Kubernetes用了,延遲高了10倍,問題在哪?

當(dāng)我們團(tuán)隊(duì)將業(yè)務(wù)遷移至 Kubernetes 之后,一旦出現(xiàn)問題,總有人覺得“這是遷移之后的陣痛”,并把矛頭指向 Kubernetes,但最終事實(shí)證明犯錯(cuò)的并不是 Kubernetes。雖然文章并不涉及關(guān)于 Kubernetes 的突破性啟示,但我認(rèn)為內(nèi)容仍值得各位管理復(fù)雜系統(tǒng)的朋友借鑒。
近期,我所在的團(tuán)隊(duì)將一項(xiàng)微服務(wù)遷移到中央平臺(tái)。這套中央平臺(tái)捆綁有 CI/CD,基于 Kubernetes 的運(yùn)行時(shí)以及其他功能。這項(xiàng)演習(xí)也將作為先頭試點(diǎn),用于指導(dǎo)未來幾個(gè)月內(nèi)另外 150 多項(xiàng)微服務(wù)的進(jìn)一步遷移。而這一切,都是為了給西班牙的多個(gè)主要在線平臺(tái)(包括 Infojobs、Fotocasa 等)提供支持。
在將應(yīng)用程序部署到 Kubernetes 并路由一部分生產(chǎn)流量過去后,情況開始發(fā)生變化。Kubernetes 部署中的請(qǐng)求延遲要比 EC2 上的高出 10 倍。如果不找到解決辦法,不光是后續(xù)微服務(wù)遷移無法正常進(jìn)行,整個(gè)項(xiàng)目都有遭到廢棄的風(fēng)險(xiǎn)。
為什么 Kubernetes 中的延遲要遠(yuǎn)高于 EC2?
為了查明瓶頸,我們收集了整個(gè)請(qǐng)求路徑中的指標(biāo)。這套架構(gòu)非常簡單,首先是一個(gè) API 網(wǎng)關(guān)(Zuul),負(fù)責(zé)將請(qǐng)求代理至運(yùn)行在 EC2 或者 Kubernetes 中的微服務(wù)實(shí)例。在 Kubernetes 中,我們僅代表和 NGINX Ingress 控制器,后端則為運(yùn)行有基于 Spring 的 JVM 應(yīng)用程序的 Deployment 對(duì)象。
- EC2
- +---------------+
- | +---------+ |
- | | | |
- +-------> BACKEND | |
- | | | | |
- | | +---------+ |
- | +---------------+
- +------+ |
- ublic | | |
- -------> ZUUL +--+
- raffic | | | Kubernetes
- +------+ | +-----------------------------+
- | | +-------+ +---------+ |
- | | | | xx | | |
- +-------> NGINX +------> BACKEND | |
- | | | xx | | |
- | +-------+ +---------+ |
- +-----------------------------+
問題似乎來自后端的上游延遲(我在圖中以「xx」進(jìn)行標(biāo)記)。將應(yīng)用程序部署至 EC2 中之后,系統(tǒng)大約需要 20 毫秒就能做出響應(yīng)。但在 Kubernetes 中,整個(gè)過程卻需要 100 到 200 毫秒。
我們很快排除了隨運(yùn)行時(shí)間變化而可能出現(xiàn)的可疑對(duì)象。JVM 版本完全相同,而且由于應(yīng)用程序已經(jīng)運(yùn)行在 EC2 容器當(dāng)中,所以問題也不會(huì)源自容器化機(jī)制。另外,負(fù)載強(qiáng)度也是無辜的,因?yàn)榧词姑棵胫话l(fā)出 1 項(xiàng)請(qǐng)求,延遲同樣居高不下。另外,GC 暫停時(shí)長幾乎可以忽略不計(jì)。
我們的一位 Kubernetes 管理員詢問這款應(yīng)用程序是否具有外部依賴項(xiàng),因?yàn)?DNS 解析之前就曾引起過類似的問題,這也是我們目前找到的可能性最高的假設(shè)。
假設(shè)一:DNS 解析
在每一次請(qǐng)求時(shí),我們的應(yīng)用程序都像域中的某個(gè) AWS ElasticSearch 實(shí)例(例如 elastic.spain.adevinta.com)發(fā)出 1 到 3 條查詢。我們?cè)谌萜髦刑砑恿艘粋€(gè) shell,用于驗(yàn)證該域名的 DNS 解析時(shí)間是否過長。
來自容器的 DNS 查詢結(jié)果:
- [root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
- ;; Query time: 22 msec
- ;; Query time: 22 msec
- ;; Query time: 29 msec
- ;; Query time: 21 msec
- ;; Query time: 28 msec
- ;; Query time: 43 msec
- ;; Query time: 39 msec
來自運(yùn)行這款應(yīng)用程序的 EC2 實(shí)例的相同查詢結(jié)果:
- bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
- ;; Query time: 77 msec
- ;; Query time: 0 msec
- ;; Query time: 0 msec
- ;; Query time: 0 msec
- ;; Query time: 0 msec
前者的平均解析時(shí)間約為 30 毫秒,很明顯,我們的應(yīng)用程序在其 ElasticSearch 上造成了額外的 DNS 解析延遲。
但這種情況非常奇怪,原因有二:
- Kubernetes 當(dāng)中已經(jīng)包含大量與 AWS 資源進(jìn)行通信的應(yīng)用程序,而且都沒有出現(xiàn)延遲過高的情況。因此,我們必須弄清引發(fā)當(dāng)前問題的具體原因。
- 我們知道 JVM 采用了內(nèi)存內(nèi)的 DNS 緩存。從配置中可以看到,TTL 在 $JAVA_HOME/jre/lib/security/java.security 位置進(jìn)行配置,并被設(shè)置為 networkaddress.cache.ttl = 10。JVM 應(yīng)該能夠以 10 秒為周期緩存所有 DNS 查詢。
為了確認(rèn) DNS 假設(shè),我們決定剝離 DNS 解析步驟,并查看問題是否可以消失。我們的第一項(xiàng)嘗試是讓應(yīng)用程序直接與 ELasticSearch IP 通信,從而繞過域名機(jī)制。這需要變更代碼并進(jìn)行新的部署,即需要在 /etc.hosts 中添加一行代碼以將域名映射至其實(shí)際 IP:
- 34.55.5.111 elastic.spain.adevinta.com
通過這種方式,容器能夠以近即時(shí)方式進(jìn)行 IP 解析。我們發(fā)現(xiàn)延遲確實(shí)有所改進(jìn),但距離目標(biāo)等待時(shí)間仍然相去甚遠(yuǎn)。盡管 DNS 解析時(shí)長有問題,但真正的原因還沒有被找到。
網(wǎng)絡(luò)管道
我們決定在容器中進(jìn)行 tcpdump,以便準(zhǔn)確觀察網(wǎng)絡(luò)的運(yùn)行狀況。
- [root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap
我們隨后發(fā)送了多項(xiàng)請(qǐng)求并下載了捕捉結(jié)果(kubectl cp my-service:/capture.pcap capture.pcap),而后利用 Wireshark 進(jìn)行檢查。
DNS 查詢部分一切正常(少部分值得討論的細(xì)節(jié),我將在后文提到)。但是,我們的服務(wù)處理各項(xiàng)請(qǐng)求的方式有些奇怪。以下是捕捉結(jié)果的截圖,顯示出在響應(yīng)開始之前的請(qǐng)求接收情況。
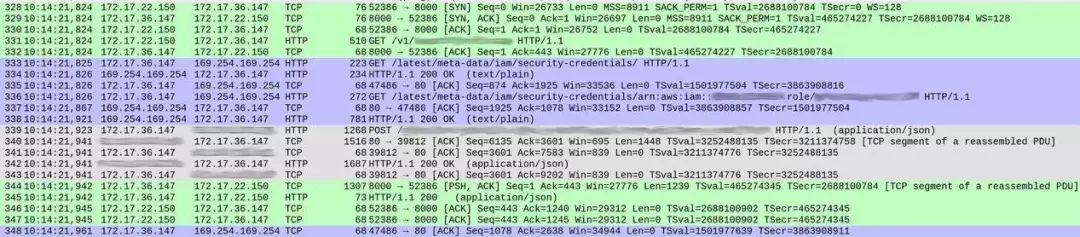
數(shù)據(jù)包編號(hào)顯示在第一列當(dāng)中。為了清楚起見,我對(duì)不同的 TCP 流填充了不同的顏色。
從數(shù)據(jù)包 328 開始的綠色部分顯示,客戶端(172.17.22.150)打開了容器(172.17.36.147)間的 TCP 連接。在最初的握手(328 至 330)之后,數(shù)據(jù)包 331 將 HTTP GET /v1/..(傳入請(qǐng)求)引向我們的服務(wù),整個(gè)過程耗時(shí)約 1 毫秒。
來自數(shù)據(jù)包 339 的灰色部分表明,我們的服務(wù)向 ElasticSearch 實(shí)例發(fā)送了 HTTP 請(qǐng)求(這里沒有顯示 TCP 握手,是因?yàn)槠涫褂迷?TCP 連接),整個(gè)過程耗費(fèi)了 18 毫秒。
到這里,一切看起來還算正常,而且時(shí)間也基本符合整體響應(yīng)延遲預(yù)期(在客戶端一側(cè)測(cè)量為 20 到 30 毫秒)。
但在兩次交換之間,藍(lán)色部分占用了 86 毫秒。這到底是怎么回事?在數(shù)據(jù)包 333,我們的服務(wù)向 /latest/meta-data/iam/security-credentials 發(fā)送了一項(xiàng) HTTP GET 請(qǐng)求,而后在同一 TCP 連接上,又向 /latest/meta-data/iam/security-credentials/arn:.. 發(fā)送了另一項(xiàng) GET 請(qǐng)求。
我們進(jìn)行了驗(yàn)證,發(fā)現(xiàn)整個(gè)流程中的每項(xiàng)單一請(qǐng)求都發(fā)生了這種情況。在容器內(nèi),DNS 解析確實(shí)有點(diǎn)慢(理由同樣非常有趣,有機(jī)會(huì)的話我會(huì)另起一文詳加討論)。但是,導(dǎo)致高延遲的真正原因,在于針對(duì)每項(xiàng)單獨(dú)請(qǐng)求的 AWS Instance Metadata Service 查詢。
假設(shè)二:指向 AWS 的流氓調(diào)用
兩個(gè)端點(diǎn)都是 AWS Instance Metadata API 的組成部分。我們的微服務(wù)會(huì)在從 ElasticSearch 中讀取信息時(shí)使用該服務(wù)。這兩條調(diào)用屬于授權(quán)工作的基本流程,端點(diǎn)通過第一項(xiàng)請(qǐng)求產(chǎn)生與實(shí)例相關(guān)的 IAM 角色。
- / # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
- arn:aws:iam::<account_id>:role/some_role
第二條請(qǐng)求則向第二個(gè)端點(diǎn)查詢實(shí)例的臨時(shí)憑證:
- / # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
- {
- "Code" : "Success",
- "LastUpdated" : "2012-04-26T16:39:16Z",
- "Type" : "AWS-HMAC",
- "AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
- "SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
- "Token" : "token",
- "Expiration" : "2017-05-17T15:09:54Z"
- }
客戶可以在短時(shí)間內(nèi)使用這些憑證,且端點(diǎn)會(huì)定期(在 Expiration 過期之前)檢索新憑證。這套模型非常簡單:出于安全原因,AWS 經(jīng)常輪換臨時(shí)密鑰,但客戶端可以將密鑰緩存幾分鐘,從而抵消檢索新憑證所帶來的性能損失。
照理來說,整個(gè)過程應(yīng)該由 AWS Java SDK 為我們處理。但不知道為什么,實(shí)際情況并非如此。搜索了一遍 GitHub 問題,我們從 #1921 當(dāng)中找到了需要的線索。
AWS SDK 會(huì)在滿足以下兩項(xiàng)條件之一時(shí)刷新憑證:
- Expiration 已經(jīng)達(dá)到 EXPIRATION_THRESHOLD 之內(nèi),硬編碼為 15 分鐘。
- 最后一次刷新憑證的嘗試大于 REFRESH_THRESHOLD,硬編碼為 60 分鐘。
我們希望查看所獲取憑證的實(shí)際到期時(shí)間,因此我們針對(duì)容器 API 運(yùn)行了 cURL 命令——分別指向 EC2 實(shí)例與容器。但容器給出的響應(yīng)要短得多:正好 15 分鐘。現(xiàn)在的問題很明顯了:我們的服務(wù)將為第一項(xiàng)請(qǐng)求獲取臨時(shí)憑證。由于有效時(shí)間僅為 15 分鐘,因此在下一條請(qǐng)求中,AWS SDK 會(huì)首先進(jìn)行憑證刷新,每一項(xiàng)請(qǐng)求中都會(huì)發(fā)生同樣的情況。
為什么憑證的過期時(shí)間這么短?
AWS Instance Metadata Service 在設(shè)計(jì)上主要適合 EC2 實(shí)例使用,而不太適合 Kubernetes。但是,其為應(yīng)用程序保留相同接口的機(jī)制確實(shí)很方便,所以我們轉(zhuǎn)而使用 KIAM,一款能夠運(yùn)行在各個(gè) Kubernetes 節(jié)點(diǎn)上的工具,允許用戶(即負(fù)責(zé)將應(yīng)用程序部署至集群內(nèi)的工程師)將 IAM 角色關(guān)聯(lián)至 Pod 容器,或者說將后者視為 EC2 實(shí)例的同等對(duì)象。其工作原理是攔截指向 AWS Instance Metadata Service 的調(diào)用,并利用自己的緩存(預(yù)提取自 AWS)及時(shí)接上。從應(yīng)用程序的角度來看,整個(gè)流程與 EC2 運(yùn)行環(huán)境沒有區(qū)別。
KIAM 恰好為 Pod 提供了周期更短的臨時(shí)憑證,因此可以合理做出假設(shè),Pod 的平均存在周期應(yīng)該短于 EC2 實(shí)例——默認(rèn)值為 15 分鐘。如果將兩種默認(rèn)值放在一起,就會(huì)引發(fā)問題。提供給應(yīng)用程序的每一份證書都會(huì)在 15 分鐘之后到期,但 AWS Java SDK 會(huì)對(duì)一切剩余時(shí)間不足 15 分鐘的憑證做出強(qiáng)制性刷新。
結(jié)果就是,每項(xiàng)請(qǐng)求都將被迫進(jìn)行憑證刷新,這使每項(xiàng)請(qǐng)求的延遲提升。接下來,我們又在 AWS Java SDK 中發(fā)現(xiàn)了一項(xiàng)功能請(qǐng)求,其中也提到了相同的問題。
相比之下,修復(fù)工作非常簡單。我們對(duì) KIAM 重新配置以延長憑證的有效期。在應(yīng)用了此項(xiàng)變更之后,我們就能夠在不涉及 AWS Instance Metadata Service 的情況下開始處理請(qǐng)求,同時(shí)返回比 EC2 更低的延遲水平。
總結(jié)
根據(jù)我們的實(shí)際遷移經(jīng)驗(yàn),最常見的問題并非源自 Kubernetes 或者該平臺(tái)其他組件,與我們正在遷移的微服務(wù)本身也基本無關(guān)。事實(shí)上,大多數(shù)問題源自我們急于把某些組件粗暴地整合在一起。
我們之前從來沒有復(fù)雜系統(tǒng)的整合經(jīng)驗(yàn),所以這一次我們的處理方式比較粗糙,未能充分考慮到更多活動(dòng)部件、更大的故障面以及更高熵值帶來的實(shí)際影響。
在這種情況下,導(dǎo)致延遲升高的并不是 Kubernetes、KIAM、AWS Java SDK 或者微服務(wù)層面的錯(cuò)誤決策。相反,問題源自 KIAM 與 AWS Java SDK 當(dāng)中兩項(xiàng)看似完全正常的默認(rèn)值。單獨(dú)來看,這兩個(gè)默認(rèn)值都很合理:AWS Java SDK 希望更頻繁地刷新憑證,而 KIAM 設(shè)定了較低的默認(rèn)過期時(shí)間。但在二者結(jié)合之后,卻產(chǎn)生了病態(tài)的結(jié)果。是的,各個(gè)組件能夠正常獨(dú)立運(yùn)行,并不代表它們就能順利協(xié)作并構(gòu)成更龐大的系統(tǒng)。