全面了解TCP/IP知識體系結構總結
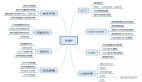
一、TCP知識體系
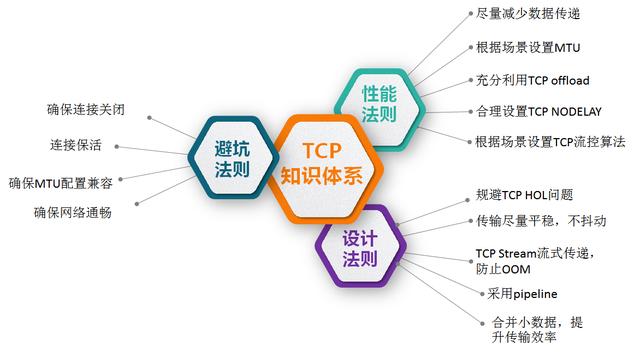
我們從三個維度去分析服務器開發的TCP知識體系,分別為性能法則、設計法則和避坑法則。
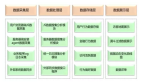
二、性能法則
性能法則大致總結如下:

1. 減少數據傳遞
下面引用了左耳朵的"程序員如何用技術變現"文章中的一部分:

從上面我們可以看出減少數據傳遞對于性能是非常重要的。
2. 根據場景設置MTU
如果是內網應用,通過合理設置MTU來提升性能是不能忽視的一種手段;對于移動應用,一般可以設置MTU為1492;對于外網應用,則設置通用的1500。
3. 利用TCP offload
帶寬消耗高的應用,可以考慮利用TCP offload來提升性能。
4. TCP NODELAY
目前服務器程序一般建議設置NODELAY為true,如果需要對小數據包合并,則可以考慮在應用層做數據合并(參考下圖Wikipedia中內容)。

詳細內容請參考:"https://en.wikipedia.org/wiki/Nagle%27s_algorithm"
5. 采用合適的擁塞控制算法
下圖展示了數據包經過路由器Queue的場景。
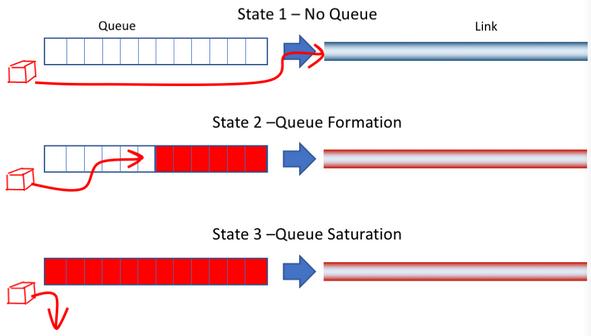
第一種是最理想的情況,數據包到達路由器,無需等待就能直接轉發出去;第二種是等待一段時間,才能發送出去;第三種是因為路由器queue滿,數據包被路由器丟掉。
發送數據過猛可能導致第三種情況發生。
下面展示了Linux默認算法CUBIC和BBR算法在丟包情況下的吞吐量對比:
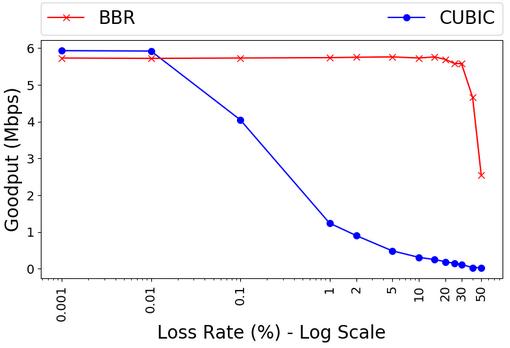
從上圖可以看出,BBR擁塞控制算法可以在20%丟包率以下保持吞吐量,因此BBR的抗網絡抖動性比CUBIC要好。
BBR算法優異的根本原因如下:
- 在有一定丟包率的網絡鏈路上充分利用帶寬
- 降低路由器的queue占用率,從而降低延遲
一般建議在非網絡擁塞導致丟包的場合使用BBR算法,例如移動應用。
對于帶寬比較大,RTT時間比較長的應用場景,可以參考。
6. 使用REUSEPORT
針對短連接應用(例如PHP應用),為防止服務器應用來不及接收連接請求,可以采用Linux REUSEPORT機制。我們開發的數據庫中間件Cetus利用REUSEPORT機制成功避開了應用短連接的沖擊。
三、設計法則
1. 規避TCP HOL問題
盡量采用多連接,不要采用單個連接來傳遞大量數據。
2. 傳輸盡量平穩,不抖動
如果數據傳輸比較抖動,那么容易導致如下問題:
- 內存膨脹
- 性能不穩定
- 壓縮算法效率低下
在開發數據庫中間件Cetus的時候,我們控制了每次數據傳輸的傳輸量,在采用同樣壓縮算法的情況下,cetus壓縮比遠遠好于MySQL的壓縮比。
3. TCP stream流式傳輸
TCP stream主要用在中間件服務。
下圖是沒有采用TCP stream的交互圖。中間件接收完Server端的響應后,才開始發送給客戶端。不少數據庫中間件采用這樣的工作方式,導致中間件內存消耗巨大。
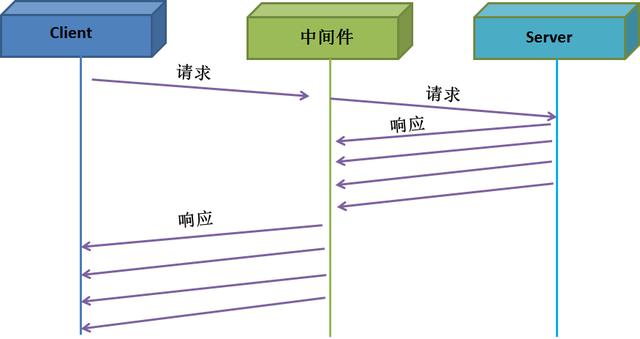
下圖采用了TCP stream方式后,不僅降低了延遲,也降低了內存消耗(因為無需保留所有響應)。
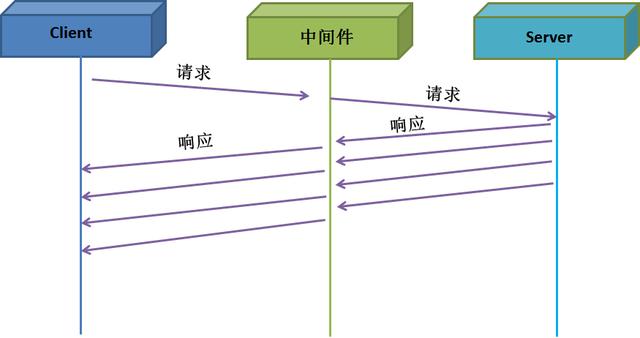
服務器中間件程序最好實現TCP stream,否則易發生內存炸裂等問題。
4. 上層應用pipeline機制
TCP本身并不具備pipeline機制,但上層應用可以利用pineline機制來提升服務器應用的吞吐量。
下圖是沒有采用pipeline的交互圖,客戶端需接收到服務器響應后才能發送下一個請求。
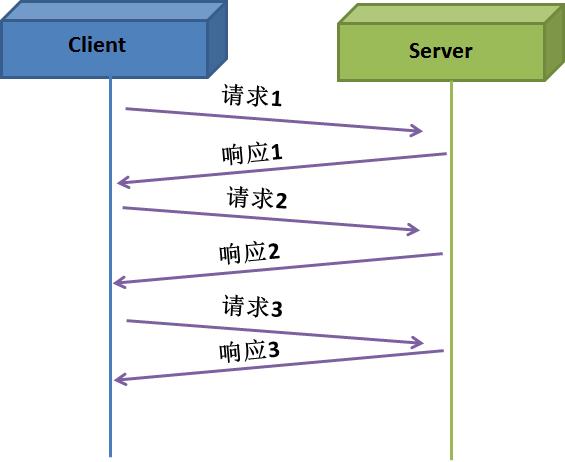
下圖是采用pipeline的交互圖。客戶端無需等待響應就可以連續發送多個請求。
對于TCP來說,請求1、請求2和請求3看成一個請求,響應1、響應2和響應3看成一個響應;對于上層應用來說,則是3個請求,3個響應。
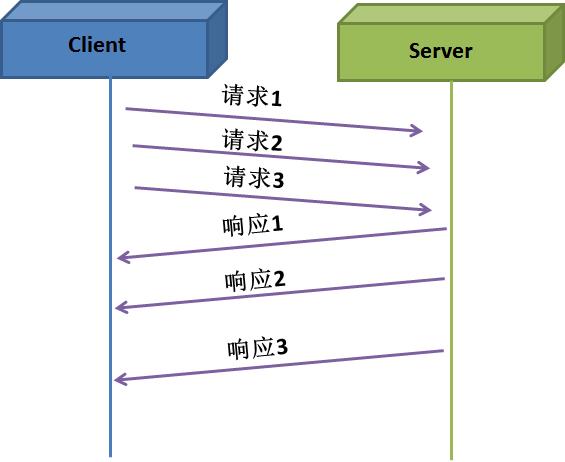
目前,很多協議或者軟件采用pipeline機制來提升應用的吞吐量,例如HTTP v2協議支持pipeline發送請求,Redis采用pipeline機制來提升應用的吞吐量。
5. 合并小數據
運行TCPCopy的時候,intercept返回響應包的TCP/IP header給tcpcopy。一般TCP/IP header只有幾十字節,如果每次write操作只傳輸一個響應包的TCP/IP header,那么效率就會非常低。為了提升傳輸效率,intercept合并若干個響應包的TCP/IP header信息一起發送。
四、避坑法則4.1 加上keepalive機制
TCP keepalive機制可以用來檢測連接是否還存活,具體可以參考"對付Reset流氓干擾:TCP keepalive"。
1. MTU
參考:"https://wiki.archlinux.org/index.php/Jumbo_frames"
2. 確保網絡通暢
云環境、中途設備程序、TCP offload和負載均衡器或多或少存在一些問題,而這些問題如果不及時解決,會極大影響程序的性能和問題排查。
這方面一般可以通過抓包的方式去查明問題。
下面展示了負載均衡器自身bug導致了網絡不通暢。
由于負載均衡器沒有嚴格按照TCP session的方式進行負載均衡,有些TCP session的數據包跑到了不同的機器,進而導致應用端報請求超時。
最初連接
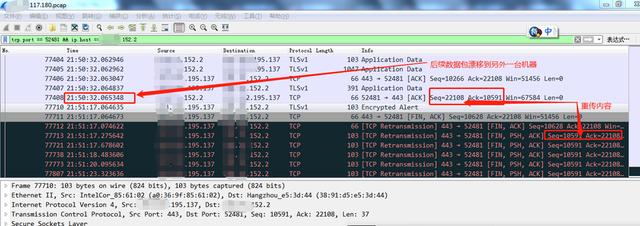
后來這個連接的數據包跑到了176機器(參考下圖)。
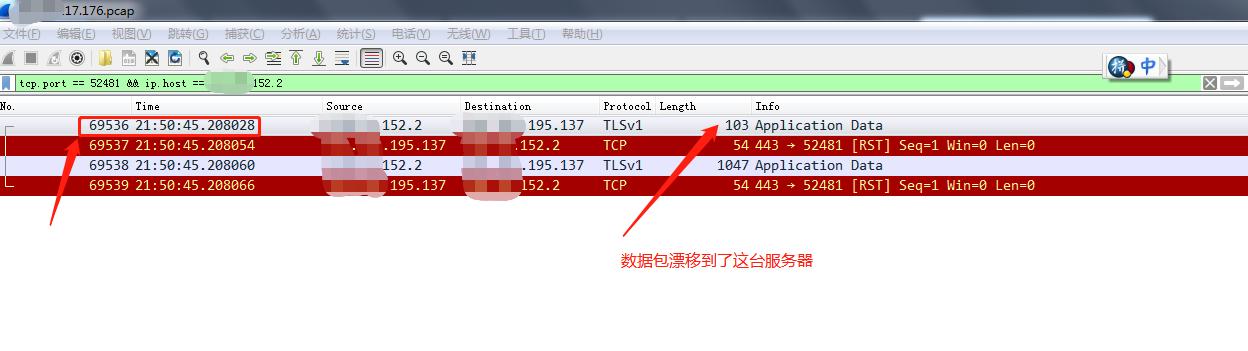
負載均衡器出現這種bug,會造成用戶的極大困擾,很難查明問題原因。
這時要么更換負載均衡器,要么找廠商解決負載均衡器的bug,否則上層應用會一直報網絡超時等問題。
五、總結
對于服務器開發人員,只有了解了TCP知識體系后,開發起來才能夠得心應手,同時可以規避一些潛在的坑。