













機器學習轉化為生產力,警惕這4個常見陷阱!
大數據文摘出品
來源:topbots
編譯:武帥
在一場科技會議上,演講者詢問觀眾,“有誰為自己的業務開發過機器學習或者人工智能模型?”80%到90%的人都舉起了手。
“那么,你們當中有誰將它投入生產了呢?”演講者繼續發問。幾乎所有的人都放下了手。顯而易見,幾乎每個人都想在他們的業務中引入機器學習,但是這些人也遇到了一個大問題:讓模型可持續發展十分困難,尤其是在云架構的基礎上。
medium上一位博主也指出了這個問題,并提出了將機器學習模型投入生產的4個常見陷阱。
不要重新造輪子
大家對這句話早已耳熟能詳,卻并沒有什么改進,我們可以看到過太多因為拒絕使用已有的解決方案而失敗的案例。
比如,Amazon Web Services(AWS)和Google Cloud有著性能強大的機器學習套件和產品,且簡單易用,雖然他們不適用于每個案例,但是它們絕對是很好的一個入門平臺,特別是當公司員工沒有豐富的機器學習經驗的時候。
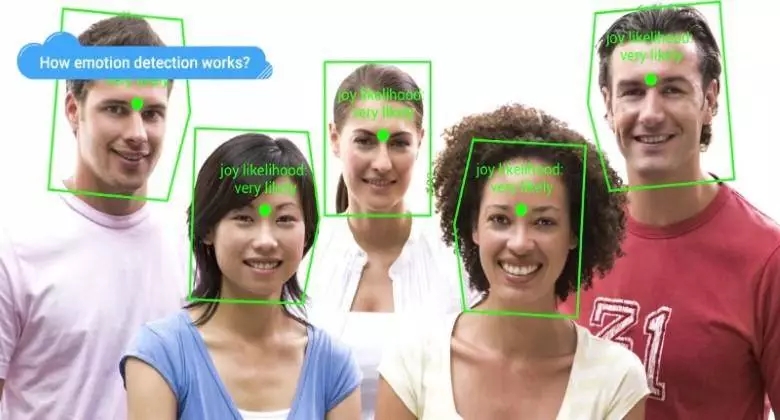
使用Google Vision API進行情感檢測,圖片來自TheNextWeb
上面就是可以利用Google Cloud的Vision API提取信息的一個示例。假設有顧客對產品的反映的圖片或者視頻的數據,并且想根據他們的面部表情來了解他們對產品的態度。那么就可以簡單地將圖片或者視頻作為數據提交給Google Vision進行處理,從而得到每張臉所呈現的大致情緒。
通常,AWS和Google Cloud上的產品的性價比就已經不錯了。此外,由于平臺會處理版本更新,功能添加等問題,因此維護工作也十分簡單。
解決方案不是一成不變的
對于較小的項目,這種簡單易行的方法可能足矣。但是對于更大的項目而言,要么成本過于昂貴,要么需要更多的自定義功能。
這種項目通常需要定制解決方案。就像之前提到的,有許多項目因為做得太多而失敗,同樣地,也有許多項目因為做得太少而失敗。我們需要保持“增量收益”的心態,即在不犧牲長期目標的前提下從我的產品中盡可能多地提取短期價值,但有時這種行為會破壞產品設計。
可以通過下述途徑來解決這個難題:
- 確保足夠了解當前問題以及期望的業務價值
- 進行必要的研究。
對于第一種途徑,如果團隊一開始就在技術細節上陷入困境,那么很可能見樹不見林。你必須時刻提醒自己“我真正想要完成的是什么?”
第二種途徑稍微有點復雜。可以先在谷歌學術上進行研究,梳理一下相關的學術出版物或博客文章,看看別人是如何解決我遇到的問題的。如果沒有滿意的結果,那么接下來試著找下相似的問題(可能是不同領域),直到找到一個不錯的線索。屆時,再尋找現成的解決方案,看看它們能否滿足需求。
如果滿足的話就實施該方案。如果不能,就需要構建更多的自定義項。
沒有適當地確定風險
在開發出一個很棒的解決方案之后,很多時候我們忘了這些模型固有的風險。當人們說“我們并不真正理解模型是如何工作的”,某種程度上來說確實如此。可解釋的AI是一個快速發展的領域,致力于確切地回答這類問題:“為什么這個模型是這樣運行的?”
但是當我們能夠確切解釋模型是怎樣運行這個問題之前,我們不得不采取一些必要的預防措施。
1. 了解模型之間的特征和相關性
通常,我們不希望我們的模型基于種族、性別、收入水平等因素進行決策,所以我們不將它們作為輸入。這樣就萬事大吉了吧?不一定。我們必須確保這些因素不會滲入到我們正在使用的其他特征中。例如,郵政編碼是一個很強的人口統計指標,據此可以推斷其所在區域。因此,在每個項目開始之前,我們必須花大力氣來探索數據。
2. 是否允許模型在生產中不斷發展?
當我向一些人提到“機器學習”時,他們通常認為那就是說模型會隨著人機交互而實時變動。雖然有些模型做到了這一點(改天撰文詳談),但是也有很多模型并沒有做到,而且理由很充分。即使缺少必要的檢查和監控,在輸入數據急劇變化的情況下,模型也不會失控。
但事實并非如此。假設你有一個根據市場趨勢動態更新的股票交易模型。在正常的市場中,它的效果很好,但是如果發生了某些不可預測的事(通常會在最糟糕的時候發生),模型可能會為了適應新環境而過度補償,從而完全放棄了原先訓練的策略。
3. 你打算多久重新訓練或更新一次模型?
這個問題并沒有標準答案。它完全取決于你的問題和建模技術,但是盡早弄清這一點還是很重要的。你應該有一個標準的更新方法和策略,原因很簡單:你怎么知道你的模型是在提升還是在下滑?
假設我有一個75%準確率的模型投入了生產。我怎么確定準確率是75%呢?通常,我會使用部分歷史數據作為驗證集(通常是20%)進行驗證。
現在假設我一個月后更新了模型,發現我的準確率居然達到了85%(多棒,快夸夸我)!于是我很開心地將更新推送到了平臺上。但是,我突然發現結果大幅度下降了,我的客戶也不停地抱怨。到底啥情況?
原因很簡單:如果我沒有保存我的驗證集(用來測試準確率的原始數據),那么我就不是拿蘋果和蘋果進行對比了。我不能確定更新后的模型性能是否比初始模型要好,這就會引起很多麻煩。
剛開始時并不需要用到機器學習
盡管這么說有點傷人,但是這很可能是你閱讀本文后的最大收獲。盡管機器學習被認為是當今計算機科學最酷的領域之一,但人們往往會忽略這樣一個事實:它只是皮帶上的工具,并不是皮帶本身。
你不會用手提鉆來釘釘子,所以當你能用基本的Python腳本完成任務時,不要使用機器學習。能夠使用尖端技術對我們來說誘惑力太大了,我也深知這一點,但是如果沒有必要的專業知識,你可能會造成不必要的失敗。
我見過太多這樣的例子了,人們在設計產品之前往往進行這樣的頭腦風暴:“我們怎樣使用一個聊天機器人?”,“你認為我們可以用面部識別做些什么?”……但是事實是,這些想法基本上都沒啥用。
鏈接:https://www.topbots.com/pitfalls-in-putting-ml-model-in-production/
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】























