10分鐘帶你打開深度學習大門,代碼已開源
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
深度學習技術的不斷普及,越來越多的語言可以用來進行深度學習項目的開發,即使是JavaScript這樣曾經只是在瀏覽器中運行的用于處理輕型任務的腳本語言。
TensorFlow.js是谷歌推出的基于JavaScript的深度學習框架,它提供的高級API使得開發可以直接在瀏覽器中運行的深度學習算法變得輕而易舉。
這不,美國的一位老哥Gant Laborde使用TensorFlow.js開發了一款是用深度學習技術在瀏覽器中識別“石頭剪刀布”游戲手勢的網頁應用,放出了demo并將代碼開源在了Github上。
對于JavaScript開發者來說,這是打開深度學習大門的極佳入門教材。只需10分鐘,你就可以訓練一個準確率可觀的手勢識別模型,并且調用攝像頭對實時視頻中的手勢進行識別。

△使用運行在瀏覽器中的深度學習模型識別手勢
在一切開始之前
在打開新世界的大門之前,我們總是需要做一些準備工作。
在這里,給大家簡單地介紹一下典型的深度學習算法的開發步驟,目的是希望讀者們在接下來的操作中明確地知道自己在做什么,而不僅僅是點幾個按鈕罷了。
這里不會涉及任何艱澀的數學公式,請放心食用。
我們平常所說的深度學習算法,更確切地說,應該是基于深度神經網絡的算法(或者說模型)。
這里并不需要知道深度神經網絡究竟是個什么東西(你可能需要再花百倍于此的時間才有可能搞明白其具體原理),只需要知道,它可以視作是一個函數f,一個很難用簡單公式表達出來的函數。
所謂函數,就要有自變量x和因變量y。
自變量x,我們一般稱之為輸入(input),在這個問題中就是一張做出“石頭”、“剪刀”或“布”手勢的手的圖像。
而因變量y,我們一般稱之為輸出(output),在這個問題中是三個取值為0-1的數值,分別對應輸入手勢是“石頭”、“剪刀”和“布”的概率。
我們依靠這個函數f得到我們想要的結果,但是f并不是天上掉下來的,它由人為選取的模型和(大量的)模型參數組成。
其中模型參數往往由大量數據學習得到,這個讓模型學習參數的過程我們稱之為模型訓練(train),是深度學習算法開發中最關鍵的一步。
在這個問題中,我們需要大量(x,y)數據對來進行訓練,也就是大量(圖像,手勢)數據對,如(圖像1,剪刀)、(圖像2、石頭)、(圖像3、布)…… 這些數據對往往需要由人為搜集、標注得到。
我們可以通過一些評估指標來衡量模型的好壞程度,比如在這個問題中,手勢識別的準確度。通過這些評估指標我們可以驗證(validate)模型是否經過了充分的訓練、效果有沒有達到我們的預期。如果是,我們可以將其部署投入使用,測試其在現實情況中的表現。
總結來說,一個深度學習算法的開發,需要經過數據準備、模型選擇與訓練、模型效果評估、模型測試這四個階段。
現在,正式開始!
數據準備
我們之前提到,需要大量的(圖像,手勢)數據對來進行模型的訓練。搜集這樣的數據無疑是一個繁瑣的工作,拍照、標注……
幸運的是,谷歌工程師Laurence Moroney為我們提供了這樣一個數據集,其中包含了白色背景下的三種手勢共2892張圖像及對應的手勢標簽,一些例子:
△Moroney提供的數據集的一些例子
數據集網址:
http://www.laurencemoroney.com/rock-paper-scissors-dataset/
一切看似都是這么的順利。等等,我們怎么把這么一坨圖像搞進瀏覽器里去?
在瀏覽器里執行JavaScript,好像并不能從本地讀取文件。
一個顯見的想法是,我們把訓練數據當做網頁中的圖片,讀進DOM的img元素中。我們先將訓練數據中每一張圖像“拉直“成1像素高的圖像,再將所有圖像一行一行堆疊在一起。
比如我們原圖大小為64x64,“拉直”之后尺寸為1x4096,訓練集的2520張圖像堆疊后形成大小為4096x2520的巨大圖像(雖然它在視覺上已經失去了意義),像下面這樣。
這張巨大圖像被稱為精靈表單(sprite-sheet),包含了許多小圖像。
這個網頁應用的作者提供了生成sprite-sheet的Python代碼,在github倉庫根目錄的spritemaker文件夾下。
△生成的尺寸為4096x2520的sprite-sheet
在demo頁面中,點擊“Load and Show Examples(讀取數據并展示樣例)”按鈕,等待一陣,我們可以看到數據被讀入了瀏覽器,并且出現了一個側邊欄,其中展示了42張從數據集中隨機選取的圖像。
這個側邊欄由TensorFlow Visor提供,可以幫助我們直觀地觀察模型的訓練過程,我們可以隨時按下鍵盤左上方的`鍵切出或隱藏該面板。
△TensorFlow Visor界面中展示的數據樣例
模型選擇、訓練與效果評估
接下來我們將面臨抉擇。
兩個按鈕擺在我們的面前,“Create Simple Model(創建簡單模型)”和“Create Advance Model(創建高級模型)”。

先從簡單的來吧,我們點擊“Create Simple Model”。按`鍵切出TensorFlow Visor面板,可以看到上面出現了剛剛創建的簡單模型的網絡結構,這是一個5層的卷積神經網絡模型(Flatten層不計入層數),你只需要知道它可以看做是一個一個相對簡單函數的堆疊,并且這確實是一個非常簡單基礎的卷積神經網絡模型。

△TensorFlow Visor界面中展示的網絡結構
點擊“Check Untrained Model Results(查看未訓練模型結果)”,面板中出現了一個Accuracy(準確率)表格,和一個矩陣,它們就是這個問題中我們對于模型的評價指標。
準確率表格中,每一行是一個手勢類別的準確率值;矩陣中,手勢X的行和手勢Y的列確定的單元格代表實際是手勢X,被算法認為是手勢Y的圖像數量,這樣的矩陣我們叫做“混淆矩陣”,因為它展現了算法對于兩兩手勢容易搞混的程度。
可以看到,因為我們的模型還沒有進行訓練,所以算法認為所有輸入圖像中的手勢都是“剪刀”,它還很懵懂。
那么就開始訓練它吧!點擊“Train Your Simple Model(訓練簡單模型)”!TensorFlow Visor面板中出現了“Model Training(模型訓練)”一欄,展示了訓練中實時的準確率(Accuracy)和損失(Loss)值,正常情況下,我們應該可以看到隨著訓練的進行,準確率不斷上升,而損失不斷下降。訓練在12個epoch(60個batch)后停止。
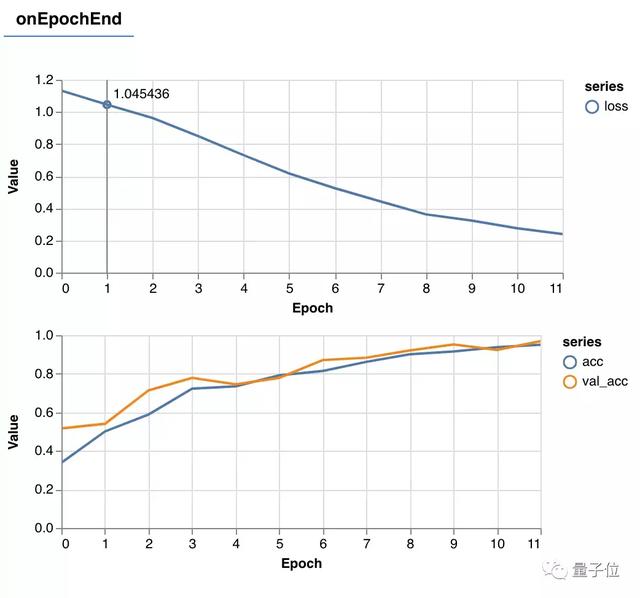
△TensorFlow Visor界面中展示的訓練進程
訓練結束后,點擊“Check Model After Training(查看訓練后模型結果)”。在原來的準確率表格和混淆矩陣下方出現了訓練后模型的準確率(Trained Accuracy)和混淆矩陣(Trained Confusion Matrix)。
Amazing!訓練后,模型在驗證數據上對于三種手勢的識別準確率都超過了95%,混淆矩陣也是健康的(對角線深,其余淺)。
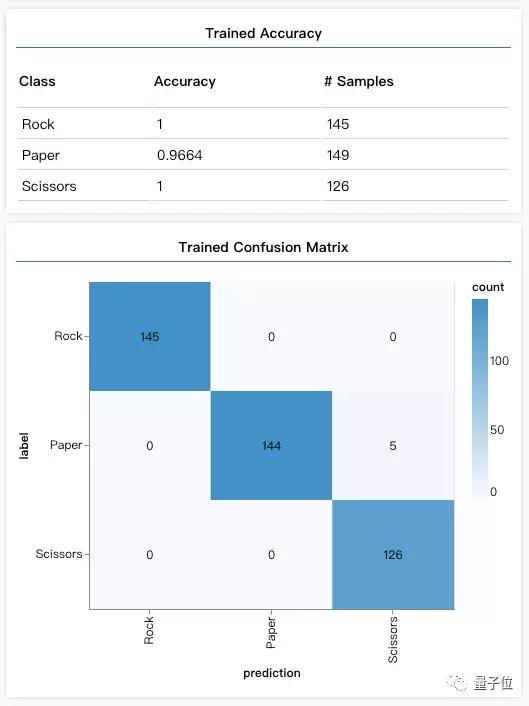
△TensorFlow Visor界面中展示的訓練后模型效果
你也許會想,“高級的東西總比簡單的東西好吧?高級模型效果一定更好。” 其實這是一個常見的誤區。
如果你選擇“Create Advance Model(創建高級模型)”,重復上述操作,會發現高級模型不僅訓練時間更長,效果也不如簡單模型那么好。
更進一步,高級模型如果訓練時間過長,會出現過擬合(overfitting)的情況。
過擬合是指,模型太注重完美擬合訓練數據,導致其雖然在訓練數據上的表現極佳,但是對于訓練數據之外它沒有見過的數據效果較差,或者我們也會說模型此時的泛化(generalize)能力較差。
模型測試
既然已經有了一個表現很不錯的簡單模型,那么讓我們立刻將它投入使用吧!
點擊“Launch Webcam(打開攝像頭)”,對準一面白墻,對著攝像頭做出不同的手勢,應用會定時捕捉視頻圖像,通過訓練好的模型算法,告訴你當前手勢屬于三種類別的概率,是不是很酷炫呢?
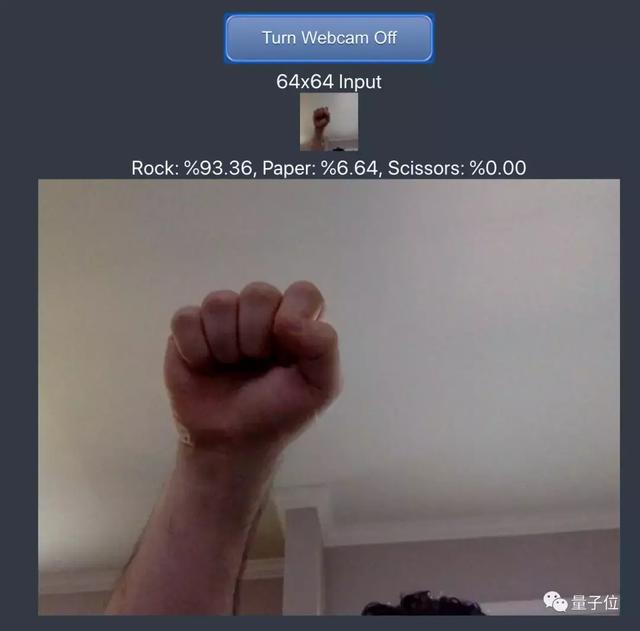
△使用已訓練模型識別視頻中的手勢
Done!
至此,你已經在完全在瀏覽器中訓練了一個用于手勢分類的深度學習模型,通過一些指標驗證了它的有效性,并且在現實情境中對它進行了測試。
盡管這些步驟很簡單,但你了解它們在做什么——歡迎來到深度學習的世界!
傳送門
源代碼倉庫:
https://github.com/GantMan/rps_tfjs_demo
Demo頁面:
https://rps-tfjs.netlify.com/