













基于大數據企業網絡威脅發現模型實踐
關于企業安全威脅數據收集分析是一個系統工程,每天在我們網絡環境中,都會產生各種形式的威脅數據。為了網絡安全防護,會收集各種流量日志、審計日志、報警日志、上網設備日志,安防設備日志等等。很多公司都有自己的數據處理流程,大數據管理工具。我們根據過去的實踐經驗,總結出了一個威脅數據處理模型,因為引用增長黑客的模型的命名方式,我們稱這種模式為:沙漏式威脅信息處理模型。
網絡環境下構建的安全發現設備或服務,其主要的作用是,增加我方的防御厚度,減緩攻方的攻速,能通過足夠厚的防御措施,在攻方攻破之前發現威脅,殘血堅持到最后等回血,并且提醒友方人員的服務不要輕易送人頭。
一、沙漏威脅處理模型
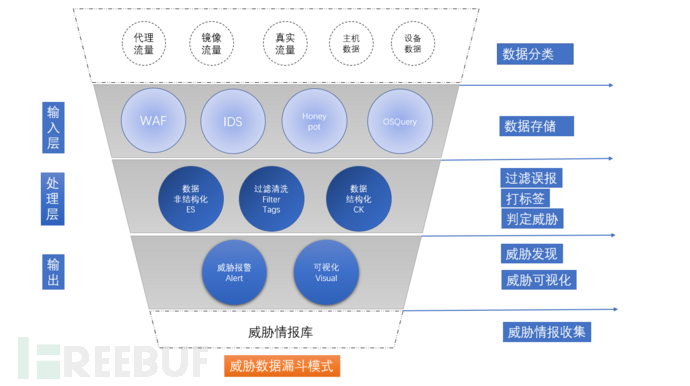
圖1.威脅分析沙漏模型
威脅數據組織:
我們參考軟件設計模式、神經網絡層、增長黑客模型的歸納方法,歸納出一個威脅數據處理模型。通過這個模型,可以看出數據收集、處理、展現基本流程脈絡,根據自己的實際需求情況,精簡模型或是擴展模型,來夠建我們的防御系統。
下面我們根據實際情況,概況出一個基本的模型,由若干層和多種元素構成。一個綜合威脅信息聚合模型,像一個軟件系統服務一樣, 有輸入層、處理層、輸出層。輸入層的數據源來自不同的分類數據類型:代理流量、鏡像流量、真實流量、主機數據、設備數據、掃描數據等等。
通過收集不同級別的威脅信息數據碎片,根據威脅信息碎片類型分類、價值權重級別、數據的屬性。將低信息量的威脅信息數據碎片,用信息化手段升級。將不同屬性的數據碎片組合,提升威脅發現能力。
- 代理流量:代理是一種概括的統稱,很多企業都有網關設備,7層或4層,這種設備服務會產生流相關量日志數據,并具有準入認證的功能。
- 鏡像流量:鏡像流量比較常見,通過流量鏡像發給威脅分析設備與分析服務,設備系統反饋威脅檢測報警。
- 真實流量:Nginx日志, 蜜罐日志等真實服務的流量數據產生的落地日志信息。
- 主機數據:無論是探針APM、Zabbix Agent、OSQuery、HIDS都會產生與主機相關的指標數據, 這些數據異常閥值同樣能起動預示報警的作用。
- 設備數據:重要敏感設備產生的數據, 這數據有自己的異常數據監控。
- 掃描數據:主動掃描采集的數據:端口、服務掃描等。
層次劃分:
第一層:輸入層(數據集中):在輸入層出現了以上提到的各種服務、設備產生的數據。這一層關鍵點是數據的收集,如果沒有數據的收集,后續的橫向和垂直的分析工作都無數據可分析處理。
第二層:處理層(數據加工):數據只是收集而不處理,只是一種數據的堆砌。在數據處理層做了幾件事情,
- 比如數據的快速非格式化。(切割)
- 后期數據聚類統計提純的結構化。(整形)
- 數據清洗過濾與打標簽。(加工)
威脅情報數據可以有多種形態,基于流數據形式的信息,比較適合使用管道處理模式,在管道處理模式,根據不同的信息數據輸入,在處理槽中,采用部署不同的數據處理技能單元。
裝備、技能:
第三層:輸出層(威脅發現):對數據進行去偽存真后,根據被打過的標簽進行策略分析落地,最后根據策略分析產出威脅信息數據。根據安全規則進行報警信息推送。對加工好的威脅數據,進行統計展示給用戶。
為什么采用漏斗的方式表達這種模型,因為威脅情報,去誤報的過程,整體就是過濾信息的過程,威脅信息由多變少的,逐漸的減少誤報。最后將過濾后的威脅情報進行匯總,積累成區域型威脅情報庫,不斷的更新迭代。
二、安全角色分工
安全運維人員當面對如此之多的日志數據時,如何組織這些數據,在這些數據當中發現有價值的信息,是一件很多挑戰的事情,不同的人在整個威脅發現系統構建的過程中擔當不同的角色。
每一種職業種類,都有自己特長的和弱點,在某些場景下工作,有人適合在對抗路,有人適合在后期發力。各種職業人對威脅信息碎片組合不一樣,不同威脅碎片信息的屬性,不同的職業有不同的解讀和運用。
- 安全運維:對于安全維護相關人員來說,最喜歡的體驗是,將每天產生的原始威脅數據情報當中的可疑信息,選最重要與危害最大的問題進行優先報警,并找到相關責任人推送報警信息。安全運維人員,需要不斷的迭代制作安全策略與報警規則。
- 數據運維:將各種可見的威脅信息日志,進行整理集中,運用各種大數據工具,將數據進行合理的存儲,保證數據完整性、有效性。
- 安全開發:提供操作界面,都所有可用的日志數據,提供查詢界面,查詢接口,完成信息查詢交互。
- 大數據算法:AI分析是安全分析的大腦。安全威脅發的方式方法有很多的種類,比如DNS解析相關、僵尸網絡相關、 WEB相關的,比如:XSS反射、SQL注入等等。
面一種同一種威脅事件數據,有多種檢測方法,比如針對 SQL注意和XSS注入這種威脅的發現方式就有:
- 基于正則匹配。
- 基于SQL Injection模式配對。
- 基于自然語言處理算法。
- 基于神經網絡算法。
同樣是神經網絡,使用的具體算法不同,樣本不同,效果也不同, 比如:LSTM、MLP等。
有開源的檢測軟件,有商業軟件都具備威脅分析報警的功能,可以作為平時網絡環境中檢測威脅事件的手段。商業軟件的威脅分析過程是黑盒完成,用戶看不到具體威脅實現的方法策略,屬于產品核心的一部分。并且,無論是商業軟件,還是開源軟件都存在誤報的情況的,還有漏報的情況。針對這種情況,在實踐過程,我們采用相應方法處理。
為了強化某些防御技能,加厚防御,有時需要疊加防御裝備,而疊加的防御裝備又不能千篇一律,可以根據不同的攻擊類型,在增加防御的同時,有減速的攻擊防御手段,有迷惑眩暈的對方的防御手段,有終結阻斷的對方攻擊的防御手段,有抵抗對方挖礦控制快速脫離受控的手段,等等。
1. 過濾:交叉檢查(垂直)
疊加檢測分析裝備與服務,提取頭部信息,是為了盡量的消除誤報。
舉例來說,我們能通過流量鏡像的方式,將網絡中的一部分流量,導入某個威脅分析系統,分析系統會為我們產生各種類型的報警信息,但是,報警信息是會存在誤報的。我們就可以用冗余威脅手段多次,對同一個威脅信息,進行威脅重疊判斷,降低誤報。
比如,我們可以對于基于正則模式匹配XSS分析結果,再用自然語言處理的方式進行確認,也可以對基于自然語言處理的報警,通過神經網絡算法,或是開源威脅分析庫的方式多次分析,通過交叉檢查的方式,進行誤報過濾,交叉檢查是對威脅信息多重檢查,疊加確認的過程。
因為每種威脅分析都可能會產生誤報,產生誤報疊加。這時候我們更應該關注的是,每種分析方法的頭部威脅分析結果。
2. 關聯:關聯檢查(橫向)
網絡環境中不只有一種監測手段存在,我們可以從不同的維度進行,對資產進行安全監控保護:
疊加堆砌威脅分析設備與服務,是為了提高發現的威脅準確率,減少漏報。有時會用多種不同的裝備在同一區域疊加使用,強化某一效果,A裝備效果不夠快,可以用B裝備。A看不見的,B可以看見。A不便于部署的,B可以便于部署。
舉例來說, 相同網絡環境:
- 第1種:流量監聽,我們可以會把相關某一區域的網絡流量,鏡像給網絡檢查分析模塊(開源商業),通過流量分析,分析出針對某臺服務操作的可疑流量數據,及威脅報警。
- 第2種:部署蜜罐,我們會在重要服務器所在環境部署蜜罐系統,通過蜜罐檢查當前網段的可疑行為。
- 第3種:加入審計監聽,我們可以對服務器安裝類似OSQuery這種主機審計組件,分析主機配置變化的可疑行為。
- 第4種:主動掃描,我們可以定時對服務器發起主動掃描,服務掃描和端口掃描,通過掃描返回結果,建立漏洞庫等相關情況,判斷主機是否異常。
- 第5種:訪問控制,我們可以建立服務主機的訪問控制,生成通信聚類的白名單與黑名單,分析異常訪問行為。
- 第6種:威脅情報庫,我們可以將訪問服務的IP與威脅情報庫進行對比,發現異常訪問行為。
橫向的威脅檢查方法可能還會很多,這里只是舉例一些。
他們都有一個公同之處:這些檢測分析服務都會產生,圍繞同一主體的威脅報警信息,所以對于同一IP主體,可以通過各種檢測手段,垂直確認后,再橫向與其它分析模塊的威脅數據進行比較。
威脅的確認,誤報的情況是可能發生的,但是如果多種檢測方式,都出現了威脅事件的發生,就降低了誤報的可能性,具體的控制細節需要實施者具體控制的。
比如:一臺機器,同時有掃描行為,還訪問敏感端口,還觸碰蜜罐,服務負載情況在異常時間發生異常變化,這一系列的操作,多個威脅事件同時指向一個主體,說明服務可能真的出現問題了。
如果用各種裝備來強化防御厚度,并且可靈活上下線, 可以終結控制,可以阻斷訪問,效果更佳。
三、實現工具技術棧
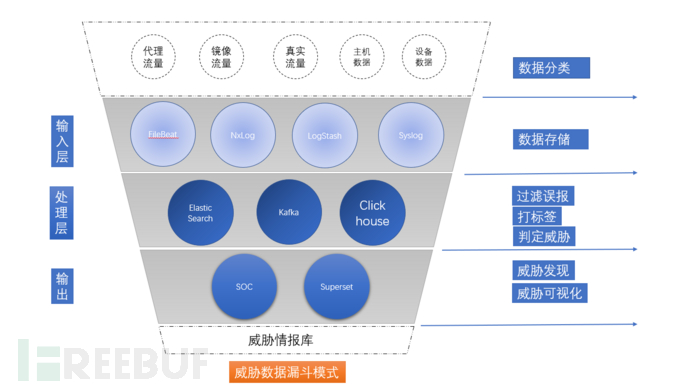
圖2.威脅分析沙漏模型(技術棧)
如果有多種檢查手段,我們一定有多種威脅情報的,從技術工具層面,我們如果管理這些數據,如何挖掘、利用、驅動這些數據是一個問題。
今天的開源社區變的異常的強大,可以用各種開源軟件,構建我們的安全檢測系統,大家使用有類似的技術棧、像ELK、Hadoop、Spark這種工具都非常的常見,大家使用的技術工具手段都非常常見。
- 實現技術:技術屬于技能屬性,不同職業人有著自己領域專屬的技能元素,人是技術技能的一種載體。
- 實現工具:工具是構建服務的武器,武器有不同的屬性。
威脅發現系統是一個漸進發展的過程,在時間線上,根據規模和發展的狀況不同,調用合適工具武器來達到自己奪標的目的,規模小的時候,發展初期,可以使用一般的統計工具就可以, ES單結點,Mysql數據,隨著規模和時間的發展, 適應大的數據量,就可以更重型的武器來解決,更復雜的需求。
ES單結點無法滿足就使用集群,一個集群不夠,使用多個集群。 MySQL不夠就用ClickHouse。
系統都是從小到大,不斷迭代的過程,數據也從單機到集群,從一個集群到多個集群。檢測系統、設備、日志格式都在不斷的積累增多,越變越復雜。但是基礎模式越來越清晰。
我們從實現的技術棧的角度分析具體使用過技術手段。
- 第一層.輸入層:對于數據輸入收集階段,各種各樣的數據收集手段都能利用上。filebeat、nxlog、logstash、syslog等,各種能便捷取得數據的手段都可以用,根據不同的平臺。
- 第二層.處理層:數據的處理之前是要對數據進行存儲的,不然也沒法分析數據。安全大數據中很重要的一點是數據緩存,解決輸入數據量過大,處理不過來的問題。ElasticSearch是現在最行的一種數據存儲方案之一,我們也不例外的使用的ES保存數據。
用ES一個很大的好處是,我們不用想使用關系型數據庫時先創建表結構,可快速想報警數據收集。對安全威脅數據來說,ES前期收集數據更快捷。高危的報警數據,理論上應該和交通數據不一樣,那么巨大的并發量,所以一般的ES就可以,另外ES本身可以擴展吞吐量。
我們對大量的日志數據驅動,還是比較擔心的,所以我們用了ClickHouse。ClickHouse相對于其它的大數據工具,上手更快,更輕量,但是效果速度確實相當的好。我們可以在Clickhouse對威脅進行打標簽。如果數據的級別沒有達到這個量,可以使用Mysql。其實ES同樣可以實現索引的SQL查詢。
- 第三層.輸出層: 數據準備就位以后,可以用各種手段分析、展示、報警數據,可能根據偏向技術棧,使用開源的解決方案,比如商業BI分析工具superset等。
沙漏模式就是將數據由多變少,人肉一天處理幾萬報警,是處理不過來的。
四、流模式威脅處理模型
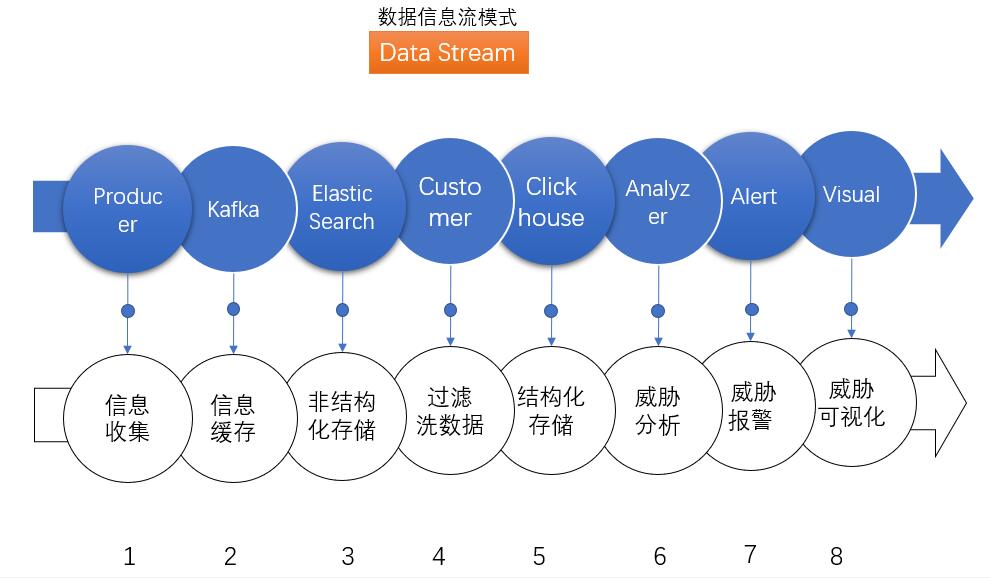
圖3.威脅分析處理流模型
威脅數據的湖泊海洋都是由一條條的數據河流匯聚而成的。在早期“數據流”模式,收集數據操作起來靈活方便。因為數據,無論是接入,還是存儲都不能一步到位的,采用增量的流模式數據處理比較適合。
各種信息數據,就像小河匯入湖泊一樣,積少成多,最后形成更大數據動勢,對于新的威脅檢查手段加入,靈活的新加入一條威脅信息數據流,流入到我們的數據池子中就好。
使用ES收集數據的幾個好處,如果結構化數據庫相關于“定長表”來說, ES的儲存是一種“變長表”,數據的“字段”可以靈活的增加或是減少。當輸入段的數據結構發生變化時,數據結構不用頻繁變更字段的定義,不用頻繁的修改表結構。利用這種靈活性,可以在這個階段對數據進行整形處理,數據的維護成本會降低。
采用 ClickHouse與MySQL數據庫是為了結構化查詢,能用SQL解決的問題,其實不用再多寫很多的腳本,可減少腳本編寫量,SQL本身可以當成很強大的DSL使用,對于主機審計應用OSQuery來說,支持SQL審計也是一種提高審計效率的方法。
五、威脅數據處理過濾模式(PULL、PUSH)
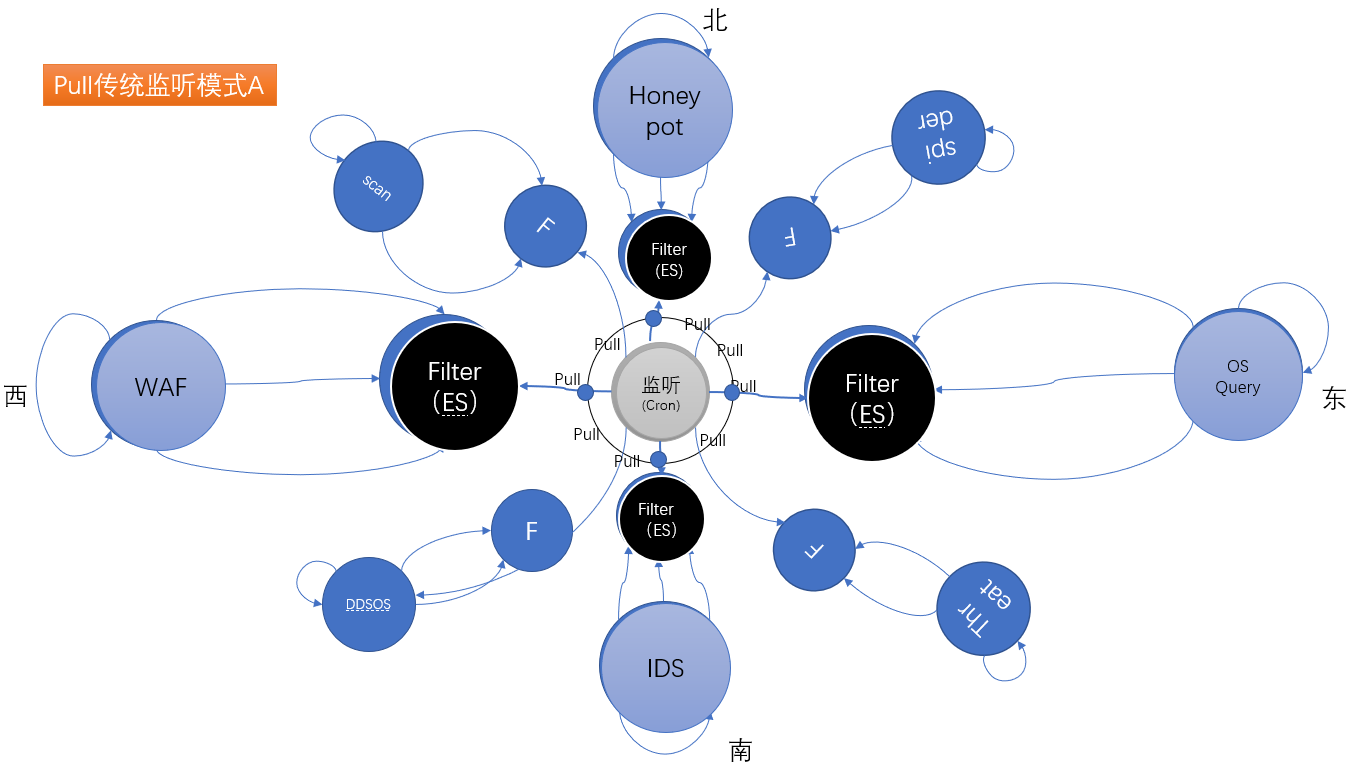
圖4.傳統威脅處理模型A
面對各種分類的海量數據,如何進行數據處理?
方法一個個針對性的處理。從歷史發展迭代出來,基本可以歸類的模式有2種,實際的威脅分析應用,本質上就是兩大操作:
- 單數據流的威脅垂直多重威脅判定確認。
- 多分析模塊間的威脅數據的橫向比較關聯。
1. A/B模式數據采集與威脅分析過程
- PULL模式:分析服務主動拉取各威脅分析模塊的威脅報警信息數據,集中監聽模式分析。需要把各種報警,分表異結構存儲。(多表異構)
- PUSH模式:各威脅過濾模塊,針對不同的報警進行垂直過濾后,將過濾后的數據
按同樣的結構推送到,集中的威脅數據表中。(單表同構)
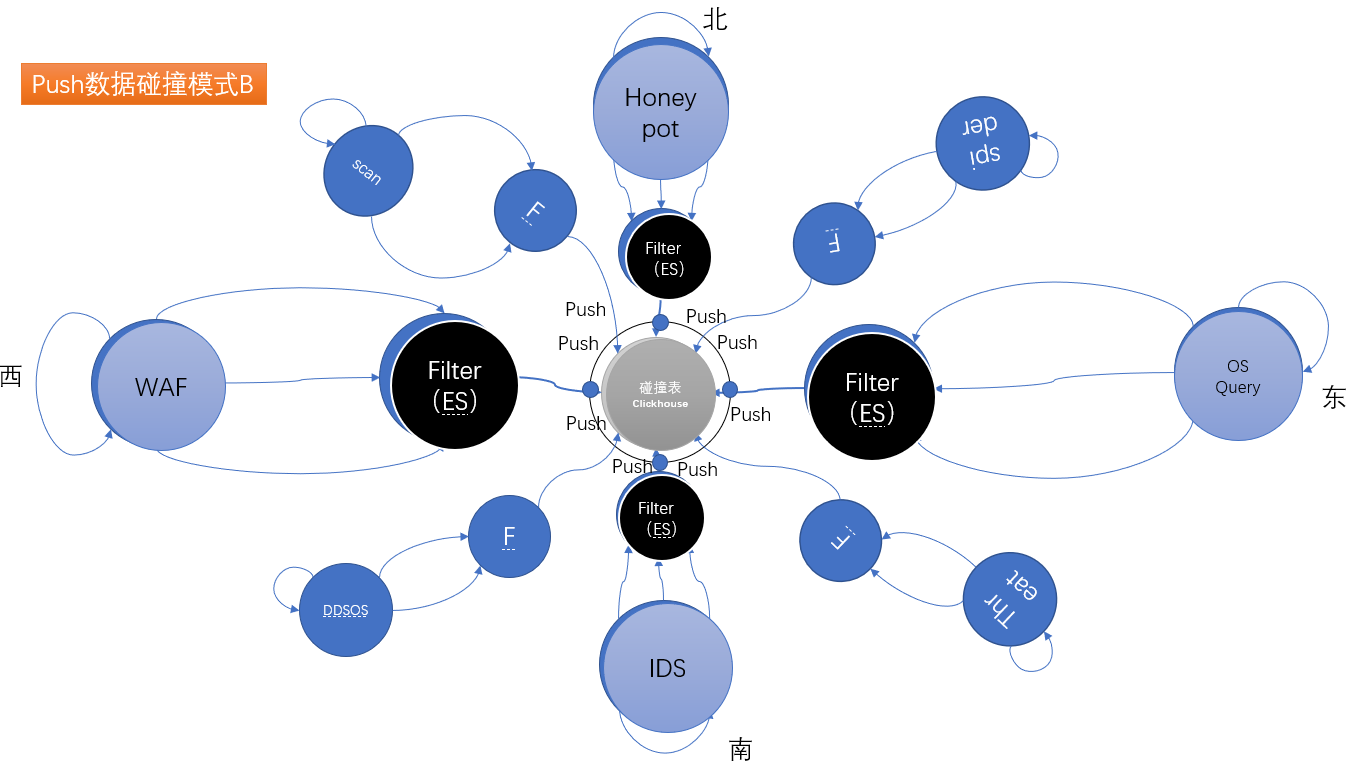 圖5.傳統威脅處理模型B
圖5.傳統威脅處理模型B
實際情況是, 威脅分析的模式這兩種情況是并存的。
隨著數據的集中處理工作的演進, 這種兩種模,最后混合成到了一起,只是不同的場景運用了不同有的分析模式。
2. A/B模式的優缺點對比
PULL處理模式:
- 優點:快速審計分析,PULL模式最快,不同分析模塊間的威脅數據互相不干擾,處理異構數據,操作很多關聯數據,但是對單威脅數據流審計,沒有那些關聯數據操作。
- 缺點:數據不集中,相對不利于統計,要進行各種SQL和腳本的關聯。
PUSH處理模式:
- 優點:如果單Stream數據流過濾之后,多準備一份數據處理,把報警威脅信息過濾后,本地存一份,在集中表中再存儲一份同構數據。之后統計威脅關聯,只操作一份數據就可以了,減少了關聯數據的多次操作。
- 缺點:威脅數據過于耦合。
六、碰撞表:威脅檢測模式
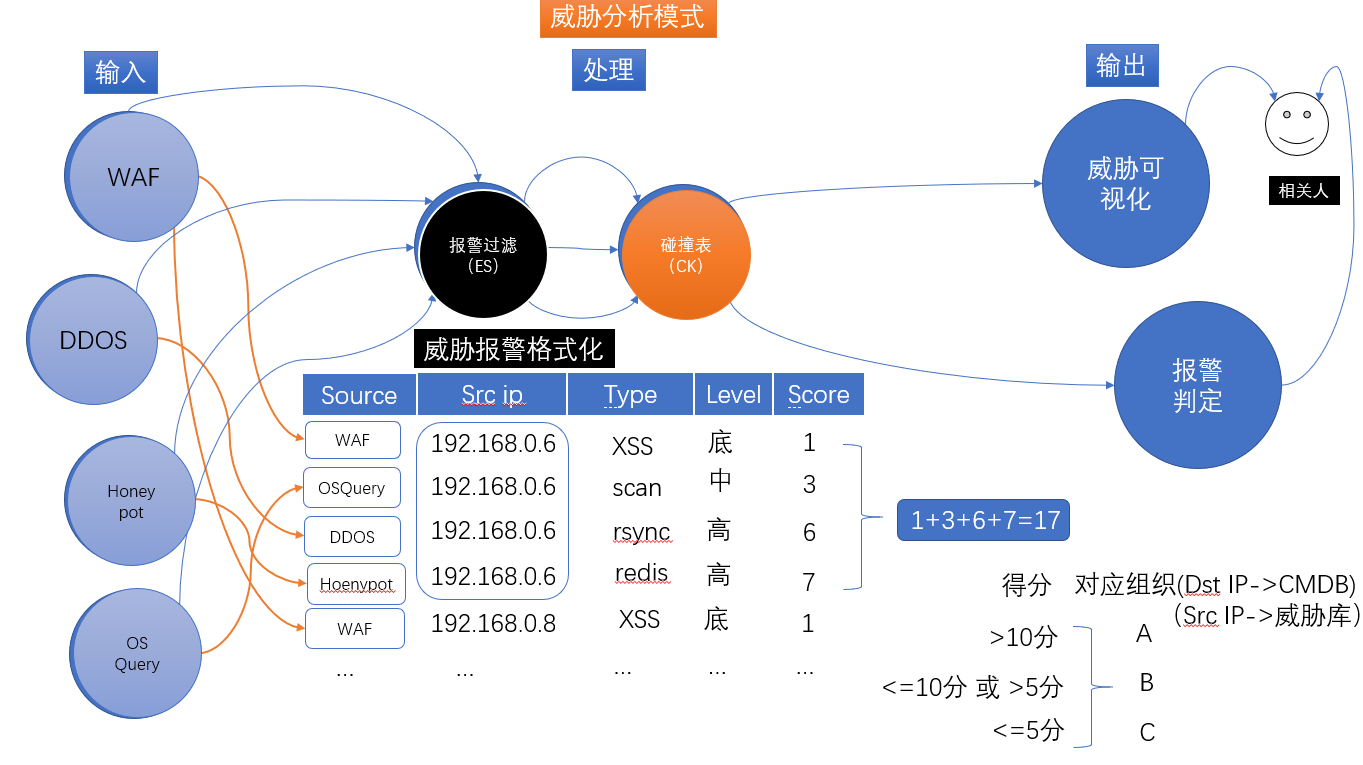
圖6.威脅分析碰撞表模型
如果我們采用了PUSH模式,將各種數據收集,我們就可以對不同標簽來源數據進行整合。在威脅數據被格式化之前,我們都是針對不同的威脅數據進行了一定程度的垂直過濾。然后把可能是真的威脅,放入我們的中心威脅情報表結構:
為了便于記憶,叫威脅比對模式為:碰撞表。
所謂碰撞表,就是能過建立一個統一屬性結構的威脅報警二維關系表,將不同設備和服務的報警數據集中存儲,根據威脅情報在表中,重復次數的多少,威脅等級的高低,綜合累計威脅事件的多寡,來判斷威脅的嚴重性。
簡單說,同一個IP有多個威脅事件發生的越多,并且情報源來自不同服務和設備,威脅越大。
PULL的模式是對數據進行關聯, 通 過腳本讀取結構數據關聯,通過表關聯。
而在PUSH處理模式下生成的集中碰撞表,是按威脅共通屬性進行威脅信息集中的,無論是什么類型的威脅那都是威脅,區別在于威脅級別和威脅分析有來源不一樣,如果我們在碰撞表中,發現同一個IP多次出現,來自不同的威脅分析模塊,而且威脅的級別還很高。各種威脅事件發生都這個IP相關,就需要關注一下這個IP。
我們對不同的威脅級別打分,并對同一IP累計分數,最后得出一個分數, 最后根據得分的高低,匹配不同的處理級別,報警級別。
攻擊者的情報,我們可以在積累的內外部威脅情報中, 尋找回溯歷史數據。被攻擊者的情報, 我們可以在CMDB資產系統中,找到資產對應的責任人。將爆破表中的威脅情報,進行分類、統計、可視化給安全運維人員做報警提示。
以上就是舉例說明,威脅信息能過沙漏威脅處理模型,進行威脅數據信息處理的一種策略舉例。
七、總結
不同規模的環境中:
- 輸入層:輸入源的收集數據信息的多寡,數據量大小。
- 處理層:對數據分析處理邏輯復雜程度。
- 輸出層:信息提示的多樣性。綜合起來決定的防護系統防護能力和構建成本。
過去我們在運用ES和ClickHouse大數據工具的實踐中,迭代演進,總結出了這種沙漏式的威脅處理模型,然后摸索出了一些共通性的內容,這篇沒有過多涉及到具體的代碼和工具使用方法。














