記一次生產(chǎn)數(shù)據(jù)庫log file sync 等待事件異常及處理過程
今天主要從一個案例來介紹一下log file sync這個等待事件及常用的一些解決辦法,下面先看下故障時間段的等待事件。
1. 查看卡頓時間段的等待事件及會話
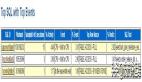
查看故障時間段等待事件、問題sql id及會話訪問次數(shù)
- select trunc(sample_time, 'mi') tm, sql_id, nvl(event,'CPU'),count(distinct session_id) cnt
- from dba_hist_active_sess_history
- where sample_time between to_date('2019-09-03 9:30:00') and
- to_date('2019-09-03 11:00:00')
- group by trunc(sample_time, 'mi'), sql_id,nvl(event,'CPU')
- order by cnt desc;
查看該sql相關(guān)的等待事件及對應(yīng)的會話訪問次數(shù)
- select sql_id, nvl(event, 'CPU'), count(distinct session_id) sz
- from dba_hist_active_sess_history a, dba_hist_snapshot b
- where sample_time between to_date('2019-09-03 09:30:00') and
- to_date('2019-09-03 11:00:00')
- and sql_id = '0spj1q9t1yh2d'
- and a.snap_id = b.snap_id
- and a.instance_number = b.instance_number
- group by sql_id, nvl(event, 'CPU')
- order by sz desc;
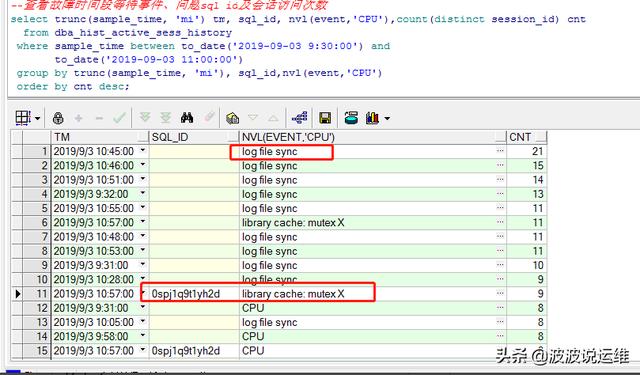
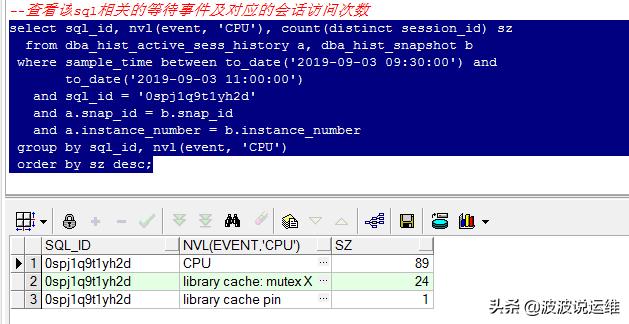
很明顯看到都是log file sync等待事件很明顯。那什么是log file sync呢?
2. log file sync -- 日志文件同步
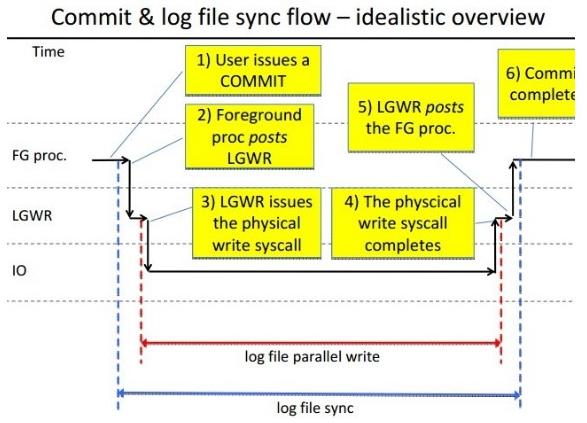
在一個提交(commit)十分頻繁的數(shù)據(jù)庫中,一般會出現(xiàn)log file sync等待事件,當(dāng)這個等待事件出現(xiàn)在top5中,這個時侯我們需要針對log file sync等待事件進行優(yōu)化,一定要盡快分析并解決問題,否則當(dāng)log file sync等待時間從幾毫秒直接到20幾毫秒可能導(dǎo)致系統(tǒng)性能急劇下降,甚至?xí)?dǎo)致短暫的掛起。
當(dāng)一個用戶提交或回滾數(shù)據(jù)時, LGWR 將會話期的重做由 Log Buffer 寫入到重做日志中,LGWR 完成任務(wù)以后會通知用戶進程。 日志文件同步等待( Log File Sync) 就是指進程等待LGWR 寫完成這個過程, 對于回滾操作,該事件記錄從用戶發(fā)出 rollback 命令到回滾完成的時間。如果該等待過多,可能說明 LGWR 的寫出效率低下,或者系統(tǒng)提交過于頻繁。 針對該問題,可以關(guān)注 log file parallel write 等待事件,或者通過 user commits,user rollback 等統(tǒng)計信息觀察提交或回滾次數(shù)。
總之,log file sync的根源一般是頻繁commit/rollback或磁盤I/O有問題,大量物理讀寫爭用。
可以通過如下公式計算平均 Redo 寫大小:
- avg.redo write size = (Redo block written/redo writes)*512 bytes
如果系統(tǒng)產(chǎn)生 Redo 很多,而每次寫的較少,一般說明 LGWR 被過于頻繁地激活了。 可能導(dǎo)致過多的 Redo 相關(guān) Latch 的競爭, 而且 Oracle 可能無法有效地使用 piggyback 的功能。從一個AWR報告中提取一些數(shù)據(jù)來研究一下這個問題。
log file sync等待事件的優(yōu)化方案:
- 優(yōu)化了redo日志的I/O性能,盡量使用快速磁盤,不要把redo log file存放在raid 5的磁盤上;
- 加大日志緩沖區(qū)(log buffer);
- 使用批量提交,減少提交的次數(shù);
- 部分經(jīng)常提交的事務(wù)設(shè)置為異步提交;
- 適當(dāng)使用NOLOGGING/UNRECOVERABLE等選項;
- 采用專用網(wǎng)絡(luò),正確設(shè)置網(wǎng)絡(luò)UDP buffer參數(shù);
- 安裝最新版本數(shù)據(jù)庫避免bug
3. awr報告--rman備份
收集一下awr報告來分析,收集過程這里就不做介紹了。
(1) 報告如下:
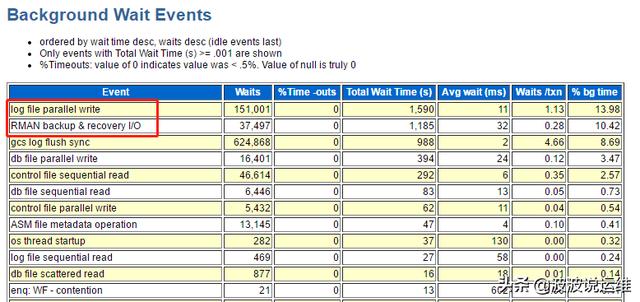
這里可以注意到有一個異常的等待事件--RMAN backup & recovery I/O,應(yīng)該是rman剛好在做備份導(dǎo)致的磁盤IO繁忙
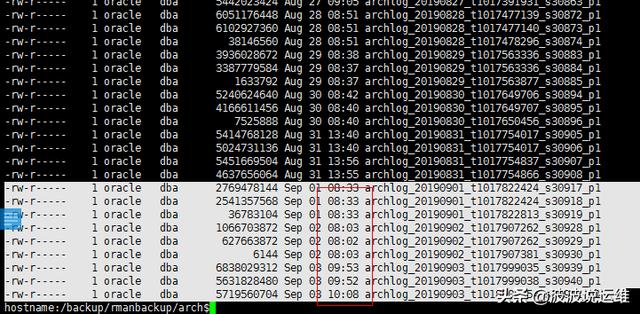
(2) 觀察RMAN日志
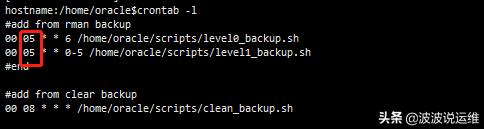
很明顯是從凌晨5點開始備份,一直備份到接近10點導(dǎo)致,這里也消耗了一部分的磁盤IO
(3) 調(diào)整備份時間
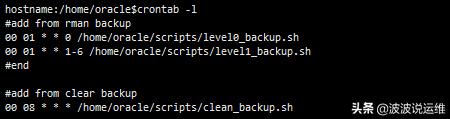
下面回到log file sync的分析上。
4. awr報告--log file sync
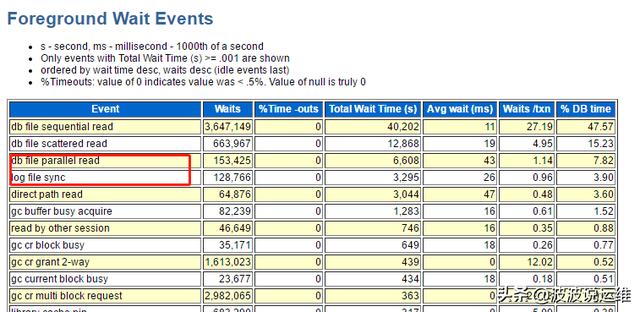
注意以上輸出信息,這里 log file sync 和 db file parallel write 等等待事件同時出現(xiàn),那么可能的一個原因是 I/O 競爭導(dǎo)致了性能問題, 實際用戶環(huán)境正是日志文件和數(shù)據(jù)文件同時存放在 RAID5 的磁盤上,存在性能問題需要調(diào)整。
(RAID 5不對數(shù)據(jù)進行備份,而是把數(shù)據(jù)和與其相對應(yīng)的奇偶校驗信息存儲到組成RAID5的各個磁盤上,并且奇偶校驗信息和相對應(yīng)的數(shù)據(jù)分別存儲于不同的磁盤上。當(dāng)RAID5的一個磁盤數(shù)據(jù)損壞后,利用剩下的數(shù)據(jù)和相應(yīng)的奇偶校驗信息去恢復(fù)被損壞的數(shù)據(jù)。)
5. 計算平均日志寫大小:
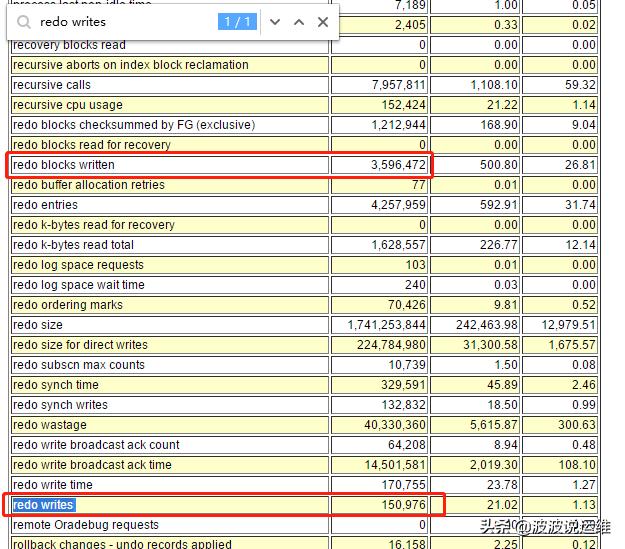
- avg.redo write size = (Redo block written/redo writes)*512 bytes= ( 3,596,472/ 150,976 )*512 =12196 bytes =11KB
這個平均值有點小了,說明系統(tǒng)的提交過于頻繁。
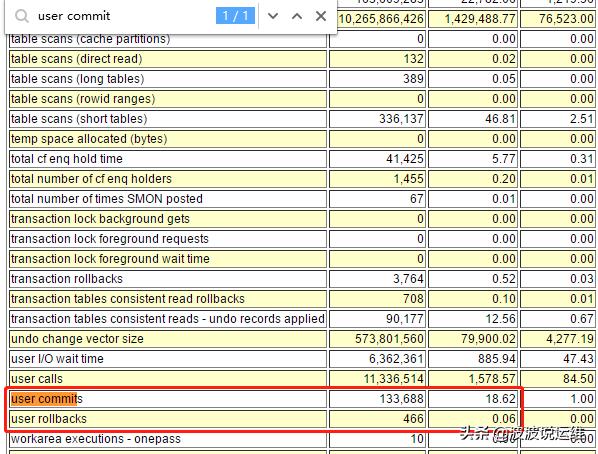
從以上的統(tǒng)計信息中, 可以看到平均每秒數(shù)據(jù)庫的提交數(shù)量是18.62 次。 如果可能, 在設(shè)計應(yīng)用時應(yīng)該選擇合適的提交批量,從而提高數(shù)據(jù)庫的效率。
6. Oracle11g新特性(Adaptive Log File Sync - 自適應(yīng)的Log File Sync)
關(guān)于 Log File Sync 等待的優(yōu)化,在Oracle數(shù)據(jù)庫中一直是常見問題,LOG FILE的寫出性能一旦出現(xiàn)波動,該等待就可能十分突出。
在Oracle 11.2.0.3 版本中,Oracle 將隱含參數(shù) _use_adaptive_log_file_sync 的初始值設(shè)置為 TRUE,由此帶來了很多 Log File Sync 等待異常的情況,當(dāng)前臺進程提交事務(wù)(commit)后,LGWR需要執(zhí)行日志寫出操作,而前臺進程因此進入 Log File Sync 等待周期。
在以前版本中,LGWR 執(zhí)行寫入操作完成后,會通知前臺進程,這也就是 Post/Wait 模式;在11gR2 中,為了優(yōu)化這個過程,前臺進程通知LGWR寫之后,可以通過定時獲取的方式來查詢寫出進度,這被稱為 Poll 的模式,在11.2.0.3中,這個特性被默認開啟。這個參數(shù)的含義是:數(shù)據(jù)庫可以在自適應(yīng)的在 post/wait 和 polling 模式間選擇和切換。
_use_adaptive_log_file_sync 參數(shù)的解釋就是: Adaptively switch between post/wait and polling ,正是由于這個原因,帶來了很多Bug,反而使得 Log File Sync 的等待異常的高,在遇到問題時,通常將 _use_adaptive_log_file_sync 參數(shù)設(shè)置為 False,回歸以前的模式,將會有助于問題的解決。
這里我的數(shù)據(jù)庫版本是11.2.0.1,檢查發(fā)現(xiàn)也有這種情況,所以做了一些參數(shù)上的調(diào)整:
- SQL> show parameter parallel_adaptive_multi_user;
- SQL> alter system set parallel_adaptive_multi_user=false scope=both;