技術干貨總結:分布式系統常見同步機制
分布式系統為保證數據高可用,需要為數據保存多個副本,隨之而來的問題是如何在不同副本間同步數據?不同的同步機制有不同的效果和代價,本文嘗試對常見分布式組件的同步機制做一個小結。
常見機制
有一些常用的同步機制,對它們也有許多評價的維度,先看看大神的 經典總結 :
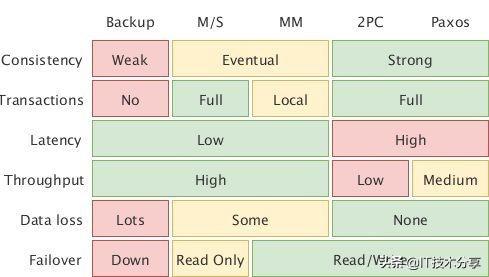
上圖給出了常用的同步方式(個人理解,請批評指正):
- Backup,即定期備份,對現有的系統的性能基本沒有影響,但節點宕機時只能勉強恢復
- Master-Slave,主從復制,異步復制每個指令,可以看作是粒度更細的定期備份
- Multi-Muster,多主,也稱“主主”,MS 的加強版,可以在多個節點上寫,事后再想辦法同步
- 2 Phase-Commit,二階段提交,同步先確保通知到所有節點再寫入,性能容易卡在“主”節點上
- Paxos,類似 2PC,同一時刻有多個節點可以寫入,也只需要通知到大多數節點,有更高的吞吐
同步方式分兩類,異步的性能好但可能有數據丟失,同步的能保證不丟數據但性能較差。同種方式的算法也能有所提升(如 Paxos 對于 2PC),但實現的難度又很高。實現上只能在這幾點上進行權衡。
考慮同步算法時,需要考慮節點宕機、網絡阻斷等故障情形。下面,我們來看看一些分布式組件的數據同步機制,主要考慮數據寫入請求如何被處理,期間可能會涉及如何讀數據。
Redis
Redis 3.0 開始引入 Redis Cluster 支持集群模式,個人認為它的設計很漂亮,大家可以看看 官方文檔 。
- 采用的是主從復制,異步同步消息,極端情況會丟數據
- 只能從主節點讀寫數據,從節點只會拒絕并讓客戶端重定向,不會轉發請求
- 如果主節點宕機一段時間,從節點中會自動選主
- 如果期間有數據不一致,以最新選出的主節點的數據為準。
一些設計細節:
- HASH_SLOT = CRC16(Key) mod 16384
- MEET
- WAIT
Kafka
Kafka 的分片粒度是 Partition,每個 Partition 可以有多個副本。副本同步設計參考 官方文檔
- 類似于 2PC,節點分主從,同步更新消息,除非節點全掛,否則不會丟消息
- 消息發到主節點,主節點寫入后等待“所有”從節點拉取該消息,之后通知客戶端寫入完成
- “所有”節點指的是 In-Sync Replica(ISR),響應太慢或宕機的從節點會被踢除
- 主節點宕機后,從節點選舉成為新的主節點,繼續提供服務
- 主節點宕機時正在提交的修改沒有做保證(消息可能沒有 ACK 卻提交了)
一些設計細節:
- 當前消費者只能從主節點讀取數據,未來可能會改變
- 主從的粒度是 partition,每個 broker 對于某些 Partition 而言是主節點,對于另一些而言是從節點
- Partition 創建時,Kafka 會盡量讓 preferred replica 均勻分布在各個 broker
- 選主由一個 controller 跟 zookeeper 交互后“內定”,再通過 RPC 通知具體的主節點 ,此舉能防止 partition 過多,同時選主導致 zk 過載。
ElasticSearch
ElasticSearch 對數據的存儲需求和 Kafka 很類似,設計也很類似,詳細可見 官方文檔 。
ES 中有 master node 的概念,它實際的作用是對集群狀態進行管理,跟數據的請求無關。為了上下文一致性,我們稱它為管理節點,而稱 primary shard 為“主節點”, 稱 replica shard 為從節點。ES 的設計:
- 類似于 2PC,節點分主從,同步更新消息,除非節點全掛,否則不會丟消息
- 消息發到主節點,主節點寫入成功后并行發給從節點,等到從節點全部寫入成功,通知客戶端寫入完成
- 管理節點會維護每個分片需要寫入的從節點列表,稱為 in-sync copies
- 主節點宕機后,從節點選舉成為新的主節點,繼續提供服務
- 提交階段從節點不可用的話,主節點會要求管理節點將從節點從 in-sync copies 中移除
一些設計細節:
- 寫入只能通過只主節點進行,讀取可以從任意從節點進行
- 每個節點均可提供服務,它們會轉發請求到數據分片所在的節點,但建議循環訪問各個節點以平衡負載
- 數據做分片: shard = hash(routing) % number_of_primary_shards
- primary shard 的數量是需要在創建 index 的時候就確定好的
- 主從的粒度是 shard,每個節點對于某些 shard 而言是主節點,對于另一些而言是從節點
- 選主算法使用了 ES 自己的 Zen Discovery
Hadoop
Hadoop 使用的是鏈式復制,參考 Replication Pipelining
- 數據的多個復本寫入多個 datanode,只要有一個存活數據就不會丟失
- 數據拆分成多個 block,每個 block 由 namenode 決定數據寫入哪幾個 datanode
- 鏈式復制要求數據發往一個節點,該節點發往下一節點,待下個節點返回及本地寫入成 功后返回,以此類推形成一條寫入鏈。
- 寫入過程中的宕機節點會被移除 pineline,不一致的數據之后由 namenode 處理。
實現細節:
- 實現中優化了鏈式復制:block 拆分成多個 packet,節點 1 收到 packet, 寫入本地 的同時發往節點 2,等待節點 2 完成及本地完成后返回 ACK。節點 2 以此類推將 packet 寫入本地及發往節點 3……
TiKV
TiKV 使用的是 Raft 協議來實現寫入數據時的一致性。參考 三篇文章了解 TiDB 技術內幕——說存儲
- 使用 Raft,寫入時需要半數以上的節點寫入成功才返回,宕機節點不超過半數則數據不丟失。
- TiKV 將數據的 key 按 range 分成 region,寫入時以 region 為粒度進行同步。
- 寫入和讀取都通過 leader 進行。每個 region 形成自己的 raft group,有自己的 leader。
Zookeeper
Zookeeper 使用的是 Zookeeper 自己的 Zab 算法(Paxos 的變種?),參考 Zookeeper Internals
- 數據只可以通過主節點寫入(請求會被轉發到主節點進行),可以通過任意節點讀取
- 主節點寫入數據后會廣播給所有節點,超過半數節點寫入后返回客戶端
- Zookeeper 不保證數據讀取為最新,但通過“單一視圖”保證讀取的數據版本不“回退”
小結
如果系統對性能要求高以至于能容忍數據的丟失(Redis),則顯然異步的同步方式是一種好的選擇。
而當系統要保證不丟數據,則幾乎只能使用同步復制的機制,看到 Kafka 和 Elasticsearch 不約而同地使用了 PacificA 算法(個人認為可以看成是 2PC 的變種),當然這種方法的響應制約于最慢的副本,因此 Kafka 和 Elasticsearch 都有相關的機制將慢的副本移除。
當然看起來 Paxos, Raft, Zab 等新的算法比起 2PC 還是要好的:一致性保證更強,只要半數節點寫入成功就可以返回,Paxos 還支持多點寫入。只不過這些算法也很難正確實現和優化。