異構數據半小時實現搜索功能,一個系統搞定
背景
對于閑魚這種處于高速增長期的部門來說,業務場景在快速膨脹,越來越多的業務數據對搜索能力有訴求。如果按照常規的方式為各個業務搭建獨立搜索引擎服務,那么開發和維護的時間成本將是非常巨大的。能否只用一套搜索引擎系統支撐不同業務場景產出的數據呢?不同場景的異構數據如何在一套引擎中兼容呢?閑魚從實際的業務需求出發,搭建了一套通用搜索系統解決這個問題。
搜索原理簡述
閑魚使用的搜索引擎是阿里巴巴的HA3引擎,配合其上層的管控系統Tisplus2使用。可以拆分為以下幾個子系統:
1、dump:接入搜索系統首先要做的就是把DB數據經過一些業務邏輯轉換后(后面會詳細描述的merge、join流程),按照引擎BuildService能夠識別的文件格式寫入到文件系統或者消息隊列中供BS構建索引使用,這個過程分為全量與增量兩種。
2、BuildService(簡稱BS):將dump產出的數據構建成索引文件。Searcher機器加載了BS產出的索引文件后才能提供倒排、正排、summary的查詢服務。
3、搜索業務網關:業務層封裝統一服務接口,對業務接入方屏蔽搜索系統底層細節。
4、Search Planner(簡稱SP):組合搜索中臺多種能力,調用算法服務對網關傳入的查詢串進行改寫、類目預測、算分,實現多路召回、分層查詢、翻頁去重等功能,對QRS返回的結果進行包裝返回。
5、引擎在線服務:分為QRS與Searcher兩種角色。SP的查詢請求發送給QRS,QRS將請求轉發到多臺searcher機器上然后收集searcher返回的結果進行合并、算分、排序、返回。
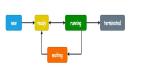
整個搜索系統的簡化版結構圖如下:
為每個業務場景從頭搭建一套搜索系統是有一定復雜度的,而且需要花費較多時間。我們希望提供一套通用搜索系統,當新的業務數據接入搜索能力時,不需要業務開發同學精通搜索系統原理,只要在我們的系統中注冊哪些數據需要被搜索,就可以完成搜索能力的自主接入,幾乎無需開發,真正實現十分鐘快速接入搜索。多個業務的數據共存在一套搜索引擎服務中,各業務數據相互隔離互不影響。
這里涉及到兩個問題:
①如何把異構數據從不同的業務db寫入同一個引擎構建索引,且寫入過程完全自動化、透明化,無需業務接入方參與開發;
②如何實現不同業務場景的開發同學在使用搜索召回的過程中不感知到其他業務數據的存在,就像在使用一套為他的業務單獨搭建的引擎服務一樣方便。
我們的解法
針對上面遇到的2個問題,我們的解決思路是提前構建一套通用搜索系統,把dump、bs、search、Search Planner、網關層的基本能力都提前實現,業務在調用服務時通過設定可選的入參來選擇自己需要的能力(比如關鍵詞改寫、類目預測、pvlog打印、分層召回等)。通過一個中間層把dump流程自動化,并對dump、search過程進行字段翻譯、結果包裝。
搜索引擎基本服務的搭建過程與常規方式無大的差異,這里不詳細描述。接下來我詳細介紹一下此方案實施過程中拆分出的4個技術要點:①通用搜索預留表;②元數據注冊中心;③兩層dump;④在線查詢服務。
1、通用搜索預留表
常規情況下,我們會把dump產出的大寬表字段命名為itemId、title、price、userId等具有明確語義的字段名。但是如果要實現多場景共用一套引擎就不能這么做了,因為并不是所有場景數據都有itemId、title、price字段,也可能某個場景中需要接入color字段但是我們的引擎中沒有定義這個字段,導致無法支持這個業務場景。
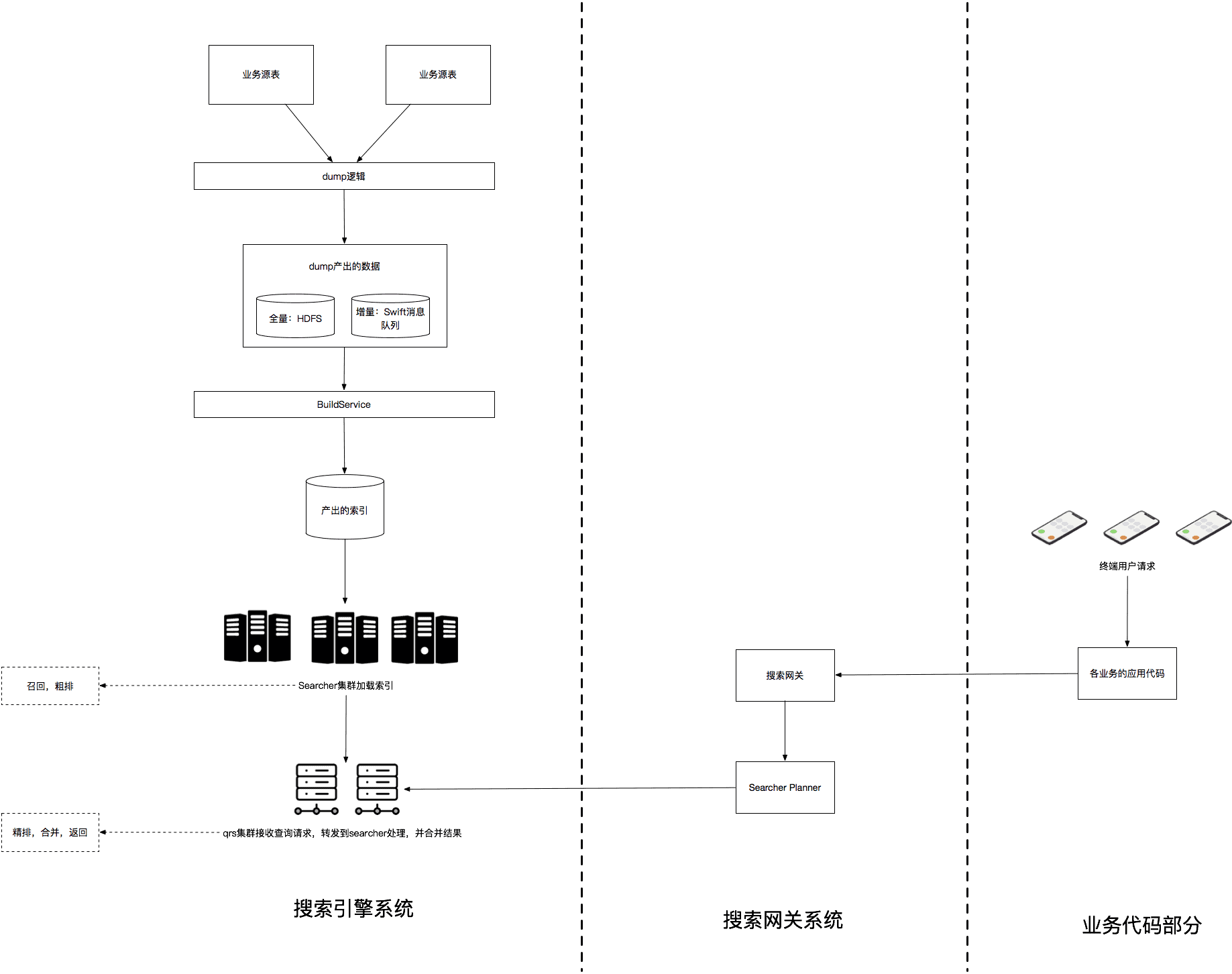
既然問題的關鍵是字段定義有語義,那么我們解決這個問題的思路就是讓已引擎中的所有字段都完全無語義,只有類型信息。我們按照下圖的方式預定義2個維度,每個維度下各2張Mysql表和2張ODPS表(這種定義已經可以覆蓋絕大多數場景了),稱為通用搜索預留表。
為每張預留表預留各種類型的字段,按照所處維度、表在維度內位置、字段類型進行字段命名:
1)將第一個維度中第一張預留表表的字段命名為dima_pk、dima_a_int_r1、dima_a_text_multilevel_r1、dima_dimb_joinkey等;
2)將第一個維度中第二張預留表表命名為dima_b_inner_mergekey、dima_b_int_r1、dima_b_int_r2、dima_b_long_r1等;
3)將第二個維度中第一張預留表表字段命名為dimb_pk、dimb_a_int_r1等;
4)將第二個維度中第二張預留表表命名為dimb_b_inner_mergekey、dimb_b_int_r1、dimb_b_long_r1等;
然后將預留表按照上圖的結構,與引擎原生的dump系統進行對接,并配置索引構建信息。當這套引擎服務搭建完成后,如果直接往通用搜索預留表中接入幾條數據,就已經可以從引擎在線查詢接口中查到數據了。不過這套搜索系統對業務開發同學來說是不可用的,因為業務源表結果與我們的預留表結構完全不同,業務同學很難把數據從源表按照我們預定義的格式全部遷移到通用搜索預留表,且查詢時用“dima_a_text_multilevel_r1='iPhone6S'”這種無語義的方式做查詢也是業務同學無法接受的。接下來我們就來解決這些問題。
2、元數據注冊中心
我們設計了一個元數據注冊中心,當一個新業務需要接入搜索能力時,只需要在注冊中心填寫業務相關注冊信息(包括業務場景標簽,需要接入搜索能力的數據庫、表名、字段等基本信息),系統會分配一個業務唯一識別碼,這個識別碼會作為dump、bs、查詢流程中實現多業務隔離的最重要標識。
元數據注冊表結構:

元數據注冊中心以WEB界面形式提供新業務注冊的能力,用戶在填寫業務的庫名,會通過中間件自動拉取到包含的所有表名。用戶從中選擇自己需要接入的表名,界面上列出此表下的全部字段,以及系統預設的全部通用搜索預留表字段。用戶在源表字段與預留表字段之間用鼠標建立連線,完成后點擊提交,系統將對用戶建立的映射關系進行各項合法性檢查,檢查通過后按照上面的元數據注冊表結構寫入DB。這份注冊數據以后將在dump、查詢等多個環節用到。
3、兩層dump
每一張業務源表的語義一般比較單一,多張表組合在一起才能夠形成一個業務場景的全貌。比如:
1)商品基本信息表中會存儲商品id、標題、描述、圖片、賣家id等信息;
2)商品擴展信息表中會以商品id為主鍵,存儲商品擴展信息,如sku信息、擴展標簽信息等;
3)賣家基本信息表中會以用戶id為主鍵,存儲用戶的昵稱、頭像等基本信息;
4)賣家信用信息表中會以用戶id為主鍵,存儲用戶的芝麻信用等級。
在一次典型的搜索請求場景中,用戶以“iPhone6S”進行搜索,在搜索結果中用戶除了希望看到商品基本信息如標題、描述、圖片等,還希望看到存儲在擴展表中的sku、擴展標簽等擴展信息,以及賣家的昵稱、頭像、信用等級等用戶維度信息。如何實現在一次召回過程把分散存儲在多張表中的與同一個商品相關的信息都返回呢?這就需要在dump過程中把多表數據按照一定的方式組織起來,拼裝成最終希望的寬表格式,再寫入持久化存儲供引擎構建索引。
我們在dump過程中,把與此業務場景相關的多張表按照主鍵做merge和join。同一維度內的多張表按照主鍵拼成大寬表的過程成為merge,比如1)和2)之間就是按照商品id做merge,結果記為M1;3)和4)之間就是按照用戶id做merge,結果記為M2。結果M1中有一列數據是賣家的用戶id,而M2的主鍵就是用戶id,將M1和M2根據用戶id做join,就得到了最終的大寬表,寬表中的任何一條數據都包含了1)2)3)4)中的完整場景信息。
在通用搜索預留表構建過程中,我們已經按照dima_pk+ima_b_inner_mergekey和dimb_pk+dimb_b_inner_mergekey的方式做維度內merge,按照dima_pk+dimb_pk的方式做維度間join的方式完成了預留表與BuilderService的對接。只要業務同學把源表數據正確遷移到預留表中,就可以實現上面描述的復雜dump流程。數據遷移既要保證源表的全部數據被遷移,也要保證線上實時增量數據被遷移,而且遷移過程中需要根據元數據注冊中心的字段映射信息進行轉換,這個流程還是比較復雜的,如何自動化實現這部分工作呢?
我們的實現方式是基于阿里巴巴內部的中間件平臺“精衛”做二次開發,編寫自主消費tar包上傳到精衛平臺運行,根據各業務的注冊信息完成適用于各業務的遷移任務,這部分工作由我們在開發通用搜索系統時完成,對各業務接入同學完全透明。
精衛平臺支持全量遷移任務和增量遷移任務,簡單的理解全量遷移任務就是循環對源表執行“select * from table_xxx where id>m and id比如一個業務開發同學需要為小區POI數據接入搜索能力,他在注冊中心注冊這個業務,在mapping_info中聲明需要把源表的poi_id映射為dima_pk,把源表的poi_name映射為dima_a_text_r1,環境為預發環境。配置完成后,系統會自動分配一個biz_code如1001。當精衛任務啟動時,我們上傳到精衛的自主消費代碼會把從源表拿到的poi_id為123123123的數據轉換為主鍵為“1001_0_123123123”的數據寫入通用搜索預留表,其中1001代表業務唯一識別碼,0代表預發環境,123123123代表原始業務主鍵。
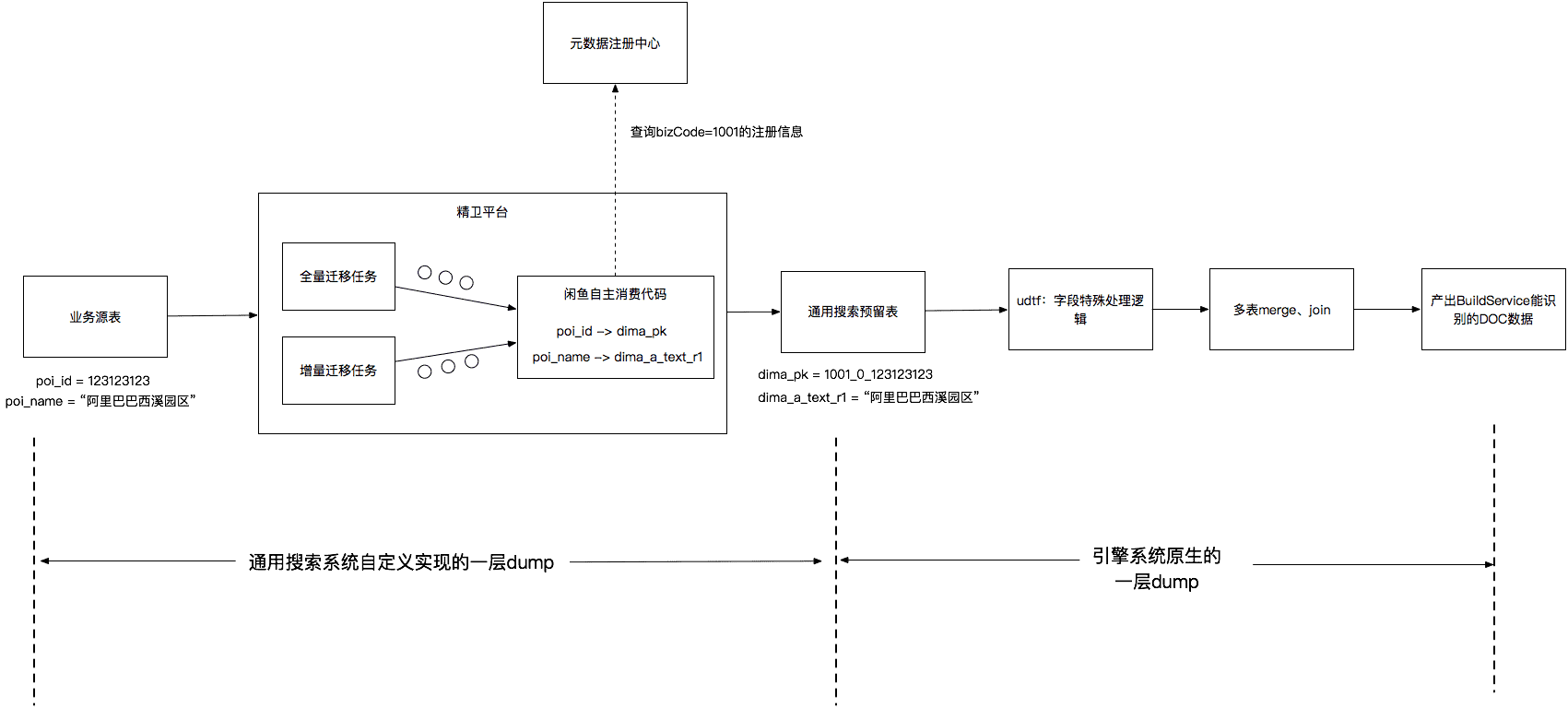
如此一來就實現了用戶只需一次填寫,就自動化完成數據dump的工作。
4、在線查詢服務
既然dump產出數據的字段是無語義的,那么相應的BuildService構建處端索引數據各字段也是無語義的。
這里看起來通過無語義的定義方式支持了將多場景異構數據寫入同一個引擎服務,但是對業務開發同學來說太不友好了。他們在業務開發中調用搜索服務時,期望的方式是自然的業務語義調用,如下面的代碼片段:
- param.setTitle("iPhone6S");
- param.setSellerId(1234567L);
- result = searchService.doSearch(param);
但是現在字段沒了語義,他們開發的復雜度大大提升,甚至時間一長會陷入難以維護的境地,因為業務代碼寫完1個月后沒人會再記得代碼中的“param.setDimaALongR1(1234567L)”是什么意思,這是按照用戶id還是商品id查詢?
雖然底層我們是將多個業務的數據放在一個引擎服務中,但是我們希望提供給業務開發同學(也就是我們這套系統的用戶)的在線查詢服務與獨立搭建一套引擎的體驗是一樣的。所以,這里就需要有一個翻譯層,通用搜索系統接收到的查詢請求是“title=iPhone6S”,我們需要根據元數據注冊中心的映射關系自動翻譯成“dima_a_text_multilevel_r1=iPhone6S”后再向引擎發起搜索請求,并把引擎返回的數據DO中無語義字段翻譯成源表的有語義字段。
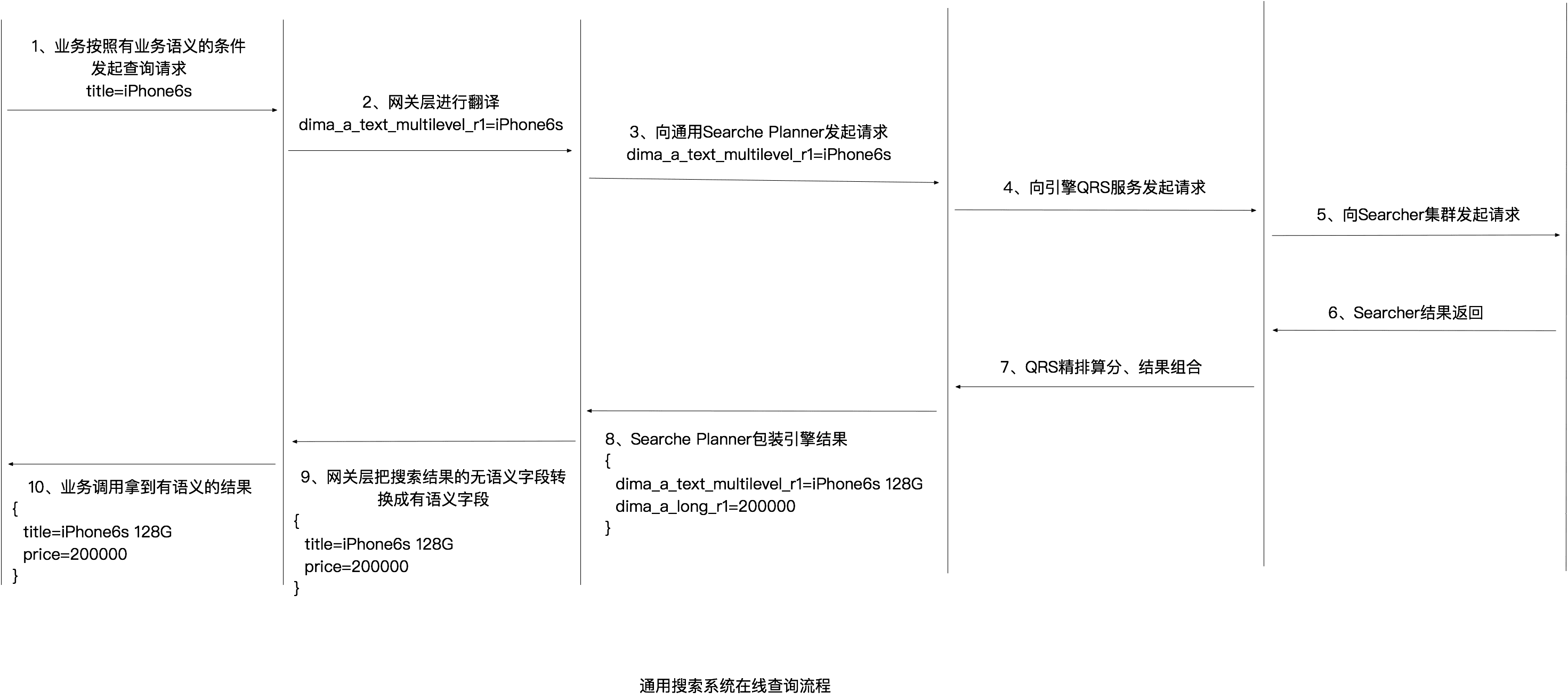
可以看到,通過我們提供的搜索網關二方包,業務同學可以按照有語義的方式設置查詢條件“param.setTitle("iPhone6S")”,同時自動化把引擎返回的無語義字段進行包裝成為有語義的字段。業務同學完全覺察不到中間的轉換過程,對他來說就像在使用一個為他單獨搭建的搜索引擎服務一樣。
每個業務接入方的源表字段定義都不同,只寫一套搜索網關代碼肯定無法實現上面的能力。我們的方案是,當用戶在元數據注冊中心曾經接入一個新業務后,后臺自動化生成生成為業務定制的二方包代碼,其中包含了查詢入參、返回DO、查詢服務接口。
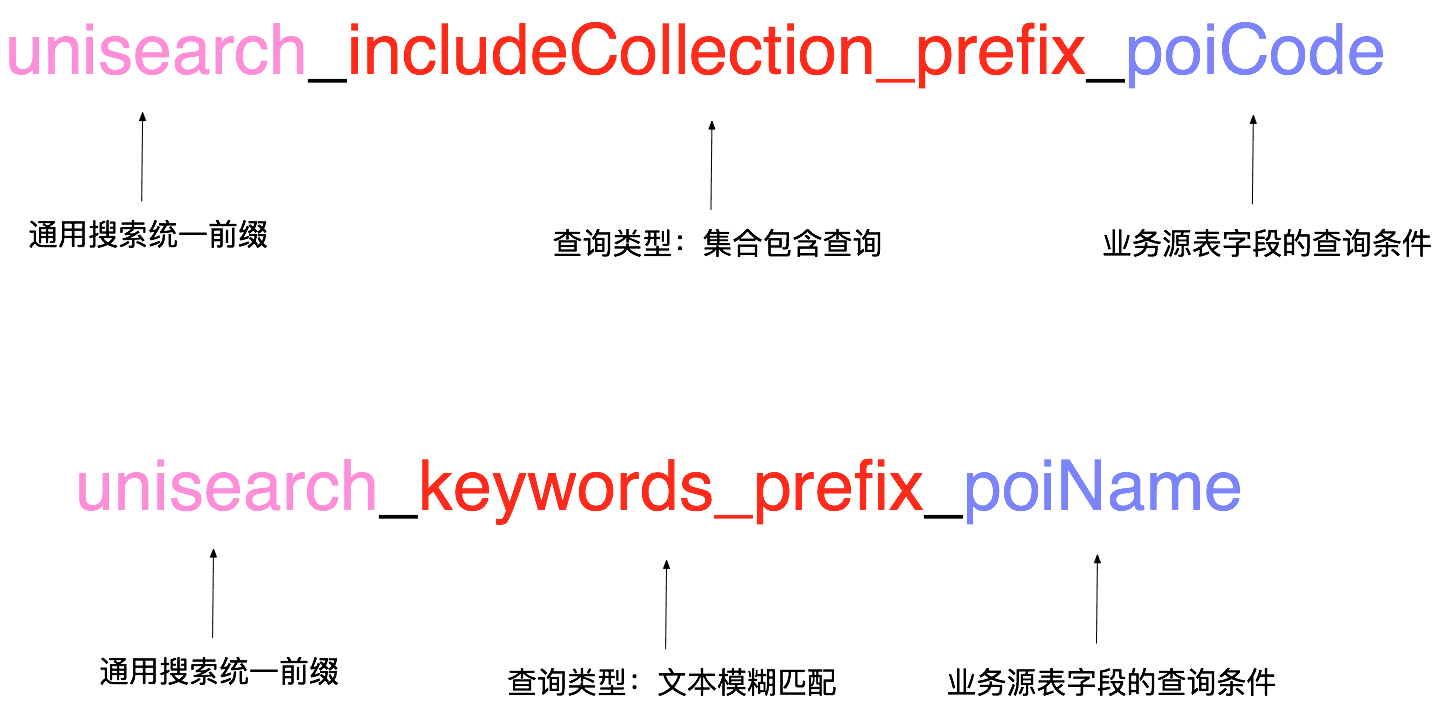
還是以poi數據接入為例,poi業務域的開發同學在元數據注冊中心說明了他需要按照poi_name做文本模糊匹配,需要根據poi_code做包含查詢、不包含的精確查詢。根據此登記信息,我們為用戶自動生成poi業務場景專用的查詢服務入參,每個入參都是一定的規則拼接而成,網關在線服務拿到此參數后可以根據命名規則翻譯成具體的查詢串。參數命名規則如下圖:
入參Demo代碼如下:
- public class UnisearchBiz1001SearchParam extends IdleUnisearchBaseSearchParams {
- private Set<Long> unisearch_includeCollection_prefix_poiCode;
- private Set<Long> unisearch_excludeCollection_prefix_poiCode;
- private String unisearch_keywords_poiName;
- }
用戶通過在線查詢服務把此查詢條件傳入時,查詢服務檢測到入參是IdleUnisearchBaseSearchParams的之類,會根據命名規則使用反射機制判定unisearch_includeCollection_prefix_poiCode是需要對業務源表的poiCode字段做include(包含)查詢,然后從元數據注冊中心的映射關系數據取出poiCode對應的預留表字段名為dima_a_long_r1,構造Search Planner查詢串,執行后續查詢動作。
當引擎返回查詢結果后,網關查詢服務再次根據元數據注冊信息,利用反射對引擎結果DO進行翻譯轉換,包裝成下面所示的poi業務專用DO后返回給業務開發同學。
- public class UnisearchBiz1001SearchResultDo extends IdleUnisearchBaseSearchResultDo {
- private Long poiId;
- private Long poiCode;
- private String poiName;
- }
通用搜索預留表一共有8張,全部字段加起來是比較多的。如果把字段全部召回,實際上大部分字段都是業務沒有進行注冊的空字段,返回數據會比實際需要的數據大小膨脹幾十倍,網絡傳輸開銷、大量空字段反序列化開銷、DO字段轉換開銷會導致在線查詢服務的RT很高。解決此問題比較簡單,我們把整個在線召回流程定義為兩個階段,第一個階段只根據用戶的查詢條件在引擎中召回符合要求的數據主鍵rawpk;第二階段根據此rawpk列表去獲取對應數據的summary(即所有字段的信息)時,利用引擎支持的dl語法,要求二階段僅返回用戶注冊過的預留字段即可。當然,這些工作也由我們在通用搜索系統的網關代碼中提前實現了,對各業務接入同學透明。
增量問題的特殊解法
到現在為止一切看起來都很完美,貌似我們已經用這套系統完美解決了數據導入、轉換、bs、查詢等一系列工作的自動化包裝,業務同學需要做的僅僅是來我們的業務注冊中心界面上登記一下而已。不過實際上在表面之下還隱藏著一個較嚴峻的問題,就是大增量的問題。
由于與BuildeService直接對接的是結構已經固定的通用搜索預留表,也就意味著原生的dump層數據源結構是不可能變化的,唯一能變化的是從業務源表經過精衛系統寫入通用搜索預留表的數據。當上游有一個新業務接入進來時,如果它的源表數據量達到了十億級別,按照目前精衛能夠達到的遷移速度,也就意味著通用搜索預留表的更新TPS能夠達到5萬的級別,而這每秒5萬條數據更新的壓力就會直接打在實時BS系統上,即引擎需要每秒更新5萬條doc數據才能保證搜索結果與源表數據的一致性。而搜索引擎的實時BS能力依賴于實時內存的容量,這么大的增量TPS會在短時間內打滿實時內存,導致源表后續的更新數據無法實時被BS構建成索引,那么搜索系統就無法搜索到新的業務數據(包括新增、更新、刪除的數據),稱為增量延遲問題。
多個業務共享這套引擎服務,線上已經在提供搜索服務的業務無法接受增量延遲;而對本次新接入的業務來說,在第一次接入時把數據往通用預留表同步的這段時間內,數據搜索不到是完全可以接受的。因此,我們想出一個辦法實現了線上存量業務的增量數據正常實時進引擎,而新業務的全量遷移數據引發的增量不實時進引擎。具體實現分為以下幾個步驟:
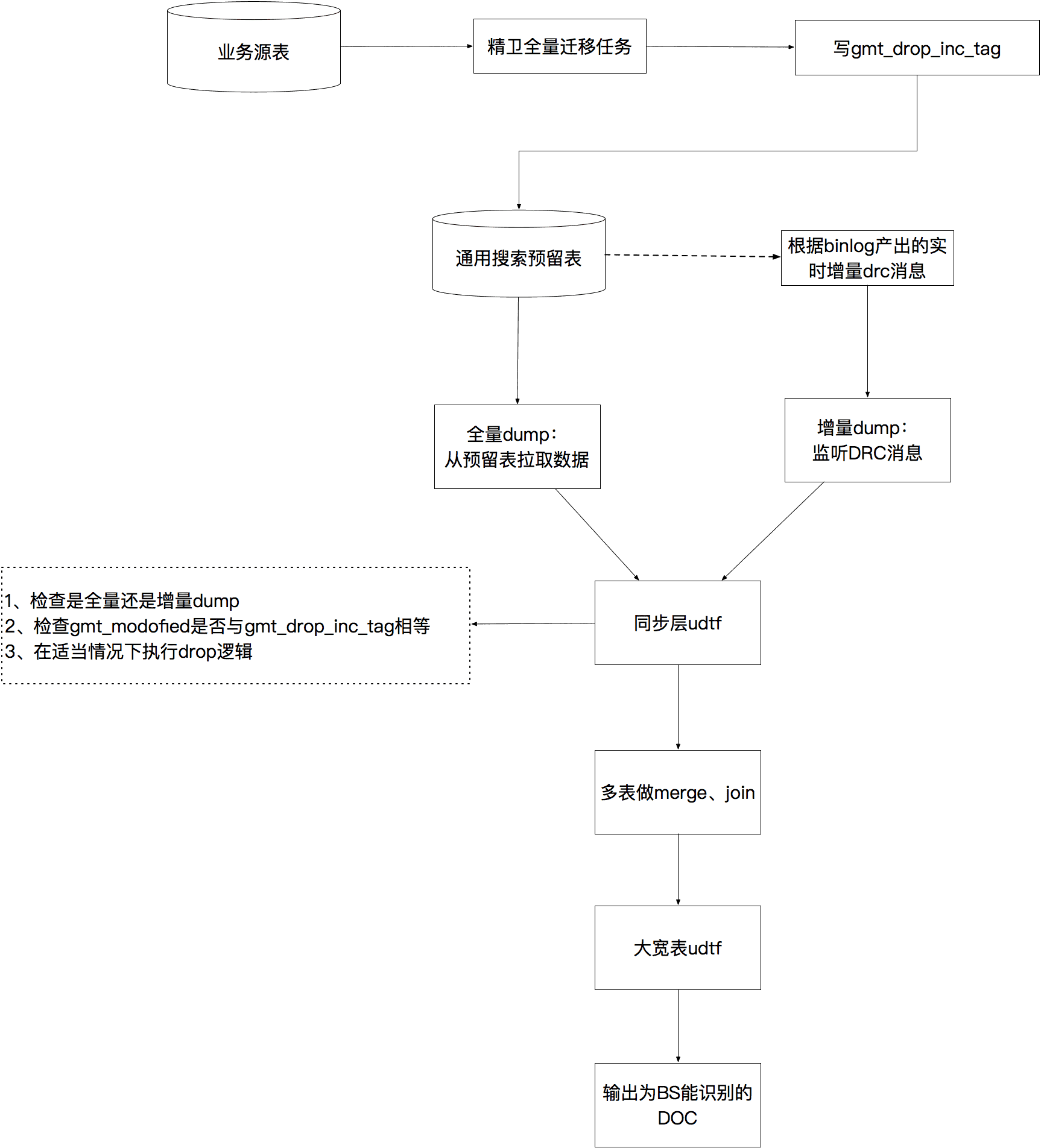
1、通用搜索預留表按照db表的創建規范,都會有一個gmt_modofied字段,類型為datetime。當預留表中的數據發生任何變化(增、刪、改)時,gmt_modofied字段都會更新為本次操作的時間戳。這個邏輯在精衛遷移任務的DAO層實現。
2、為通用搜索預留表的每一張表額外增加一個datetime類型字段,命名為gmt_drop_inc_tag。精衛全量任務為新業務導數據時,我們在精衛任務啟動參數中帶上“drop_inc_tag=true”的標識,相應地我們在精衛自主消費代碼中識別到這個標識后,會在完成數據轉換生成的DAO層入參DO中把gmt_drop_inc_tag字段賦值為gmt_modofied一樣的值,然后寫入DB。而非新業務全量和增量精衛任務的啟動參數中無“drop_inc_tag=true”的標識,則其他業務的增量精衛任務寫入DB的記錄中只會更新gmt_modofied而不會更新gmt_drop_inc_tag字段。
3、在引擎原生dump層,我們在每一張通用搜索預留表與后續merge節點之間增加一層udtf邏輯代碼。這里的udtf代碼是dump層對外開放的一個口子,允許引擎接入方在dump流程上對數據做一些特殊處理,每一條上游的數據都會經過udtf的邏輯處理后再輸出到下游進行merge、join、輸出給BS系統。我們在這里實現的邏輯是,如果識別到當前是全量dump流程,則把當前流入數據的gmt_drop_inc_tag置為空,然后向下游輸出;若識別到當前是增量dump流程,則檢查當前流入的數據其gmt_modofied字段與gmt_drop_inc_tag字段是否相同,若兩字段相同則對此數據執行drop邏輯,若兩字段不同則把當前流入數據的gmt_drop_inc_tag置為空后向下游輸出。所有被執行了drop邏輯的數據都會被dump系統丟棄,不會輸出到最終產出的數據文件中。
如此一來,老業務的增量數據都任然正常經過dump流程后通過BS(BuildServcie)系統實時反映到搜索在線服務中。而本次新接入業務的全量遷移數據都只是從業務源表遷移到了搜索預留表中,BS系統完全感知不到這批數據的存在。待新業務的數據已經全部從源表遷移到預留表之后,我們對引擎服務觸發一次大全量流程,即先以全量dump的方式把通用搜索預留表的數據全部重新走一次dump邏輯,產出完整的HDFS數據,然后離線BS系統批量對此HDFS數據構建索引,然后加載到searcher機器提供在線服務。隨后,對新業務開啟精衛增量遷移任務,保證業務源表的變更實時反映到引擎中。
效果
閑魚這套通用搜索系統目前已經在線上為3個業務提供服務,每個新業務都能在10~30分鐘內完成接入。而在有此系統之前,一個業務方如果想接入搜索能力,需要向團隊中精通搜索底層原理的搜索業務owner提開發需求,等待一周左右開發排期,待搜索owner完成一套引擎服務搭建后,業務同學后才能進入業務開發階段。 我們用此系統消除了搜索owner的單點阻塞問題,實現了用自動化技術解放生產力。
展望
閑魚還將繼續在自動化提效方面進行更多探索,把開發同學從繁重的重復性工作中解放出來,將時間投入到更具有創造性意義的工作中。閑魚今年有更多有深度有挑戰的項目在進行中,期待您的加入,與我們共同創造奇跡。