深度解析 Flink 是如何管理好內存的?
前言
如今,許多用于分析大型數據集的開源系統都是用 Java 或者是基于 JVM 的編程語言實現的。最著名的例子是 Apache Hadoop,還有較新的框架,如 Apache Spark、Apache Drill、Apache Flink。基于 JVM 的數據分析引擎面臨的一個常見挑戰就是如何在內存中存儲大量的數據(包括緩存和高效處理)。合理的管理好 JVM 內存可以將 難以配置且不可預測的系統 與 少量配置且穩定運行的系統區分開來。
在這篇文章中,我們將討論 Apache Flink 如何管理內存,討論其自定義序列化與反序列化機制,以及它是如何操作二進制數據的。
數據對象直接放在堆內存中
在 JVM 中處理大量數據最直接的方式就是將這些數據做為對象存儲在堆內存中,然后直接在內存中操作這些數據,如果想進行排序則就是對對象列表進行排序。然而這種方法有一些明顯的缺點,首先,在頻繁的創建和銷毀大量對象的時候,監視和控制堆內存的使用并不是一件很簡單的事情。如果對象分配過多的話,那么會導致內存過度使用,從而觸發 OutOfMemoryError,導致 JVM 進程直接被殺死。另一個方面就是因為這些對象大都是生存在新生代,當 JVM 進行垃圾回收時,垃圾收集的開銷很容易達到 50% 甚至更多。最后就是 Java 對象具有一定的空間開銷(具體取決于 JVM 和平臺)。對于具有許多小對象的數據集,這可以顯著減少有效可用的內存量。如果你精通系統設計和系統調優,你可以根據系統進行特定的參數調整,可以或多或少的控制出現 OutOfMemoryError 的次數和避免堆內存的過多使用,但是這種設置和調優的作用有限,尤其是在數據量較大和執行環境發生變化的情況下。
Flink 是怎么做的?
Apache Flink 起源于一個研究項目,該項目旨在結合基于 MapReduce 的系統和并行數據庫系統的最佳技術。在此背景下,Flink 一直有自己的內存數據處理方法。Flink 將對象序列化為固定數量的預先分配的內存段,而不是直接把對象放在堆內存上。它的 DBMS 風格的排序和連接算法盡可能多地對這個二進制數據進行操作,以此將序列化和反序列化開銷降到最低。如果需要處理的數據多于可以保存在內存中的數據,Flink 的運算符會將部分數據溢出到磁盤。事實上,很多Flink 的內部實現看起來更像是 C / C ++,而不是普通的 Java。下圖概述了 Flink 如何在內存段中存儲序列化數據并在必要時溢出到磁盤:

Flink 的主動內存管理和操作二進制數據有幾個好處:
- 內存安全執行和高效的核外算法 由于分配的內存段的數量是固定的,因此監控剩余的內存資源是非常簡單的。在內存不足的情況下,處理操作符可以有效地將更大批的內存段寫入磁盤,后面再將它們讀回到內存。因此,OutOfMemoryError 就有效的防止了。
- 減少垃圾收集壓力 因為所有長生命周期的數據都是在 Flink 的管理內存中以二進制表示的,所以所有數據對象都是短暫的,甚至是可變的,并且可以重用。短生命周期的對象可以更有效地進行垃圾收集,這大大降低了垃圾收集的壓力。現在,預先分配的內存段是 JVM 堆上的長期存在的對象,為了降低垃圾收集的壓力,Flink 社區正在積極地將其分配到堆外內存。這種努力將使得 JVM 堆變得更小,垃圾收集所消耗的時間將更少。
- 節省空間的數據存儲 Java 對象具有存儲開銷,如果數據以二進制的形式存儲,則可以避免這種開銷。
- 高效的二進制操作和緩存敏感性 在給定合適的二進制表示的情況下,可以有效地比較和操作二進制數據。此外,二進制表示可以將相關值、哈希碼、鍵和指針等相鄰地存儲在內存中。這使得數據結構通常具有更高效的緩存訪問模式。
主動內存管理的這些特性在用于大規模數據分析的數據處理系統中是非常可取的,但是要實現這些功能的代價也是高昂的。要實現對二進制數據的自動內存管理和操作并非易事,使用 java.util.HashMap 比實現一個可溢出的 hash-table (由字節數組和自定義序列化支持)。當然,Apache Flink 并不是唯一一個基于 JVM 且對二進制數據進行操作的數據處理系統。例如 Apache Drill、Apache Ignite、Apache Geode 也有應用類似技術,最近 Apache Spark 也宣布將向這個方向演進。
下面我們將詳細討論 Flink 如何分配內存、如果對對象進行序列化和反序列化以及如果對二進制數據進行操作。我們還將通過一些性能表現數據來比較處理堆內存上的對象和對二進制數據的操作。
Flink 如何分配內存?
Flink TaskManager 是由幾個內部組件組成的:actor 系統(負責與 Flink master 協調)、IOManager(負責將數據溢出到磁盤并將其讀取回來)、MemoryManager(負責協調內存使用)。在本篇文章中,我們主要講解 MemoryManager。
MemoryManager 負責將 MemorySegments 分配、計算和分發給數據處理操作符,例如 sort 和 join 等操作符。MemorySegment 是 Flink 的內存分配單元,由常規 Java 字節數組支持(默認大小為 32 KB)。MemorySegment 通過使用 Java 的 unsafe 方法對其支持的字節數組提供非常有效的讀寫訪問。你可以將 MemorySegment 看作是 Java 的 NIO ByteBuffer 的定制版本。為了在更大的連續內存塊上操作多個 MemorySegment,Flink 使用了實現 Java 的 java.io.DataOutput 和 java.io.DataInput 接口的邏輯視圖。
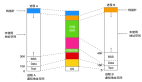
MemorySegments 在 TaskManager 啟動時分配一次,并在 TaskManager 關閉時銷毀。因此,在 TaskManager 的整個生命周期中,MemorySegment 是重用的,而不會被垃圾收集的。在初始化 TaskManager 的所有內部數據結構并且已啟動所有核心服務之后,MemoryManager 開始創建 MemorySegments。默認情況下,服務初始化后,70% 可用的 JVM 堆內存由 MemoryManager 分配(也可以配置全部)。剩余的 JVM 堆內存用于在任務處理期間實例化的對象,包括由用戶定義的函數創建的對象。下圖顯示了啟動后 TaskManager JVM 中的內存分布:

Flink 如何序列化對象?
Java 生態系統提供了幾個庫,可以將對象轉換為二進制表示形式并返回。常見的替代方案是標準 Java 序列化,Kryo,Apache Avro,Apache Thrift 或 Google 的 Protobuf。Flink 包含自己的自定義序列化框架,以便控制數據的二進制表示。這一點很重要,因為對二進制數據進行操作需要對序列化布局有準確的了解。此外,根據在二進制數據上執行的操作配置序列化布局可以顯著提升性能。Flink 的序列化機制利用了這一特性,即在執行程序之前,要序列化和反序列化的對象的類型是完全已知的。
Flink 程序可以處理表示為任意 Java 或 Scala 對象的數據。在優化程序之前,需要識別程序數據流的每個處理步驟中的數據類型。對于 Java 程序,Flink 提供了一個基于反射的類型提取組件,用于分析用戶定義函數的返回類型。Scala 程序可以在 Scala 編譯器的幫助下進行分析。Flink 使用 TypeInformation 表示每種數據類型。
- Flink 有如下幾種數據類型的 TypeInformations:
- BasicTypeInfo:所有 Java 的基礎類型或 java.lang.String
- BasicArrayTypeInfo:Java 基本類型構成的數組或 java.lang.String
- WritableTypeInfo:Hadoop 的 Writable 接口的任何實現
- TupleTypeInfo:任何 Flink tuple(Tuple1 到 Tuple25)。Flink tuples 是具有類型化字段的固定長度元組的 Java 表示
- CaseClassTypeInfo:任何 Scala CaseClass(包括 Scala tuples)
- PojoTypeInfo:任何 POJO(Java 或 Scala),即所有字段都是 public 的或通過 getter 和 setter 訪問的對象,遵循通用命名約定
- GenericTypeInfo:不能標識為其他類型的任何數據類型
每個 TypeInformation 都為它所代表的數據類型提供了一個序列化器。例如,BasicTypeInfo 返回一個序列化器,該序列化器寫入相應的基本類型;WritableTypeInfo 的序列化器將序列化和反序列化委托給實現 Hadoop 的 Writable 接口的對象的 write() 和 readFields() 方法;GenericTypeInfo 返回一個序列化器,該序列化器將序列化委托給 Kryo。對象將自動通過 Java 中高效的 Unsafe 方法來序列化到 Flink MemorySegments 支持的 DataOutput。對于可用作鍵的數據類型,例如哈希值,TypeInformation 提供了 TypeComparators,TypeComparators 比較和哈希對象,并且可以根據具體的數據類型有效的比較二進制并提取固定長度的二進制 key 前綴。
Tuple,Pojo 和 CaseClass 類型是復合類型,它們可能嵌套一個或者多個數據類型。因此,它們的序列化和比較也都比較復雜,一般將其成員數據類型的序列化和比較都交給各自的 Serializers(序列化器) 和 Comparators(比較器)。下圖說明了 Tuple3對象的序列化,其中Person 是 POJO 并定義如下:
- public class Person {
- public int id;
- public String name;
- }

通過提供定制的 TypeInformations、Serializers(序列化器) 和 Comparators(比較器),可以方便地擴展 Flink 的類型系統,從而提高序列化和比較自定義數據類型的性能。
Flink 如何對二進制數據進行操作?
與其他的數據處理框架的 API(包括 SQL)類似,Flink 的 API 也提供了對數據集進行分組、排序和連接等轉換操作。這些轉換操作的數據集可能非常大。關系數據庫系統具有非常高效的算法,比如 merge-sort、merge-join 和 hash-join。Flink 建立在這種技術的基礎上,但是主要分為使用自定義序列化和自定義比較器來處理任意對象。在下面文章中我們將通過 Flink 的內存排序算法示例演示 Flink 如何使用二進制數據進行操作。
Flink 為其數據處理操作符預先分配內存,初始化時,排序算法從 MemoryManager 請求內存預算,并接收一組相應的 MemorySegments。這些 MemorySegments 變成了緩沖區的內存池,緩沖區中收集要排序的數據。下圖說明了如何將數據對象序列化到排序緩沖區中:

排序緩沖區在內部分為兩個內存區域:第一個區域保存所有對象的完整二進制數據,第二個區域包含指向完整二進制對象數據的指針(取決于 key 的數據類型)。將對象添加到排序緩沖區時,它的二進制數據會追加到第一個區域,指針(可能還有一個 key)被追加到第二個區域。分離實際數據和指針以及固定長度的 key 有兩個目的:它可以有效的交換固定長度的 entries(key 和指針),還可以減少排序時需要移動的數據。如果排序的 key 是可變長度的數據類型(比如 String),則固定長度的排序 key 必須是前綴 key,比如字符串的前 n 個字符。請注意:并非所有數據類型都提供固定長度的前綴排序 key。將對象序列化到排序緩沖區時,兩個內存區域都使用內存池中的 MemorySegments 進行擴展。一旦內存池為空且不能再添加對象時,則排序緩沖區將會被完全填充并可以進行排序。Flink 的排序緩沖區提供了比較和交換元素的方法,這使得實際的排序算法是可插拔的。默認情況下, Flink 使用了 Quicksort(快速排序)實現,可以使用 HeapSort(堆排序)。下圖顯示了如何比較兩個對象:

排序緩沖區通過比較它們的二進制固定長度排序 key 來比較兩個元素。如果元素的完整 key(不是前綴 key) 或者二進制前綴 key 不相等,則代表比較成功。如果前綴 key 相等(或者排序 key 的數據類型不提供二進制前綴 key),則排序緩沖區遵循指向實際對象數據的指針,對兩個對象進行反序列化并比較對象。根據比較結果,排序算法決定是否交換比較的元素。排序緩沖區通過移動其固定長度 key 和指針來交換兩個元素,實際數據不會移動,排序算法完成后,排序緩沖區中的指針被正確排序。下圖演示了如何從排序緩沖區返回已排序的數據:

通過順序讀取排序緩沖區的指針區域,跳過排序 key 并按照實際數據的排序指針返回排序數據。此數據要么反序列化并作為對象返回,要么在外部合并排序的情況下復制二進制數據并將其寫入磁盤。
基準測試數據
那么,對二進制數據進行操作對性能意味著什么?我們將運行一個基準測試,對 1000 萬個Tuple2對象進行排序以找出答案。整數字段的值從均勻分布中采樣。String 字段值的長度為 12 個字符,并從長尾分布中進行采樣。輸入數據由返回可變對象的迭代器提供,即返回具有不同字段值的相同 Tuple 對象實例。Flink 在從內存,網絡或磁盤讀取數據時使用此技術,以避免不必要的對象實例化。基準測試在具有 900 MB 堆大小的 JVM 中運行,在堆上存儲和排序 1000 萬個 Tuple 對象并且不會導致觸發 OutOfMemoryError 大約需要這么大的內存。我們使用三種排序方法在Integer 字段和 String 字段上對 Tuple 對象進行排序:
- 對象存在堆中:Tuple 對象存儲在常用的 java.util.ArrayList 中,初始容量設置為 1000 萬,并使用 Java 中常用的集合排序進行排序。
- Flink 序列化:使用 Flink 的自定義序列化程序將 Tuple 字段序列化為 600 MB 大小的排序緩沖區,如上所述排序,最后再次反序列化。在 Integer 字段上進行排序時,完整的 Integer 用作排序 key,以便排序完全發生在二進制數據上(不需要對象的反序列化)。對于 String 字段的排序,使用 8 字節前綴 key,如果前綴 key 相等,則對 Tuple 對象進行反序列化。
- Kryo 序列化:使用 Kryo 序列化將 Tuple 字段序列化為 600 MB 大小的排序緩沖區,并在沒有二進制排序 key 的情況下進行排序。這意味著每次比較需要對兩個對象進行反序列化。
所有排序方法都使用單線程實現。結果的時間是十次運行結果的平均值。在每次運行之后,我們調用System.gc()請求垃圾收集運行,該運行不會進入測量的執行時間。下圖顯示了將輸入數據存儲在內存中,對其進行排序并將其作為對象讀回的時間。

我們看到 Flink 使用自己的序列化器對二進制數據進行排序明顯優于其他兩種方法。與存儲在堆內存上相比,我們看到將數據加載到內存中要快得多。因為我們實際上是在收集對象,沒有機會重用對象實例,但必須重新創建每個 Tuple。這比 Flink 的序列化器(或Kryo序列化)效率低。另一方面,與反序列化相比,從堆中讀取對象是無性能消耗的。在我們的基準測試中,對象克隆比序列化和反序列化組合更耗性能。查看排序時間,我們看到對二進制數據的排序也比 Java 的集合排序更快。使用沒有二進制排序 key 的 Kryo 序列化的數據排序比其他方法慢得多。這是因為反序列化帶來很大的開銷。在String 字段上對 Tuple 進行排序比在 Integer 字段上排序更快,因為長尾值分布顯著減少了成對比較的數量。為了更好地了解排序過程中發生的狀況,我們使用 VisualVM 監控執行的 JVM。以下截圖顯示了執行 10次 運行時的堆內存使用情況、垃圾收集情況和 CPU 使用情況。

測試是在 8 核機器上運行單線程,因此一個核心的完全利用僅對應 12.5% 的總體利用率。截圖顯示,對二進制數據進行操作可顯著減少垃圾回收活動。對于對象存在堆中,垃圾收集器在排序緩沖區被填滿時以非常短的時間間隔運行,并且即使對于單個處理線程也會導致大量 CPU 使用(排序本身不會觸發垃圾收集器)。JVM 垃圾收集多個并行線程,解釋了高CPU 總體利用率。另一方面,對序列化數據進行操作的方法很少觸發垃圾收集器并且 CPU 利用率低得多。實際上,如果使用 Flink 序列化的方式在 Integer 字段上對 Tuple 進行排序,則垃圾收集器根本不運行,因為對于成對比較,不需要反序列化任何對象。Kryo 序列化需要比較多的垃圾收集,因為它不使用二進制排序 key 并且每次排序都要反序列化兩個對象。
內存使用情況上圖顯示 Flink 序列化和 Kryo 序列化不斷的占用大量內存
存使用情況圖表顯示flink-serialized和kryo-serialized不斷占用大量內存。這是由于 MemorySegments 的預分配。實際內存使用率要低得多,因為排序緩沖區并未完全填充。下表顯示了每種方法的內存消耗。1000 萬條數據產生大約 280 MB 的二進制數據(對象數據、指針和排序 key),具體取決于使用的序列化程序以及二進制排序 key 的存在和大小。將其與數據存儲在堆上的方法進行比較,我們發現對二進制數據進行操作可以顯著提高內存效率。在我們的基準測試中,如果序列化為排序緩沖區而不是將其作為堆上的對象保存,則可以在內存中對兩倍以上的數據進行排序。

總而言之,測試驗證了文章前面說的對二進制數據進行操作的好處。
展望未來
Apache Flink 具有相當多的高級技術,可以通過有限的內存資源安全有效地處理大量數據。但是有幾點可以使 Flink 更有效率。Flink 社區正在努力將管理內存移動到堆外內存。這將允許更小的 JVM,更低的垃圾收集開銷,以及更容易的系統配置。使用 Flink 的 Table API,所有操作(如 aggregation 和 projection)的語義都是已知的(與黑盒用戶定義的函數相反)。因此,我們可以為直接對二進制數據進行操作的 Table API 操作生成代碼。進一步的改進包括序列化設計,這些設計針對應用于二進制數據的操作和針對序列化器和比較器的代碼生成而定制。
總結
- Flink 的主動內存管理減少了因觸發 OutOfMemoryErrors 而殺死 JVM 進程和垃圾收集開銷的問題。
- Flink 具有高效的數據序列化和反序列化機制,有助于對二進制數據進行操作,并使更多數據適合內存。
- Flink 的 DBMS 風格的運算符本身在二進制數據上運行,在必要時可以在內存中高性能地傳輸到磁盤。