













彌合AI大規模落地的巨大缺口!阿里、騰訊、百度等聯合推出互聯網服務AI基準
現如今,互聯網服務正經歷著根本性的變化,并逐漸轉向智能計算時代。現代互聯網服務提供商普遍采用人工智能來增強其服務。在這種背景下,研究人員提出了許多創新的人工智能算法、系統和架構,因此基準(benchmark)和評估基準的重要性也隨之上升。然而,現代互聯網服務采用基于微服務的體系結構,由多種模塊組成。這些模塊的多樣性和執行路徑的復雜性、數據中心基礎設施的龐大規模和復雜層次結構、數據集和工作負載的保密問題對設計基準提出了巨大挑戰。
這篇論文中,百度、阿里、騰訊等幾家頭部互聯網服務提供商聯合中國的 17 個互聯網企業共同推出了第一個具有行業標準的互聯網服務 AI 基準——AIBench。AIBench 提供了一個高度可擴展、可配置、靈活的基準測試框架。作者從三個最重要的互聯網服務領域(搜索引擎、社交網絡和電子商務)中確定了 16 個較為突出的人工智能問題領域。在 AIBench 框架的基礎上,作者利用真實世界的數據集和工作負載,設計并實現了第一個端到端的互聯網服務 AI 基準。在 CPU 和 GPU 集群上,作者對端到端應用程序基準進行了初步評估。與 AI 相關的組件顯著地改變了互聯網服務的關鍵路徑和工作負載特性,證明了端到端 AI 應用程序基準的正確性和必要性。這篇論文是目前為止最全面的 AI 基準工作。我們將在 AI 前線第 92 篇論文導讀中詳細解讀這項 AI 基準工作。
1、介 紹
人工智能技術的進步為圖像、視頻、語音、音頻等處理技術帶來了突破,推動了大規模人工智能算法、系統和體系結構的部署,因此現代互聯網服務提供商普遍采用人工智能來增強其服務。例如,阿里巴巴提出了一種新的 DUPN 網絡,以實現更有效的個性化。Google 推出了 TensorFlow 系統和 TPU 來提高服務性能。亞馬遜采用人工智能進行智能產品推薦。
因此,測量和評估這些算法、系統和體系結構的壓力逐漸增大。首先,現實中的數據集和工作負載被互聯網服務提供商視為一級機密問題,只有少數公開可用的性能模型,或針對行業規模互聯網服務的研究成果可用于進一步研究。由于沒有公開的互聯網服務基準,只有內部的研究人員才能推動互聯網服務的現狀,這種不可持續的狀態對推進開放式互聯網服務造成了巨大障礙。
其次,人工智能已經滲透到互聯網服務的幾乎所有方面。因此,為了覆蓋現實人工智能場景的關鍵路徑和突出特點,應該提供 端到端的應用基準(application benchmarks)。我們需要找到具有代表性的數據集,總結出主要的 人工智能問題領域(組件基準,component benchmarks),并進一步了解什么是最密集的 計算單元(微基準,micro benchmarks),在此基礎上,我們可以構建一個簡潔而全面的人工智能基準框架。
最后,從體系結構的角度來看,在早期階段將一個完整的人工智能應用程序移植到一個新的體系結構是很困難的,甚至是不可能的。而在后期,僅僅使用微基準或組件基準則不足以對不同模塊進行深入分析,或在現實應用場景中確定瓶頸問題。目前最先進的 AI 基準只提供了很少的微基準或組件基準,均無法覆蓋行業規模的互聯網服務的全部案例。因此,構建一個由全部的微基準或組件基準,以及端到端應用基準組成的互聯網服務 AI 基準,對于彌合這一巨大缺口具有重要意義。
論文貢獻:
- 提出并實現了一個高度可擴展、可配置、靈活的人工智能基準框架。
- 與 17 個行業合作伙伴共同確定了 16 個突出的人工智能問題領域,并相應地針對這些領域實施了 16 個組件基準。
- 設計并實施了第一個行業規模的端到端互聯網服務人工智能基準,其中包含一個底層電子商務搜索模型。
- 在 CPU 和 GPU 集群上,實現端到端的互聯網服務 AI 基準,并對性能、運行效率和執行時間進行了深入分析,為進一步優化提供了指導。
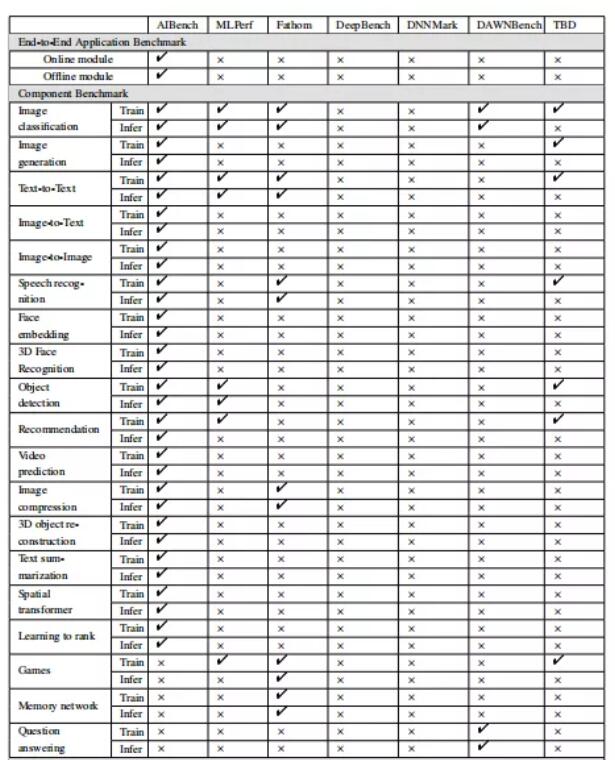
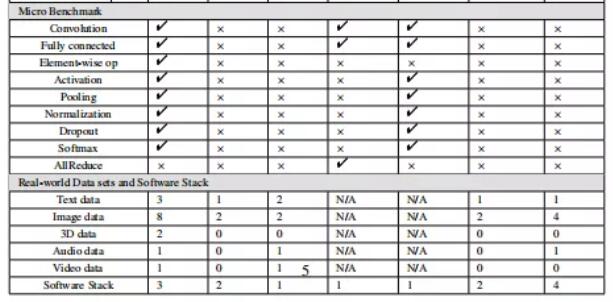
表 1:AI 基準對比
2、 AIBench 框架
2.1 框架結構
AIBench 框架提供了一個通用的、靈活且可配置的 AI 基準框架,如圖 1 所示。它提供了松散耦合的模塊,這些模塊可以通過配置和擴展組成端到端的應用程序,包括數據輸入、人工智能問題領域、在線推理、離線訓練和部署工具模塊。
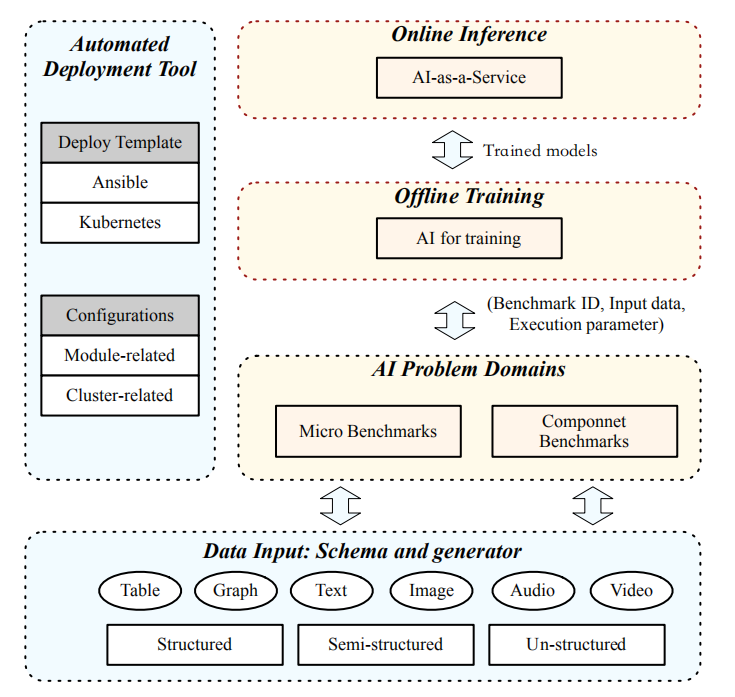
圖 1:AIBench 框架
數據輸入模塊 負責將數據輸入其他模塊。該模塊不僅從權威的公共網站收集了具有代表性的真實數據集,而且在匿名化后從行業合作伙伴處收集了數據集。在該數據模式的基礎上,進一步提供了一系列數據生成器,以支持大規模的數據生成,如用戶或產品信息。該框架集成了各種開源數據存儲系統,并支持大規模數據的生成和部署。
為了實現框架的多樣性和代表性,作者首先確定在最重要的互聯網服務領域發揮重要作用的 突出 AI 問題領域。然后給出了以這些 AI 問題領域為組件基準的人工智能算法的具體實現。此外,在這些組件基準測試中分析最密集的計算單元,并將它們作為一組微基準來實現。
框架還提供了 離線訓練 和 在線推理 模塊,以構建端到端的應用程序基準。首先,離線訓練模塊從 AI 問題領域模塊中選擇一個或多個組件基準,通過指定所需的基準 ID、輸入數據和執行參數(如批大小)。然后離線訓練模塊對模型進行訓練,并將訓練后的模型提供給在線推理模塊。在線推理模塊將訓練好的模型加載到服務系統中,例如 TensorFlow 服務。通過與關鍵路徑中的其他非 AI 相關模塊協作,一個端到端的應用程序基準就構建完成了。
為了能夠在大型集群上輕松部署,該框架還提供了 部署工具,其中包含兩個分別使用 Ansible 和 Kubernetes 的自動部署模板。其中,Ansible 模板支持在物理機或虛擬機上的可擴展部署,而 Kubernetes 模板則用于在容器集群上部署。
2.2 突出 AI 問題領域
為了覆蓋互聯網服務中廣泛的主要人工智能問題領域,作者深入分析了搜索引擎、社交網絡和電子商務三大主要互聯網服務的核心場景,如表 2 所示。一共確定了 16 個具有代表性的人工智能問題領域:
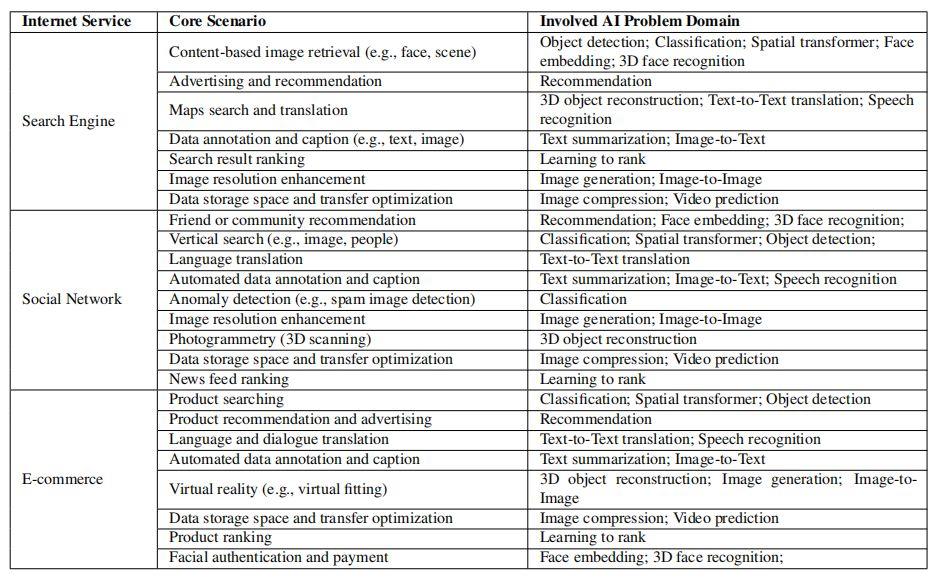
表 2:互聯網服務中的突出 AI 問題領域
分類: 從輸入數據中提取不同的主題類,這是一個有監督的學習問題,通過定義一組目標類別并訓練模型進行識別。它是互聯網服務或其它應用領域的典型任務,廣泛應用于類別預測、垃圾郵件檢測等多種場景中。
圖像生成: 提供一個無監督的學習問題來模擬數據的分布并生成圖像。此任務的典型場景包括圖像分辨率增強,可用于生成高分辨率圖像。
文本到文本翻譯: 將文本從一種語言翻譯到另一種語言,這是計算語言學最重要的領域,可以用來智能翻譯搜索和對話。
圖像到文本: 自動生成圖像的描述。它可以用來生成圖像標題和識別圖像中的光學字符。
圖像到圖像: 將圖像從一個表示轉換為另一個表示。它可以用來合成不同年齡的人臉圖像,模擬虛擬化妝。面部老化可以幫助搜索不同年齡階段的面部圖像。
語音識別: 將語音輸入識別和翻譯為文本。該任務主要應用于語音搜索和語音對話翻譯。
人臉嵌入表示: 將人臉圖像在內嵌空間中轉化為一個向量。該任務的典型場景是人臉相似度分析和人臉識別。
三維人臉識別: 從不同角度從多幅圖像中識別出三維人臉信息。主要研究三維圖像,有利于實現人臉相似度和人臉認證場景。
目標檢測: 檢測圖像中的對象。典型的場景是垂直搜索,如基于內容的圖像檢索和視頻對象檢測。
推薦: 提供建議。此任務廣泛用于廣告推薦、社區推薦或產品推薦。視頻預測:通過預測先前幀的變換來預測未來的視頻幀。典型的應用場景是視頻壓縮和視頻編碼,用于高效的視頻存儲和傳輸。
圖像壓縮: 壓縮圖像并減少冗余。從數據存儲開銷和數據傳輸效率的角度來看,這項任務對于互聯網服務是非常重要的。
三維物體重建: 預測和重建三維物體。典型的應用場景有地圖搜索、光場渲染和虛擬現實。
文本總結: 為文本生成摘要,對于搜索結果預覽、標題生成和關鍵字發現非常重要。
空間變換: 執行空間變換。典型應用場景是空間不變性圖像檢索,這樣即使圖像被大幅拉伸,也可以檢索圖像。
學習排序: 學習搜索內容的屬性,對搜索結果的得分進行排序,這是搜索服務的關鍵。
2.3 微基準和組件基準
針對上面總結的突出人工智能問題,作者給出了人工智能算法的具體實現。表 3 和表 4 列出了 AIBench 中的組件基準和微基準。總的來說,AIBench 包括 16 個用于 AI 問題的組件基準和 12 個從典型 AI 算法中提取計算單元的微基準。
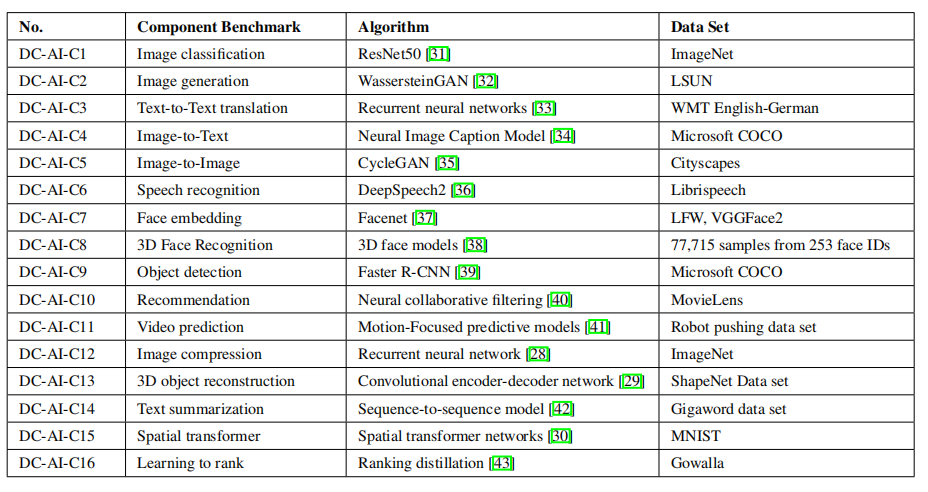
表 3:AIBench 組件基準
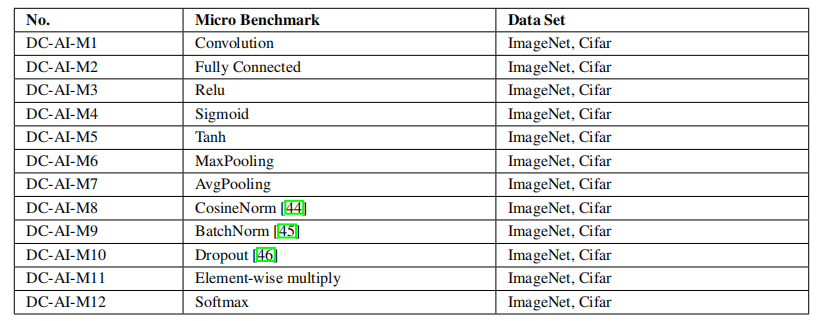
表 4:AIBench 微基準
2.4 數據模型
為了滿足不同應用的數據集的多樣性,作者收集了 15 個具有代表性的數據集,包括 ImageNet、CIFAR、LSUN、WMT English-German、CityScapes、Librispeech、Microsoft Coco、LFW、VGFace2、Robot Pushing、MovieLens、ShapeNet、Gigaword、MNIST、Gowalla 以及來自行業合作伙伴的 3D 人臉識別數據集。
2.5 評價指標
AIBench 專注于準確性、性能和能源消耗等行業重點關注的指標。在線推理的度量包括查詢響應延遲、尾部延遲和性能方面的吞吐量、推理精度和推理能耗。離線訓練的度量包括每秒處理的樣本、訓練特定 epoch 的時間、訓練達到目標精度的時間和訓練達到目標精度的能量消耗。
3、設計和實現應用基準
在 AIBench 框架的基礎上,作者實現了第一個端到端的 AI 應用基準,對現實的電子商務搜索任務進行完整的用例建模。
3.1 設計和實現
端到端應用基準由四個模塊組成:線上服務器、離線分析器、查詢生成器和數據存儲,如圖 2 所示。
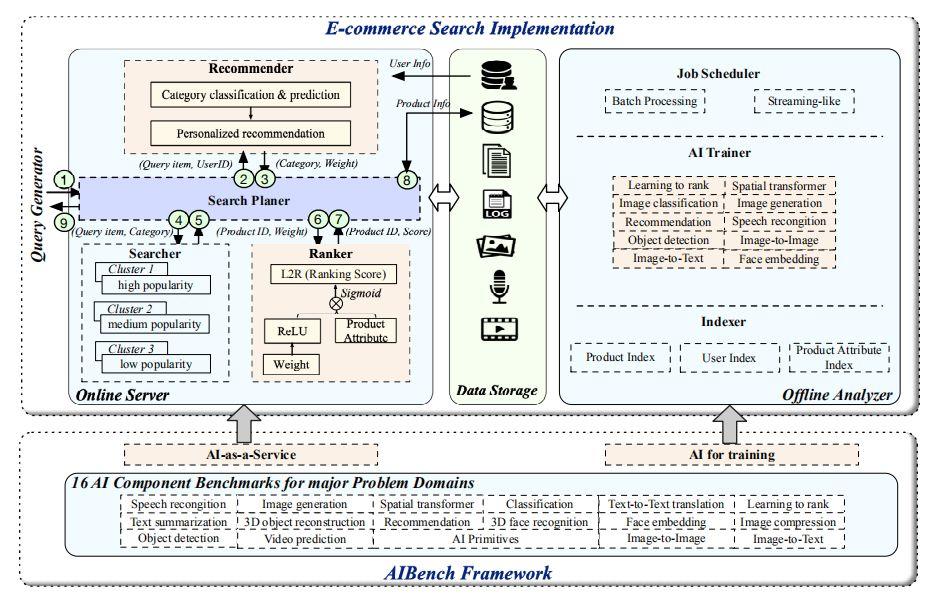
圖 2:AIBench 實現
在線服務器(Online server) 接收查詢請求,然后結合 AI 推理進行個性化搜索和推薦。
離線分析器(Offline analyzer) 選擇適當的 AI 算法實現,并進行訓練以生成學習模型。此外,離線分析器還負責構建數據索引以加速數據訪問。
查詢生成器(Query generator) 模擬并發用戶,并根據特定的配置將查詢請求發送到線上服務器。作者實現了基于 JMeter 的查詢生成器。
數據存儲模塊(Data storage module) 存儲各種數據,包括結構化、非結構化和半結構化數據,以及各種數據源,包括表格、文本、圖像、音頻和視頻。
3.1.1 在線服務器
在線服務器結合傳統的機器學習和深度學習技術提供個性化的搜索和推薦。在線服務器由四個子模塊組成,包括搜索計劃器、推薦器、搜索器和排序器。
搜索計劃器(Search Planer) 是在線服務器的入口。它負責接收來自查詢生成器的查詢請求,并將請求發送到其他在線組件并接收返回結果。作者使用 Spring Boot 框架來實現搜索計劃器。
推薦器(Recommender) 根據從用戶數據庫中獲取的用戶信息,對查詢項進行分析,并提供個性化推薦。作者使用 Flask Web 框架和 Nginx 構建類別預測推薦器,并采用 TensorFlow 實現在線推薦。
搜索器(Searcher) 部署在三個不同的集群上。按點擊率和購買率,產品可以按人氣高低分為三類。不同流行度產品的索引存儲在不同的集群中。對于每個類別,搜索器都采用不同的部署策略。高人氣的集群包含更多的節點和備份,保證了搜索效率。而受歡迎程度較低的集群部署的節點和備份數量最少。作者使用 Elasticsearch 來建立和管理三個搜索集群。
排序器(Ranker) 使用推薦器返回的權重作為初始權重,通過一個個性化的 L2R 神經網絡對產品得分進行排序。排序器也使用 Elasticsearch 實現產品排序。
在線服務流程如下:
(1)查詢生成器模擬并發用戶,向搜索計劃器發送查詢請求;
(2)搜索計劃器接收查詢請求并將查詢項發送給推薦者;
(3)推薦器對查詢進行分析,并將類別預測結果和個性化屬性權重返回給搜索計劃器;
(4)搜索計劃器向搜索器發送初始查詢項和預測的分類結果;
(5)搜索器搜索反向索引并將產品 ID 返回給搜索計劃器;
(6)搜索計劃器向排序器發送產品 id 和個性化屬性權重;
(7)排序器根據初始權重對產品進行排序,并將排序得分返回給搜索計劃器;
(8)搜索計劃器根據產品標識發送產品數據庫訪問請求,獲取產品信息;
(9)搜索計劃器將搜索到的產品信息返回給查詢生成器。
3.1.2 離線分析器
離線分析器負責訓練模型和建立索引,以提高在線服務性能。它由人工智能訓練器、作業調度程序和索引器三部分組成。
人工智能訓練器(AI trainer) 利用數據庫中存儲的相關數據訓練模型。
作業調度程序(Job scheduler) 提供了兩種訓練機制:批處理和流式處理。在現實場景中,一些模型需要經常更新。例如,當我們搜索一個項目并點擊第一頁中顯示的一個產品時,應用程序將立即基于我們剛剛單擊的產品訓練新模型,并在第二頁中顯示新的推薦。該基準實現考慮了這種情況,并采用流式方法每隔幾秒鐘更新一次模型。對于批處理,訓練器將每隔幾個小時更新一次模型。
索引器(Indexer) 用于為產品信息構建索引。
3.2 其他行業應用程序的可擴展性
以醫學人工智能場景為例,作者介紹了如何利用 AIBench 框架構建臨床診斷應用的端到端基準。人工智能相關的臨床診斷關鍵路徑包括以下步驟。
1)根據病史數據離線訓練一系列診斷模型,如檢測模型、分類模型、推薦模型等;
2)檢測患者體檢數據中的異常信息,如 CT 圖像的腫瘤檢測;
3)分類預測潛在疾病;
4)推薦適合的治療方案。
為了構建端到端的臨床診斷應用基準,AIBench 框架靈活地提供了與 AI 相關的離線模塊和在線模塊。在離線模塊中,選擇目標檢測、分類和推薦的組件基準作為訓練模型。在在線模塊中,將這些模型作為服務進行加載以在線推理。
4、 實驗設置
4.1 節點配置
作者部署了一個 16 節點的 CPU 和 GPU 集群。對于 CPU 集群,所有節點都連接到一個 1GB 的以太網網絡。每個節點配備兩個 Xeon E5645 處理器和 32 GB 內存。每個處理器包含六個內核。每個節點的操作系統版本均為 Linux CentOS 6.9,Linux 內核版本為 3.11.10。軟件版本分別是 JDK1.8.0、Python3.6.8 和 GCC 5.4。GPU 節點配備了四個 Nvidia Titan XP。每個 Titan XP 擁有 3840 個 Nvidia Cuda 內核和 12GB 內存。表 5 列出了每個節點的詳細硬件配置。
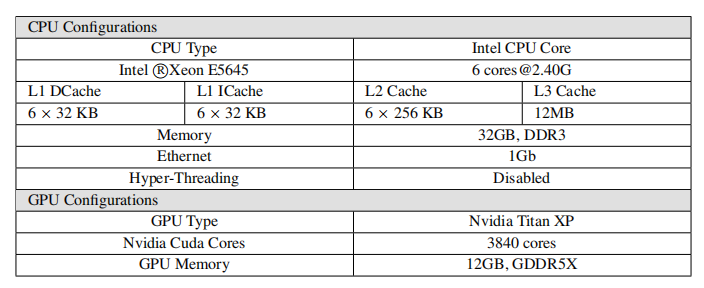
表 5:硬件設置細節
4.2 基準部署
在線服務器設置: 在線服務器部署在 16 節點 CPU 集群上,包含 1 個查詢生成器節點、1 個搜索計劃器節點、2 個推薦器節點、9 個搜索器節點、1 個排序器節點和 2 個數據存儲節點。表 6 列出了詳細的模塊設置信息和涉及的軟件信息。
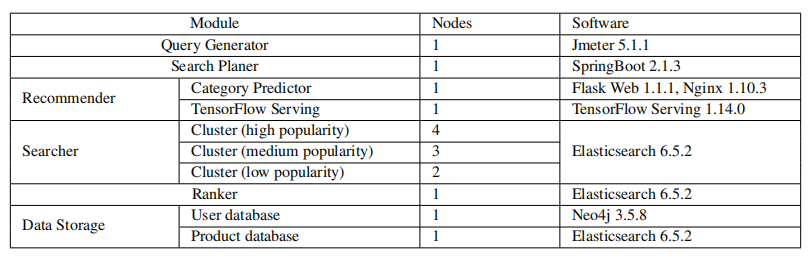
表 6:在線服務器設置
離線訓練器設置: 離線訓練器部署在 GPU 上。CUDA 和 Nvidia 驅動程序版本分別為 10.0 和 410.78,使用 1.1.0 版本 PyTorch 實現。
4.3 性能數據收集
作者使用 Network Time Protocol 在所有集群節點上實現時鐘同步,并獲得在線服務器的延遲和尾延遲度量。使用分析工具 Perf,通過硬件性能監視計數器(PMC)收集 CPU 微體系結構數據。對于 GPU 評測,作者使用 Nvidia 評測工具包 nvprof 來跟蹤 GPU 的運行性能。
5、評估
作者對端到端人工智能應用程序基準,包括在線服務器和離線分析器中包含的 10 個人工智能組件基準進行了測評。
5.1 在線服務器評估
作者評估了 16 節點 CPU 集群上的在線服務器性能。產品數據庫包含 10 萬個具有 32 個屬性字段的產品。查詢生成器用 30 秒的預熱時間模擬 1000 個用戶。用戶在每個思考時間間隔內連續發送查詢請求,遵循泊松分布。當 20000 個查詢請求完成時,收集性能數據。
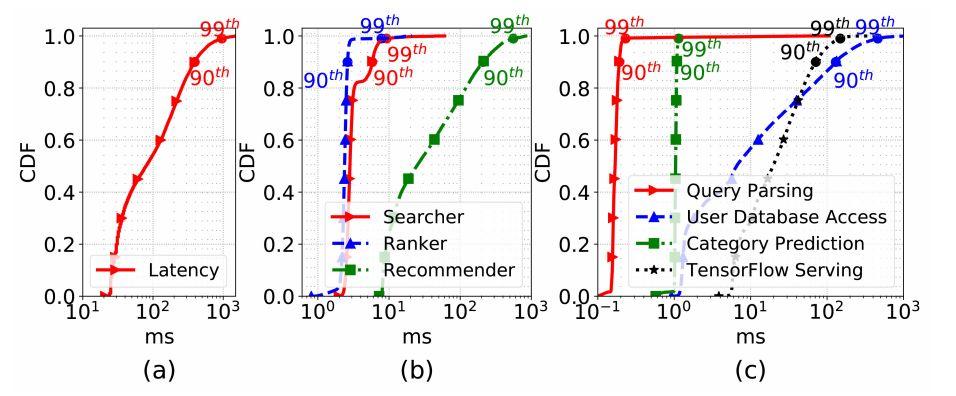
圖 3:在線服務器延遲
延遲是衡量服務質量的重要指標。圖 3 給出了在線服務器的延遲。如圖 3(a)所示,當前基準實現的整個執行路徑的總延遲的平均值、第 90 百分位和 99 百分位對應分別為 161.13 毫秒、392 毫秒和 956 毫秒。作者進一步深入分析了每個模塊的延遲(圖 3b),推薦器占據了最大的延遲:平均延遲 75.7 毫秒, 90 百分位延遲 209.4 毫秒,99 百分位延遲 557.7 毫秒。相比之下,搜索器和推薦求的延遲都在 4 毫秒之內。
此外,圖 3(c)給出了推薦器在查詢解析、用戶數據庫訪問、類別預測和 TensorFlow 服務方面的延遲分解。作者發現數據庫訪問和 TensorFlow 服務延遲是影響服務性能的前兩個因素。復雜的數據結構和頻繁的垃圾收集對數據訪問速度有很大的影響。而 TensorFlow 服務則需要使用推薦模型進行前向推理,從而產生較大的延遲。為了衡量 AI 組件對服務性能的影響,找出瓶頸,作者從以下幾個方面進行了討論。
人工智能相關組件對服務性能的權重。 人工智能組件顯著改變了關鍵路徑。在評估中,在 AI 相關和非 AI 相關組件上花費的時間平均為 34.29 和 49.07 毫秒,第 90 百分位延遲為 74.8 和 135.7 毫秒,第 99 百分位延遲為 152.2 和 466.5 毫秒。這表明,一個工業規模的人工智能應用基準套裝是現代互聯網服務必不可少的。
AI 的局限性。 在線推理模塊需要對訓練后的模型進行加載,并進行前向計算得到結果。然而,神經網絡模型的深度或大小可能在很大程度上影響推理時間。當模型的大小從 184mb 增加到 253mb,TensorFlow 服務的延遲急劇增加,平均延遲從 30.78 毫秒增加到 125.71 毫秒,第 99 百分位延遲從 149.12 毫秒增加到 5335.12 毫秒。因此,互聯網服務架構師必須在服務質量和神經網絡模型的深度或大小之間進行權衡。
微結構行為的差異:
- 非 AI 相關組件與 AI 相關組件之間的差異。 作者使用 perf 對 AI 相關和非 AI 相關組件的緩存行為進行了采樣。作者發現,與非 AI 相關的組件相比,AI 相關的組件會遭受更多的緩存缺失(cache miss)。TensorFlow 服務每千條指令有 61 個 L2 緩存缺失,而非 AI 相關組件的平均數量僅為 37。
- 從小型神經網絡模型到大型神經網絡模型的變化。 作者比較了兩種神經網絡模型,一種是較小的 184mb,另一種是較大的 253mb。對于更大的模型,每千條指令的 L3 緩存缺失率會急劇增加,從 1.38 增加到 8.9,這會導致大量內存后端暫停以從內存中獲取數據。因此,第 99 百分位的延遲增加了 30 倍以上。
5.2 離線訓練評估
在本小節中,主要分析了 GPU 的執行效率,并評估了 Titan XP 上端到端 AI 應用程序基準的離線分析器中使用的十個組件基準。
作者通過函數級運行時間分解和執行暫停分析全面分析了 GPU 的運行效率。圖 4 顯示了每個組件基準的 SM 效率,從 29%(學習排序)到 95%(推薦)不等。
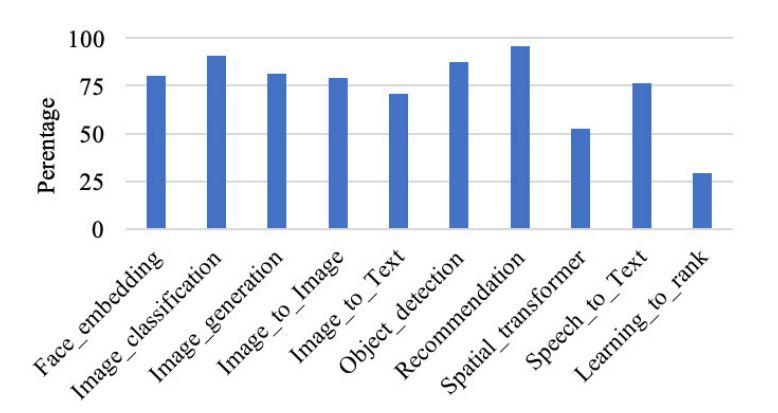
圖 4:SM 效率
為了研究影響性能的因素,作者首先進行運行時間分解分析,將基準分解為熱點內核或函數,然后根據不同的暫停百分比來計算 GPU 的執行效率。
5.2.1 運行時間分解
作者利用 nvprof 對運行時間進行跟蹤,找出占運行時間 80% 以上的熱點函數。作者將占用大量運行時間的函數挑選出來,并根據它們的計算邏輯將它們分為幾類內核。通過統計,將十個組件基準中最耗時的函數分為六類內核:卷積、通用矩陣乘法(gemm)、批規一化、relu 激活函數、元素操作和梯度計算。每個內核都包含一組解決類似問題的函數。例如,gemm 內核包括單精度或雙精度浮點通用矩陣乘法等。圖 5 顯示了上述六個內核的運行時間分解,即每個內核中所有相關函數的平均值。
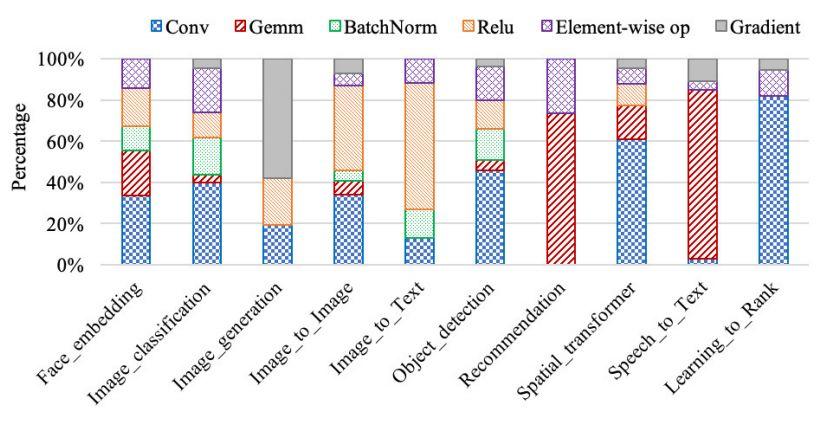
圖5:10個組件基準的運行時間分解
此外,對于每個內核,作者總結了在十個組件基準中占用大量運行時間的典型函數,如表 7 所示。
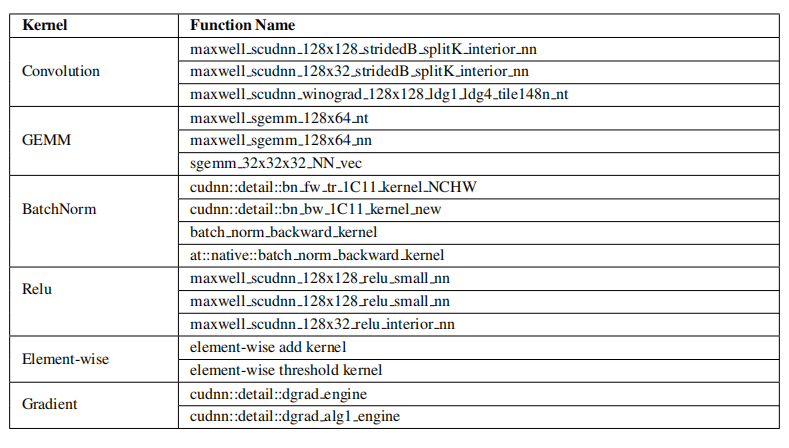
表7:每個內核的熱點函數
從圖 5 中我們發現,學習排序花費了太多時間進行卷積,相應的函數調用是 maxwell_scudnn_128x32_stridedB_splitK_interior_nn,SM 效率為 18.5%,這就是學習排序基準的 SM 效率最低的原因。作者認為,這六個內核及其相應的函數不僅是 CUDA 庫優化的優化方向,也是微結構優化的優化方向。
5.2.2 GPU 執行效率分析
針對以上六個最耗時的內核,作者評估了這些內核的八種暫停,包括指令獲取暫停(Inst_fetch)、執行依賴暫停(Exe_depend)、內存依賴暫停(Mem_dependent)、紋理暫停(Texture)、同步暫停(Sync)、常量內存依賴暫停(Const_mem_depend)、管線忙暫停(Pipi_busy)、內存限制暫停(Mem_throttle)。
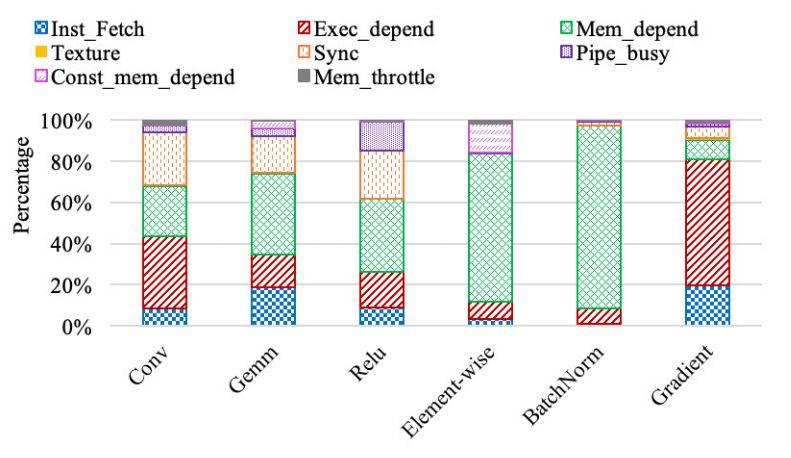
圖6:每個內核的暫停分解
圖 6 顯示了每個內核的八種暫停的分解。作者發現前兩個 GPU 執行暫停是內存依賴暫停和執行依賴暫停。內存依賴關系暫停可能是由于高速緩存缺失,因此加載 / 存儲資源不可用。優化策略包括優化數據對齊、數據局部性和數據訪問模式。由于指令級并行度較低,可能會出現執行依賴暫停,因此利用 ILP 可以在一定程度上緩解部分執行依賴暫停。
作者還確定了表 7 中函數級的暫停,以便為函數調用提供潛在的優化指導。例如,“卷積”類中 maxwell_scudnn_128x32_stridedB_splitK_interior_nn 函數的內存依賴暫停百分比達到 61%,而“GEMM”類中 maxwell_sgemm_128x64_nn 函數的內存依賴暫停百分比為 18%,說明需要不同的優化策略才能實現最大的性能改進。
結 論
這篇論文介紹了 17 家中國企業聯合推出的第一個行業標準互聯網服務人工智能基準套裝。作者提出并實現了一個高度可擴展、可配置和靈活的人工智能基準框架,并從三個最重要的互聯網服務領域:搜索引擎、社交網絡和電子商務中提取出 16 個突出的人工智能問題領域。在 AIBench 框架的基礎上,設計并實現了第一個端到端的互聯網服務 AI 基準套裝,并給出了一個底層的電子商務搜索模型。在 CPU 和 GPU 集群上,作者對端到端應用程序基準進行了初步評估。與 AI 相關的組件顯著地改變了互聯網服務的關鍵路徑和工作負載特性,證明了端到端 AI 應用程序基準的正確性和必要性。












