媲美Pandas的數(shù)據(jù)分析工具包Datatable
前言
Data.table 是 R 中一個非常通用和高性能的包,使用簡單、方便而且速度快,在 R 語言社區(qū)非常受歡迎,每個月的下載量超過 40 萬,有近 650 個 CRAN 和 Bioconductor 軟件包使用它。如果你是 R 的使用者,可能已經(jīng)使用過 data.table 包。
而對于 Python 用戶,同樣存在一個名為 datatable 包,專注于大數(shù)據(jù)支持、高性能內(nèi)存/內(nèi)存不足的數(shù)據(jù)集以及多線程算法等問題。在某種程度上,datatable 可以被稱為是 Python 中的 data.table。
Datatable簡介
為了能夠更準(zhǔn)確地構(gòu)建模型,現(xiàn)在機(jī)器學(xué)習(xí)應(yīng)用通常要處理大量的數(shù)據(jù)并生成多種特征,這已成為必要的。而 Python 的 datatable 模塊為解決這個問題提供了良好的支持,以可能的最大速度在單節(jié)點機(jī)器上進(jìn)行大數(shù)據(jù)操作 (最多100GB)。datatable 包的開發(fā)由 H2O.ai 贊助,它的第一個用戶是 Driverless.ai。
2.1 安裝
- Mac OS系統(tǒng)
- Linux系統(tǒng)
安裝過程需要通過二進(jìn)制分布來實現(xiàn)
很遺憾的是,目前 datatable 包還不能在 Windows 系統(tǒng)上工作,但 Python 官方也在努力地增加其對 Windows 的支持。更多的信息可以查看 Build instructions 的說明。
https://datatable.readthedocs.io/en/latest/install.html
2.2 數(shù)據(jù)讀取
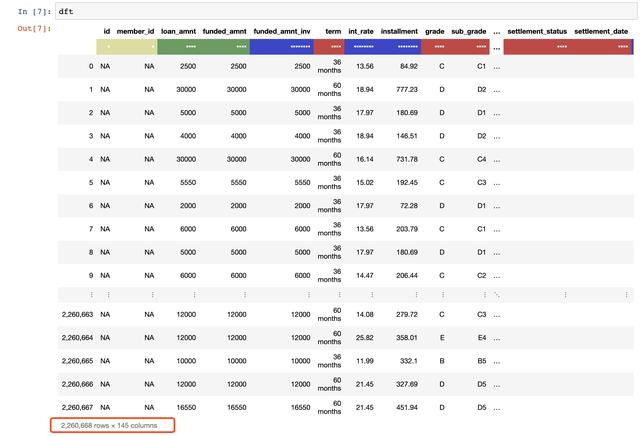
這里使用的數(shù)據(jù)集是來自 Kaggle 競賽中的 Lending Club Loan Data 數(shù)據(jù)集, 該數(shù)據(jù)集包含2007-2015期間所有貸款人完整的貸款數(shù)據(jù),即當(dāng)前貸款狀態(tài) (當(dāng)前,延遲,全額支付等) 和最新支付信息等。整個文件共包含226萬行和145列數(shù)據(jù),數(shù)據(jù)量規(guī)模非常適合演示 datatable 包的功能。
數(shù)據(jù)集:
- 首先將數(shù)據(jù)加載到 Frame 對象中,datatable 的基本分析單位是 Frame,這與Pandas DataFrame 或 SQL table 的概念是相同的:即數(shù)據(jù)以行和列的二維數(shù)組排列展示。
使用datatable讀取數(shù)據(jù)
這個數(shù)據(jù)集一共226萬行,145列,將近1.2G的數(shù)據(jù),通過datatable讀取只用了2.54s
如上所示,fread() 是一個強(qiáng)大又快速的函數(shù),能夠自動檢測并解析文本文件中大多數(shù)的參數(shù),所支持的文件格式包括 .zip 文件、URL 數(shù)據(jù),Excel 文件等等。此外,datatable 解析器具有如下幾大功能:
- 能夠自動檢測分隔符,標(biāo)題,列類型,引用規(guī)則等。
- 能夠讀取多種文件的數(shù)據(jù),包括文件,URL,shell,原始文本,檔案和 glob 等。
- 提供多線程文件讀取功能,以獲得最大的速度。
- 在讀取大文件時包含進(jìn)度指示器。
- 可以讀取 RFC4180 兼容和不兼容的文件。
- 使用pandas讀取數(shù)據(jù)
!!!注意:由于數(shù)據(jù)量過大,使用pandas讀取數(shù)據(jù)會經(jīng)常使服務(wù)掛機(jī),所以可以使用數(shù)據(jù)量稍小的數(shù)據(jù)集來測試
由此可以看出,結(jié)果表明在讀取大型數(shù)據(jù)時 datatable 包的性能明顯優(yōu)于 Pandas,Pandas 需要接近30秒的時間來讀取這些數(shù)據(jù),而 datatable 只需要2秒多。
2.3 幀轉(zhuǎn)換 (Frame Conversion)
對于當(dāng)前存在的幀,可以將其轉(zhuǎn)換為一個 Numpy 或 Pandas dataframe 的形式,如下所示:
下面,將 datatable 讀取的數(shù)據(jù)幀轉(zhuǎn)換為 Pandas dataframe 形式,并比較所需的時間,如下所示:
由于 Lending Club Loan Data 數(shù)據(jù)集的數(shù)據(jù)量過大,使用to_padnas操作,jupyte服務(wù)容易掛機(jī),所以使用一個數(shù)據(jù)集較小的進(jìn)行測試。
通過datatable讀取數(shù)據(jù)加上將其轉(zhuǎn)換為DataFrame數(shù)組,一共是2.62ms.
單通過pandas讀取數(shù)據(jù),總共需要14.4ms。
看起來將文件作為一個 datatable frame 讀取,然后將其轉(zhuǎn)換為 Pandas dataframe比直接讀取 Pandas dataframe 的方式所花費(fèi)的時間更少。因此,通過 datatable 包導(dǎo)入大型的數(shù)據(jù)文件再將其轉(zhuǎn)換為 Pandas dataframe 的做法是個不錯的主意。
2.4 幀的基礎(chǔ)屬性
下面來介紹 datatable 中 frame 的一些基礎(chǔ)屬性,這與 Pandas 中 dataframe 的一些功能類似。
也可以通過使用 head 命令來打印出輸出的前 n 行數(shù)據(jù),如下所示:
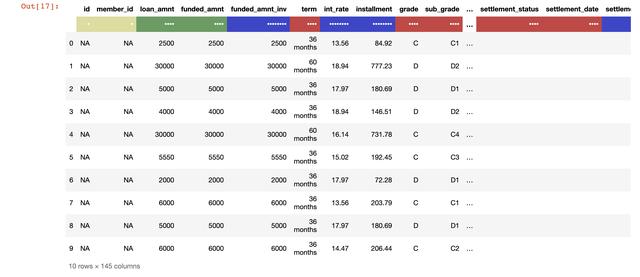
注意:這里用顏色來指代數(shù)據(jù)的類型,其中紅色表示字符串,綠色表示整型,而藍(lán)色代表浮點型。
2.5 統(tǒng)計總結(jié)
在 Pandas 中,總結(jié)并計算數(shù)據(jù)的統(tǒng)計信息是一個非常消耗內(nèi)存的過程,但這個過程在 datatable 包中是很方便的。如下所示,使用 datatable 包計算以下每列的統(tǒng)計信息:
下面分別使用 datatable 和Pandas 來計算每列數(shù)據(jù)的均值,并比較二者運(yùn)行時間的差異。
- Datatable讀取
- Pandas讀取
使用 Pandas 計算時拋出內(nèi)存錯誤的異常。
數(shù)據(jù)操作
和 dataframe 一樣,datatable 也是柱狀數(shù)據(jù)結(jié)構(gòu)。在 datatable 中,所有這些操作的主要工具是方括號,其靈感來自傳統(tǒng)的矩陣索引,但它包含更多的功能。諸如矩陣索引,C/C++,R,Pandas,Numpy 中都使用相同的 DT[i,j] 的數(shù)學(xué)表示法。下面來看看如何使用 datatable 來進(jìn)行一些常見的數(shù)據(jù)處理工作。
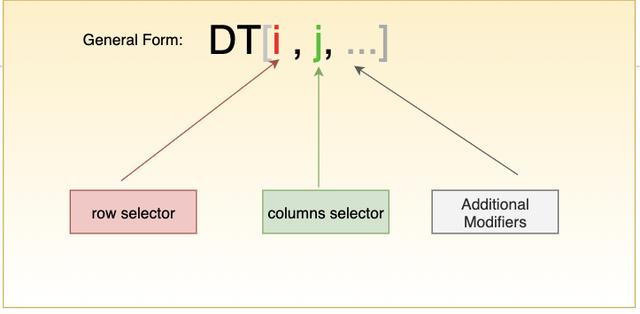
選擇行/列的子集
下面的代碼能夠從整個數(shù)據(jù)集中篩選出所有行及 funded_amnt 列:
展示如何選擇數(shù)據(jù)集中前5行3列的數(shù)據(jù),如下所示:
幀排序
- datatable 排序
在 datatable 中通過特定的列來對幀進(jìn)行排序操作,如下所示:
- Pandas 排序
可以看到兩種包在排序時間方面存在明顯的差異。
- 刪除行/列
下面展示如何刪除 member_id 這一列的數(shù)據(jù):
- 分組 (GroupBy)
與 Pandas 類似,datatable 同樣具有分組 (GroupBy) 操作。下面來看看如何在 datatable 和 Pandas 中,通過對 grade 分組來得到 funded_amout 列的均值:
- datatable 分組
- pandas 分組
.f 代表什么
在 datatable 中,f 代表 frame_proxy,它提供一種簡單的方式來引用當(dāng)前正在操作的幀。在上面的例子中,dt.f 只代表 dt_df。
過濾行
在 datatable 中,過濾行的語法與GroupBy的語法非常相似。下面就來展示如何過濾掉 loan_amnt 中大于 funding_amnt 的值,如下所示。
保存幀
在 datatable 中,同樣可以通過將幀的內(nèi)容寫入一個 csv 文件來保存,以便日后使用。如下所示:
有關(guān)數(shù)據(jù)操作的更多功能,可查看 datatable 包的說明文檔
地址:https://datatable.readthedocs.io/en/latest/using-datatable.html
總結(jié)
在數(shù)據(jù)科學(xué)領(lǐng)域,與默認(rèn)的 Pandas 包相比,datatable 模塊具有更快的執(zhí)行速度,這是其在處理大型數(shù)據(jù)集時的一大優(yōu)勢所在。然而,就功能而言,目前 datatable 包所包含的功能還不如 pandas 完善。相信在不久的將來,不斷完善的 datatable 能夠更加強(qiáng)大。