機器學習的正則化是什么意思?
經常在各種文章或資料中看到正則化,比如說,一般的目標函數都包含下面兩項

其中,誤差/損失函數鼓勵我們的模型盡量去擬合訓練數據,使得最后的模型會有比較少的 bias。而正則化項則鼓勵更加簡單的模型。因為當模型簡單之后,有限數據擬合出來結果的隨機性比較小,不容易過擬合,使得最后模型的預測更加穩定。
但一直沒有一篇好的文章理清到底什么是正則化?
說到正則化,得先從過擬合問題開始談起。
1) The Problem of Overfitting(過擬合問題)
擬合問題舉例-線性回歸之房價問題:
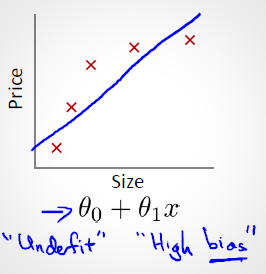
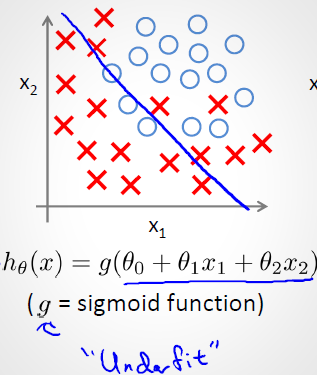
a) 欠擬合(underfit, 也稱High-bias,圖片來源:斯坦福大學機器學習第七課“正則化”)
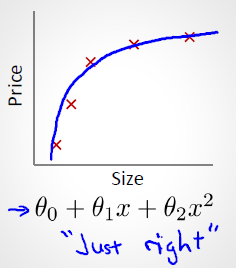
b) 合適的擬合:
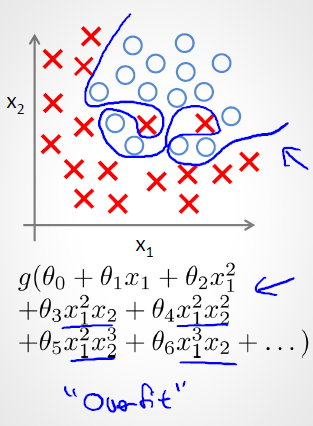
c) 過擬合(overfit,也稱High variance)

什么是過擬合(Overfitting):
如果我們有非常多的特征,那么所學的Hypothesis有可能對訓練集擬合的非常好(
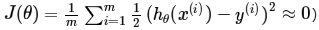
),但是對于新數據預測的很差。
過擬合例子2-邏輯回歸:
與上一個例子相似,依次是欠擬合,合適的擬合以及過擬合:
a) 欠擬合
b) 合適的擬合

c) 過擬合
如何解決過擬合問題:
首先,過擬合問題往往源自過多的特征,例如房價問題,如果我們定義了如下的特征:
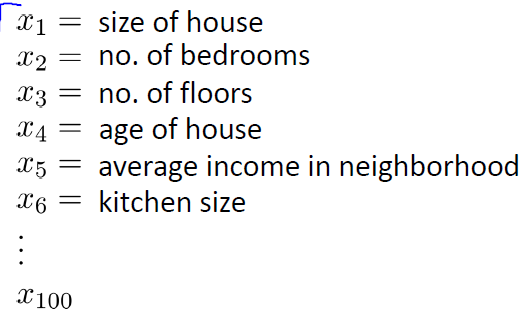
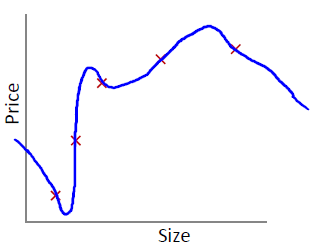
那么對于訓練集,擬合的會非常完美:
所以針對過擬合問題,通常會考慮兩種途徑來解決:
a) 減少特征的數量:
-人工的選擇保留哪些特征;
-模型選擇算法
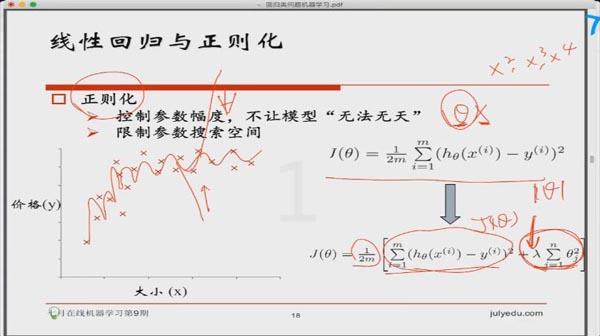
b) 正則化
-保留所有的特征,但是降低參數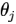 的量/值;
的量/值;
-正則化的好處是當特征很多時,每一個特征都會對預測y貢獻一份合適的力量;
所以說,使用正則化的目的就是為了是為了防止過擬合。

如上圖所示,紅色這條想象力過于豐富上下橫跳的曲線就是過擬合情形。結合上圖和正則化的英文,直譯應該叫規則化。
什么是規則?比如明星再紅也不能違法,這就是規則,一個限制。同理,規劃化就是給需要訓練的目標函數加上一些規則(限制),讓它們不要自我膨脹,不要過于上下無規則的橫跳,不能無法無天。
L1正則化和L2正則化
機器學習中幾乎都可以看到損失函數后面會添加一個額外項,常用的額外項一般有兩種,一般英文稱作ℓ1-norm和ℓ2-norm,中文稱作L1正則化和L2正則化,或者L1范數和L2范數。
L1正則化和L2正則化可以看做是損失函數的懲罰項。所謂『懲罰』是指對損失函數中的某些參數做一些限制。
對于線性回歸模型,使用L1正則化的模型建叫做Lasso回歸,使用L2正則化的模型叫做Ridge回歸(嶺回歸)。
下圖是Python中Lasso回歸的損失函數,式中加號后面一項α||w||1即為L1正則化項。
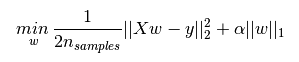
下圖是Python中Ridge回歸的損失函數,式中加號后面一項
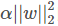
即為L2正則化項。
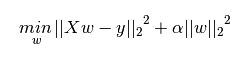
一般回歸分析中回歸w表示特征的系數,從上式可以看到正則化項是對系數做了處理(限制)。L1正則化和L2正則化的說明如下:
L1正則化是指權值向量w中各個元素的絕對值之和,通常表示為
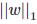
L2正則化是指權值向量w中各個元素的平方和然后再求平方根(可以看到Ridge回歸的L2正則化項有平方符號),通常表示為
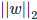
一般都會在正則化項之前添加一個系數,Python中用α表示,一些文章也用λ表示。這個系數需要用戶指定。
那添加L1和L2正則化有什么用?
L1正則化可以產生稀疏權值矩陣,即產生一個稀疏模型,可以用于特征選擇
L2正則化可以防止模型過擬合(overfitting)。當然,一定程度上,L1也可以防止過擬合
稀疏模型與特征選擇
上面提到L1正則化有助于生成一個稀疏權值矩陣,進而可以用于特征選擇。為什么要生成一個稀疏矩陣?
稀疏矩陣指的是很多元素為0,只有少數元素是非零值的矩陣,即得到的線性回歸模型的大部分系數都是0. 通常機器學習中特征數量很多,例如文本處理時,如果將一個詞組(term)作為一個特征,那么特征數量會達到上萬個(bigram)。
在預測或分類時,那么多特征顯然難以選擇,但是如果代入這些特征得到的模型是一個稀疏模型,表示只有少數特征對這個模型有貢獻,絕大部分特征是沒有貢獻的,或者貢獻微小(因為它們前面的系數是0或者是很小的值,即使去掉對模型也沒有什么影響),此時我們就可以只關注系數是非零值的特征。這就是稀疏模型與特征選擇的關系。
L1正則化和特征選擇
假設有如下帶L1正則化的損失函數:
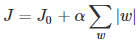
其中J0是原始的損失函數,加號后面的一項是L1正則化項,α是正則化系數。注意到L1正則化是權值的絕對值之和,J是帶有絕對值符號的函數,因此J是不完全可微的。
機器學習的任務就是要通過一些方法(比如梯度下降)求出損失函數的最小值。當我們在原始損失函數J0后添加L1正則化項時,相當于對J0做了一個約束。令L=α∑w|w|,則J=J0+L,此時我們的任務變成在L約束下求出J0取最小值的解。
考慮二維的情況,即只有兩個權值w1和w2,此時L=|w1|+|w2|對于梯度下降法,求解J0的過程可以畫出等值線,同時L1正則化的函數L也可以在w1w2的二維平面上畫出來。
如下圖:
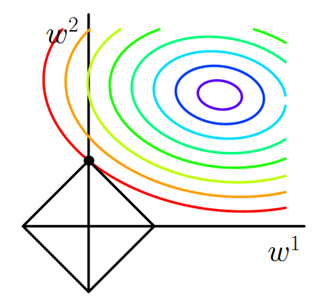
圖中等值線是J0的等值線,黑色方形是L函數的圖形。
在圖中,當J0等值線與LL圖形首次相交的地方就是最優解。上圖中J0與L在L的一個頂點處相交,這個頂點就是最優解。注意到這個頂點的值是(w1,w2)=(0,w)。可以直觀想象,因為L函數有很多『突出的角』(二維情況下四個,多維情況下更多),J0與這些角接觸的機率會遠大于與L其它部位接觸的機率,而在這些角上,會有很多權值等于0,這就是為什么L1正則化可以產生稀疏模型,進而可以用于特征選擇。
而正則化前面的系數α,可以控制L圖形的大小。α越小,L的圖形越大(上圖中的黑色方框);α越大,L的圖形就越小,可以小到黑色方框只超出原點范圍一點點,這是最優點的值(w1,w2)=(0,w)中的w可以取到很小的值。
類似,假設有如下帶L2正則化的損失函數:
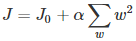
同樣可以畫出他們在二維平面上的圖形,如下:
二維平面下L2正則化的函數圖形是個圓,與方形相比,被磨去了棱角。因此J0與L相交時使得w1或w2等于零的機率小了許多,這就是為什么L2正則化不具有稀疏性的原因。
PRML一書對這兩個圖是這么解釋的

上圖中的模型是線性回歸,有兩個特征,要優化的參數分別是w1和w2,左圖的正則化是L2,右圖是L1。藍色線就是優化過程中遇到的等高線,一圈代表一個目標函數值,圓心就是樣本觀測值(假設一個樣本),半徑就是誤差值,受限條件就是紅色邊界(就是正則化那部分),二者相交處,才是最優參數。
可見右邊的最優參數只可能在坐標軸上,所以就會出現0權重參數,使得模型稀疏。
L2正則化和過擬合
擬合過程中通常都傾向于讓權值盡可能小,最后構造一個所有參數都比較小的模型。因為一般認為參數值小的模型比較簡單,能適應不同的數據集,也在一定程度上避免了過擬合現象。
可以設想一下對于一個線性回歸方程,若參數很大,那么只要數據偏移一點點,就會對結果造成很大的影響;但如果參數足夠小,數據偏移得多一點也不會對結果造成什么影響,專業一點的說法是『抗擾動能力強』。
那為什么L2正則化可以獲得值很小的參數?
以線性回歸中的梯度下降法為例。假設要求的參數為θ,hθ(x)是我們的假設函數,那么線性回歸的代價函數如下:

那么在梯度下降法中,最終用于迭代計算參數θ的迭代式為:
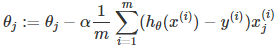
其中α是learning rate. 上式是沒有添加L2正則化項的迭代公式,如果在原始代價函數之后添加L2正則化,則迭代公式會變成下面的樣子:
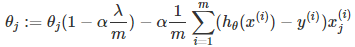
其中λ就是正則化參數。從上式可以看到,與未添加L2正則化的迭代公式相比,每一次迭代,θj都要先乘以一個小于1的因子,從而使得θj不斷減小,因此總得來看,θ是不斷減小的。
最開始也提到L1正則化一定程度上也可以防止過擬合。之前做了解釋,當L1的正則化系數很小時,得到的最優解會很小,可以達到和L2正則化類似的效果。
最后再補充一個角度:正則化其實就是對模型的參數設定一個先驗,這是貝葉斯學派的觀點。L1正則是laplace先驗,l2是高斯先驗,分別由參數sigma確定。在數據少的時候,先驗知識可以防止過擬合。
舉兩個最簡單的例子。
1 拋硬幣,推斷正面朝上的概率。如果只能拋5次,很可能5次全正面朝上,這樣你就得出錯誤的結論:正面朝上的概率是1--------過擬合!如果你在模型里加正面朝上概率是0.5的先驗,結果就不會那么離譜。這其實就是正則。
2. 最小二乘回歸問題:加L2范數正則等價于加了高斯分布的先驗,加L1范數正則相當于加拉普拉斯分布先驗。