本月你最值得關注的數據科學開源項目!
如果你參加過大型的數據科學家職位的面試,你就會發現候選人的背景各不相同,比如軟件工程、機器學習、金融、市場營銷等等,而且這些面試者基本都擁有一系列屬于自己的項目,盡管他可能在數據科學方面的經驗還不足。而招聘人員/經理一般也都很欣賞那些手頭有一兩個優秀開源項目的應聘者。
今天,和大家推薦6個優秀的開源的數據科學項目,對計算機視覺專家的需求每年都在穩步增長,作為一名數據科學專業人士,有很多事情要做,有很多東西要學。希望這6個開源項目對你有所幫助:
1、Few-Shot vid2vid
去年我偶然發現了視頻到視頻(vid2vid)合成的概念,并被它的有效性所震撼。vid2vid本質上是將一個語義輸入視頻轉換為一個超真實的視頻輸出。
但是目前這些vid2vid模型有兩個主要的限制
- 他們需要大量的訓練數據
- 這些模型很難推廣到訓練數據之外
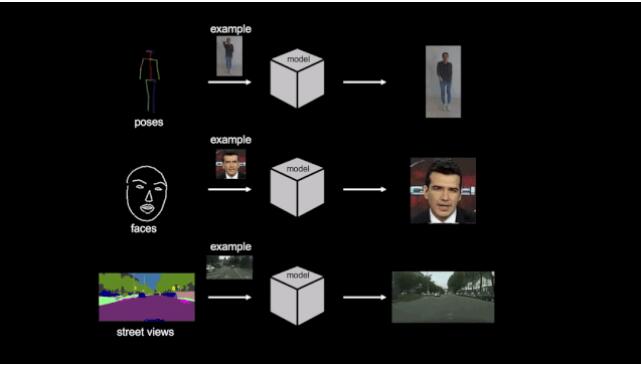
這就是英偉達viv2vid框架的厲害之處,它可以在分割蒙版、素描草圖、人體姿勢等多種輸入格式上,實現高分辨率、逼真、時間相干的視頻效果。

這個GitHub庫是一個PyTorch實現,你可以通過以下這篇文章,開始學習如何設計自己的視頻分類模型。(文章地址:https://www.analyticsvidhya.com/blog/2019/09/step-by-step-deep-learning-tutorial-video-classification-python/?utm_source=blog&utm_medium=6-open-source-data-science-projects)
Github地址:https://github.com/NVlabs/few-shot-vid2vid
2、Ultra-Light and Fast Face Detector
這是一個超輕版本的人臉檢測模型,這個人臉檢測模型的大小只有1MB。

該模型設計是針對邊緣計算設備或低算力設備(如用ARM推理)設計的,可以在低算力設備中如用ARM進行實時的通用場景的人臉檢測推理,同樣適用于移動端、PC。
Github地址:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
3、Gaussian_YOLOv3
我是自動駕駛汽車的超級粉絲,因此,我認為任何有關自動駕駛的框架或算法有新的發展都是值得令人開心的。
目標檢測算法是這些自動駕駛的核心,而高精度、快速的推理速度是保證駕駛安全的關鍵,那么,這個項目有哪些驚艷的特性呢?

Gaussian_YOLOv3架構提高了系統的檢測精度,支持實時操作,與傳統的YOLOv3相比,Gaussian YOLOv3分別將KITTI和Berkeley deep drive (BDD)數據集的平均精度(mAP)提高了3.09和3.5。
Github地址:https://github.com/jwchoi384/Gaussian_YOLOv3
4、T5
這個名單里怎么能少了谷歌的存在呢,谷歌在機器學習、深度學習和強化學習的研究上投入了大量的資金,他們的研究成果就反映了這一點,你也可以從他們的開源項目里學到很多知識。
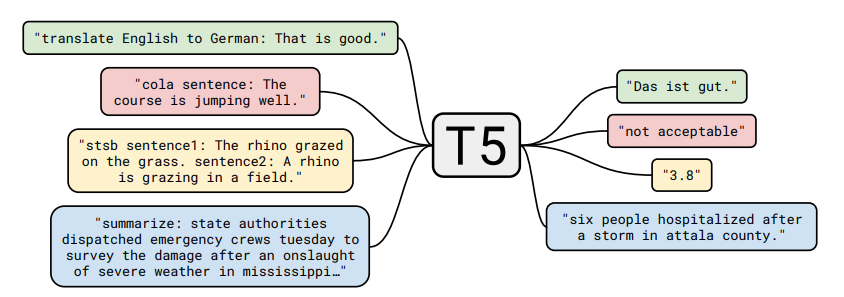
在T5這個GitHub存儲庫中,他們已經開源了數據集、預先訓練的模型和T5背后的代碼。谷歌提出預訓練模型 T5,參數量達到了 110 億,再次刷新 Glue 榜單,成為全新的 NLP SOTA 預訓練模型。NLP是目前最熱門的領域,如果你不想錯過它的最新成果,最好還是看看這個項目
Github地址:https://github.com/google-research/text-to-text-transfer-transformer
5、KnowledgeGraphData
史上最大規模1.4億中文知識圖譜開源下載,數據是.csv格式的。簡單地說知識圖譜就是通過關聯關系將知識組成網狀的結構,然后我們的人工智能可以通過這個圖譜來認識其代表的這一個現實事件,這個事件可以是現實,也可以是虛構的。

知識圖譜可以應用于機器人問答系統,知識推薦等等,下圖為知識圖譜在機器人上的應用。
Github地址:https://github.com/ownthink/KnowledgeGraphData
6、roughViz
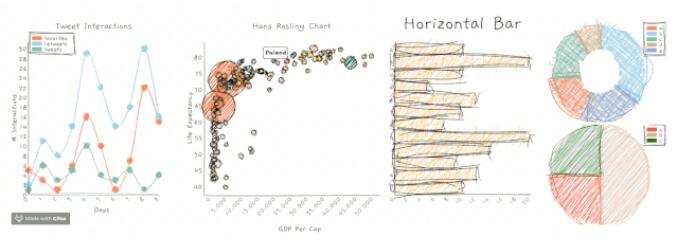
roughViz.js是可重用的JavaScript庫,基于D3v5,roughjs和handy,用于在瀏覽器中創建粗略/手繪樣式的圖表。
你可以使用下面的命令在你的機器上安裝roughViz:
- npm install rough-viz
你可以通過roughViz生成以下圖表:
- 條形圖
- 柱狀圖
- 折線圖
- 餅狀圖
- 散點圖
Github地址:https://github.com/jwilber/roughViz