際值存在其他位置。教科書中的例子是國家。和多次存儲相同的字符串「瑞士」或「波蘭」比起來,為什么不簡單地用 0 和 1 替換它們,并存儲在字典中呢?
- categorical_dict = {0: 'Switzerland', 1: 'Poland'}
Pandas 做了幾乎相同的工作,同時添加了所有的方法,可以實際使用這種類型,并且仍然能夠顯示國家的名稱。
回到 convert_df() 方法,如果這一列中的唯一值小于 50%,它會自動將列類型轉換成 category。這個數是任意的,但是因為數據框中類型的轉換意味著在 numpy 數組間移動數據,因此我們得到的必須比失去的多。
接下來看看數據中會發生什么。
- >>> mem_usage(df)
- 10.28 MB
- >>> mem_usage(df.set_index(['country', 'year', 'sex', 'age']))
- 5.00 MB
- >>> mem_usage(convert_df(df))
- 1.40 MB
- >>> mem_usage(convert_df(df.set_index(['country', 'year', 'sex', 'age'])))
- 1.40 MB
通過使用「智能」轉換器,數據框使用的內存幾乎減少了 10 倍(準確地說是 7.34 倍)。
三、索引
Pandas 是強大的,但也需要付出一些代價。當你加載 DataFrame 時,它會創建索引并將數據存儲在 numpy 數組中。這是什么意思?一旦加載了數據框,只要正確管理索引,就可以快速地訪問數據。
訪問數據的方法主要有兩種,分別是通過索引和查詢訪問。根據具體情況,你只能選擇其中一種。但在大多數情況中,索引(和多索引)都是最好的選擇。我們來看下面的例子:
- >>> %%time
- >>> df.query('country == "Albania" and year == 1987 and sex == "male" and age == "25-34 years"')
- CPU times: user 7.27 ms, sys: 751 µs, total: 8.02 ms
- # ==================
- >>> %%time
- >>> mi_df.loc['Albania', 1987, 'male', '25-34 years']
什么?加速 20 倍?
你要問自己了,創建這個多索引要多長時間?
- %%time
- mi_df = df.set_index(['country', 'year', 'sex', 'age'])
- CPU times: user 10.8 ms, sys: 2.2 ms, total: 13 ms
通過查詢訪問數據的時間是 1.5 倍。如果你只想檢索一次數據(這種情況很少發生),查詢是正確的方法。否則,你一定要堅持用索引,CPU 會為此感激你的。
.set_index(drop=False) 允許不刪除用作新索引的列。
.loc[]/.iloc[] 方法可以很好地讀取數據框,但無法修改數據框。如果需要手動構建(比如使用循環),那就要考慮其他的數據結構了(比如字典、列表等),在準備好所有數據后,創建 DataFrame。否則,對于 DataFrame 中的每一個新行,Pandas 都會更新索引,這可不是簡單的哈希映射。
- >>> (pd.DataFrame({'a':range(2), 'b': range(2)}, index=['a', 'a']) .loc['a'])
- a b
- a 0 0
- a 1 1
因此,未排序的索引可以降低性能。為了檢查索引是否已經排序并對它排序,主要有兩種方法:
- %%time
- >>> mi_df.sort_index()
- CPU times: user 34.8 ms, sys: 1.63 ms, total: 36.5 ms
- >>> mi_df.index.is_monotonicTrue
更多詳情請參閱:
- Pandas 高級索引用戶指南:https://pandas.pydata.org/pandas-docs/stable/user_guide/advanced.html;
- Pandas 庫中的索引代碼:https://github.com/pandas-dev/pandas/blob/master/pandas/core/indexing.py。
四、方法鏈
使用 DataFrame 的方法鏈是鏈接多個返回 DataFrame 方法的行為,因此它們都是來自 DataFrame 類的方法。在現在的 Pandas 版本中,使用方法鏈是為了不存儲中間變量并避免出現如下情況:
- import numpy as np
- import pandas as pd
- df = pd.DataFrame({'a_column': [1, -999, -999], 'powerless_column': [2, 3, 4], 'int_column': [1, 1, -1]})
- df['a_column'] = df['a_column'].replace(-999, np.nan)
- df['power_column'] = df['powerless_column'] ** 2
- df['real_column'] = df['int_column'].astype(np.float64)
- dfdf = df.apply(lambda _df: _df.replace(4, np.nan))
- dfdf = df.dropna(how='all')
用下面的鏈替換:
- df = (pd.DataFrame({'a_column': [1, -999, -999],
- 'powerless_column': [2, 3, 4],
- 'int_column': [1, 1, -1]})
- .assign(a_column=lambda _df: _df['a_column'].replace(-999, np.nan))
- .assign(power_column=lambda _df: _df['powerless_column'] ** 2)
- .assign(real_column=lambda _df: _df['int_column'].astype(np.float64))
- .apply(lambda _df: _df.replace(4, np.nan))
- .dropna(how='all') )
說實話,第二段代碼更漂亮也更簡潔。

方法鏈的工具箱是由不同的方法(比如 apply、assign、loc、query、pipe、groupby 以及 agg)組成的,這些方法的輸出都是 DataFrame 對象或 Series 對象(或 DataFrameGroupBy)。
了解它們最好的方法就是實際使用。舉個簡單的例子:
- (df
- .groupby('age')
- .agg({'generation':'unique'})
- .rename(columns={'generation':'unique_generation'})
- # Recommended from v0.25
- # .agg(unique_generation=('generation', 'unique')))
獲得每個年齡范圍中所有唯一年代標簽的簡單鏈。
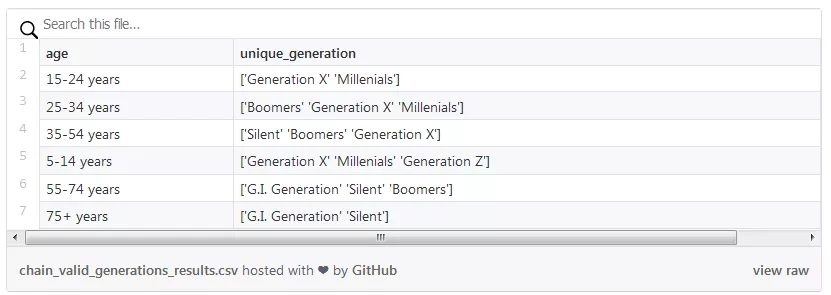
在得到的數據框中,「年齡」列是索引
除了了解到「X 代」覆蓋了三個年齡組外,分解這條鏈。第一步是對年齡組分組。這一方法返回了一個 DataFrameGroupBy 對象,在這個對象中,通過選擇組的唯一年代標簽聚合了每一組。
在這種情況下,聚合方法是「unique」方法,但它也可以接受任何(匿名)函數。
在 0.25 版本中,Pandas 引入了使用 agg 的新方法:
https://dev.pandas.io/whatsnew/v0.25.0.html#groupby-aggregation-with-relabeling。
- (df
- .groupby(['country', 'year'])
- .agg({'suicides_per_100k': 'sum'})
- .rename(columns={'suicides_per_100k':'suicides_sum'})
- # Recommended from v0.25
- # .agg(suicides_sum=('suicides_per_100k', 'sum')) .sort_values('suicides_sum', ascending=False) .head(10))
用排序值(sort_values)和 head 得到自殺率排前十的國家和年份
- (df
- .groupby(['country', 'year'])
- .agg({'suicides_per_100k': 'sum'})
- .rename(columns={'suicides_per_100k':'suicides_sum'})
- # Recommended from v0.25
- # .agg(suicides_sum=('suicides_per_100k', 'sum'))
- .nlargest(10, columns='suicides_sum'))
用排序值 nlargest 得到自殺率排前十的國家和年份
在這些例子中,輸出都是一樣的:有兩個指標(國家和年份)的 MultiIndex 的 DataFrame,還有包含排序后的 10 個最大值的新列 suicides_sum。
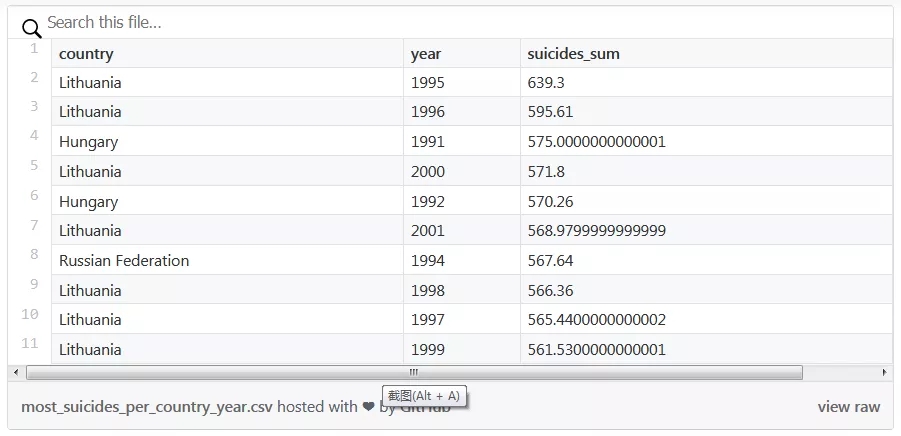
「國家」和「年份」列是索引
nlargest(10) 比 sort_values(ascending=False).head(10) 更有效。
另一個有趣的方法是 unstack:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.unstack.html,這種方法允許轉動索引水平。
- (mi_df
- .loc[('Switzerland', 2000)]
- .unstack('sex') [['suicides_no', 'population']])
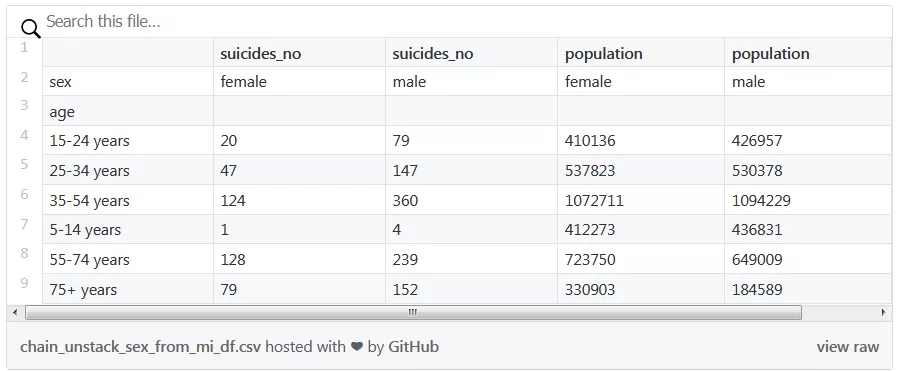
「age」是索引,列「suicides_no」和「population」都有第二個水平列「sex」。
下一個方法 pipe 是最通用的方法之一。這種方法允許管道運算(就像在 shell 腳本中)執行比鏈更多的運算。
管道的一個簡單但強大的用法是記錄不同的信息。
- def log_head(df, head_count=10):
- print(df.head(head_count))
- return df
- def log_columns(df):
- print(df.columns)
- return df
- def log_shape(df):
- print(f'shape = {df.shape}')
- return df
和 pipe 一起使用的不同記錄函數。
舉個例子,我們想驗證和 year 列相比,country_year 是否正確:
- (df
- .assign(valid_cy=lambda _serie: _serie.apply(
- lambda _row: re.split(r'(?=\d{4})',
- _row['country_year'])[1] == str(_row['year']), axis=1))
- .query('valid_cy == False')
- .pipe(log_shape))
用來驗證「country_year」列中年份的管道。
管道的輸出是 DataFrame,但它也可以在標準輸出(console/REPL)中打印。
- shape = (0, 13)
你也可以在一條鏈中用不同的 pipe。
- (df .pipe(log_shape)
- .query('sex == "female"')
- .groupby(['year', 'country'])
- .agg({'suicides_per_100k':'sum'})
- .pipe(log_shape)
- .rename(columns={'suicides_per_100k':'sum_suicides_per_100k_female'})
- # Recommended from v0.25
- # .agg(sum_suicides_per_100k_female=('suicides_per_100k', 'sum'))
- .nlargest(n=10, columns=['sum_suicides_per_100k_female']))
女性自殺數量最高的國家和年份。
生成的 DataFrame 如下所示:
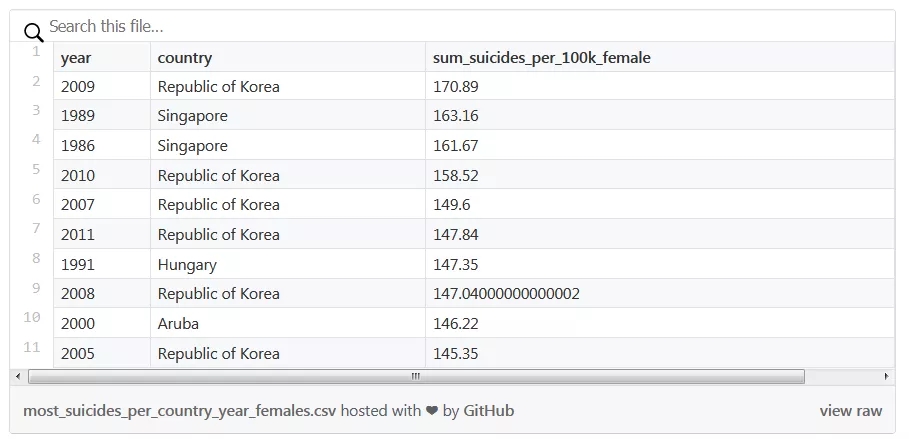
索引是「年份」和「國家」
標準輸出的打印如下所示:
- shape = (27820, 12)
- shape = (2321, 1)
除了記錄到控制臺外,pipe 還可以直接在數據框的列上應用函數。
- from sklearn.preprocessing import MinMaxScaler
- def norm_df(df, columns):
- return df.assign(**{col: MinMaxScaler().fit_transform(df[[col]].values.astype(float))
- for col in columns})
- for sex in ['male', 'female']:
- print(sex)
- print( df .query(f'sex == "{sex}"')
- .groupby(['country'])
- .agg({'suicides_per_100k': 'sum', 'gdp_year': 'mean'})
- .rename(columns={'suicides_per_100k':'suicides_per_100k_sum', 'gdp_year': 'gdp_year_mean'})
- # Recommended in v0.25
- # .agg(suicides_per_100k=('suicides_per_100k_sum', 'sum'),
- # gdp_year=('gdp_year_mean', 'mean'))
- .pipe(norm_df, columns=['suicides_per_100k_sum', 'gdp_year_mean'])
- .corr(method='spearman') )
- print('\n')
自殺數量是否和 GDP 的下降相關?是否和性別相關?
上面的代碼在控制臺中的打印如下所示:
- male
- suicides_per_100k_sum gdp_year_mean
- suicides_per_100k_sum 1.000000 0.421218
- gdp_year_mean 0.421218 1.000000
- female
- suicides_per_100k_sum gdp_year_mean
- suicides_per_100k_sum 1.000000 0.452343
- gdp_year_mean 0.452343
深入研究代碼。norm_df() 將一個 DataFrame 和用 MinMaxScaling 擴展列的列表當做輸入。使用字典理解,創建一個字典 {column_name: method, …},然后將其解壓為 assign() 函數的參數 (colunmn_name=method, …)。
在這種特殊情況下,min-max 縮放不會改變對應的輸出:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.corr.html,它僅用于參數。
在(遙遠的?)未來,緩式評估(lazy evaluation)可能出現在方法鏈中,所以在鏈上做一些投資可能是一個好想法。
最后(隨機)的技巧
下面的提示很有用,但不適用于前面的任何部分:
itertuples() 可以更高效地遍歷數據框的行;
- >>> %%time
- >>> for row in df.iterrows(): continue
- CPU times: user 1.97 s, sys: 17.3 ms, total: 1.99 s
- >>> for tup in df.itertuples(): continue
- CPU times: user 55.9 ms, sys: 2.85 ms, total: 58.8 ms
注意:tup 是一個 namedtuple
join() 用了 merge();在 Jupyter 筆記本中,在代碼塊的開頭寫上 %%time,可以有效地測量時間;UInt8 類:https://pandas.pydata.org/pandas-docs/stable/user_guide/gotchas.html#support-for-integer-na支持帶有整數的 NaN 值;
記住,任何密集的 I/O(例如展開大型 CSV 存儲)用低級方法都會執行得更好(盡可能多地用 Python 的核心函數)。
還有一些本文沒有涉及到的有用的方法和數據結構,這些方法和數據結構都很值得花時間去理解:
- 數據透視表:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pivot.html?source=post_page
- 時間序列/日期功能:https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html?source=post_page;
- 繪圖:https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html?source=post_page。
總結
希望你可以因為這篇簡短的文章,更好地理解 Pandas 背后的工作原理,以及 Pandas 庫的發展現狀。本文還展示了不同的用于優化數據框內存以及快速分析數據的工具。希望對現在的你來說,索引和查找的概念能更加清晰。最后,你還可以試著用方法鏈寫更長的鏈。
這里還有一些筆記:https://github.com/unit8co/medium-pandas-wan?source=post_page
除了文中的所有代碼外,還包括簡單數據索引數據框(df)和多索引數據框(mi_df)性能的定時指標。
熟能生巧,所以繼續修煉技能,并幫助我們建立一個更好的世界吧。
PS:有時候純用 Numpy 會更快。
原文鏈接:
https://medium.com/unit8-machine-learning-publication/from-pandas-wan-to-pandas-master-4860cf0ce442
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】



















