打包教你推薦系統的開源工具和框架
如果我們懂得了原理,知道了實際推薦系統需要考慮哪些元素之后,卻在你摩拳擦掌之際,發現要先從挖地基開始,你整個人可能是崩潰的。
輪子不要重復造
但是事實上你沒必要這樣做也不應該這樣做。大廠研發力量雄厚,業務場景復雜,數據量大,自己從挖地基開始研發自己的推薦系統則是非常常見的,然而中小廠職工們則要避免重復造輪子。這是因為下面的原因。
1、中小企業,或者剛剛起步的推薦系統,要達成的效果往往是基準線,通用的和開源的已經能夠滿足;
2、開源的輪子有社區貢獻,經過若干年的檢驗后,大概率上已經好于你自己從零開始寫一個同樣功能的輪子;
3、對于沒有那么多研發力量的廠來說,時間還是第一位的,先做出來,這是第一要義。
既然要避免重復造輪子,就要知道有哪些輪子。
有別于介紹一個籠統而大全的“推薦系統”輪子,我更傾向于把粒度和焦點再縮小一下,介于底層的編程語言 API 和大而全的”推薦系統”之間,本文按照本專欄的目錄給你梳理一遍各個模塊可以用到的開源工具。
這里順帶提一下,選擇開源項目時要優先選擇自己熟悉的編程語言、還要選有大公司背書的,畢竟基礎技術過硬且容易形成社區、除此之外要考慮在實際項目中成功實施過的公司、最后還要有活躍的社區氛圍。
內容分析
基于內容的推薦,主要工作集中在處理文本,或者把數據視為文本去處理。文本分析相關的工作就是將非結構化的文本轉換為結構化。主要的工作就是三類。
1、主題模型;
2、詞嵌入;
3、文本分類。
可以做這三類工作的開源工具有下面的幾種。
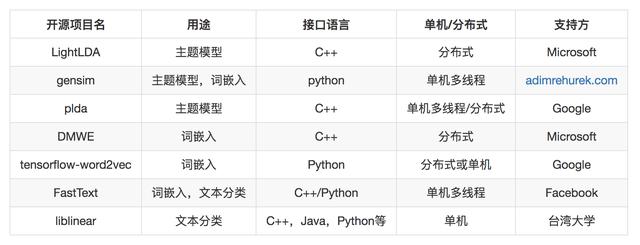
由于通常我們遇到的數據量還沒有那么大,并且分布式維護本身需要專業的人和精力,所以請慎重選擇分布式的,將單機發揮到極致后,遇到瓶頸再考慮分布式。
這其中 FastText 的詞嵌入和 Word2vec 的詞嵌入是一樣的,但 FastText 還提供分類功能,這個分類非常有優勢,效果幾乎等同于 CNN,但效率卻和線性模型一樣,在實際項目中久經考驗。LightLDA 和 DMWE 都是微軟開源的機器學習工具包。
協同過濾和矩陣分解
基于用戶、基于物品的協同過濾,矩陣分解,都依賴對用戶物品關系矩陣的利用,這里面常常要涉及的工作有下面幾種。
1、KNN 相似度計算;
2、SVD 矩陣分解;
3、SVD++ 矩陣分解;
4、ALS 矩陣分解;
5、BPR 矩陣分解;
6、低維稠密向量近鄰搜索。
可以做這些工作的開源工具有下面幾種。
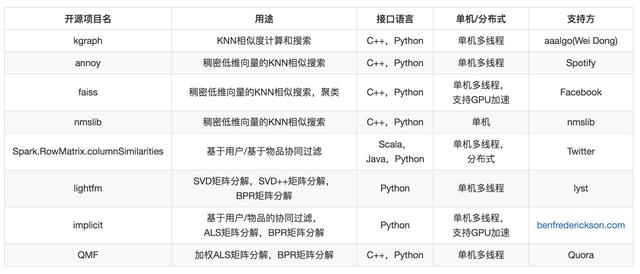
這里面的工作通常是這樣:基礎協同過濾算法,通過計算矩陣的行相似和列相似得到推薦結果。
矩陣分解,得到用戶和物品的隱因子向量,是低維稠密向量,進一步以用戶的低維稠密向量在物品的向量中搜索得到近鄰結果,作為推薦結果,因此需要專門針對低維稠密向量的近鄰搜索。
同樣,除非數據量達到一定程度,比如過億用戶以上,否則你要慎重選擇分布式版本,非常不劃算。
模型融合
模型融合這部分,有線性模型、梯度提升樹模型。
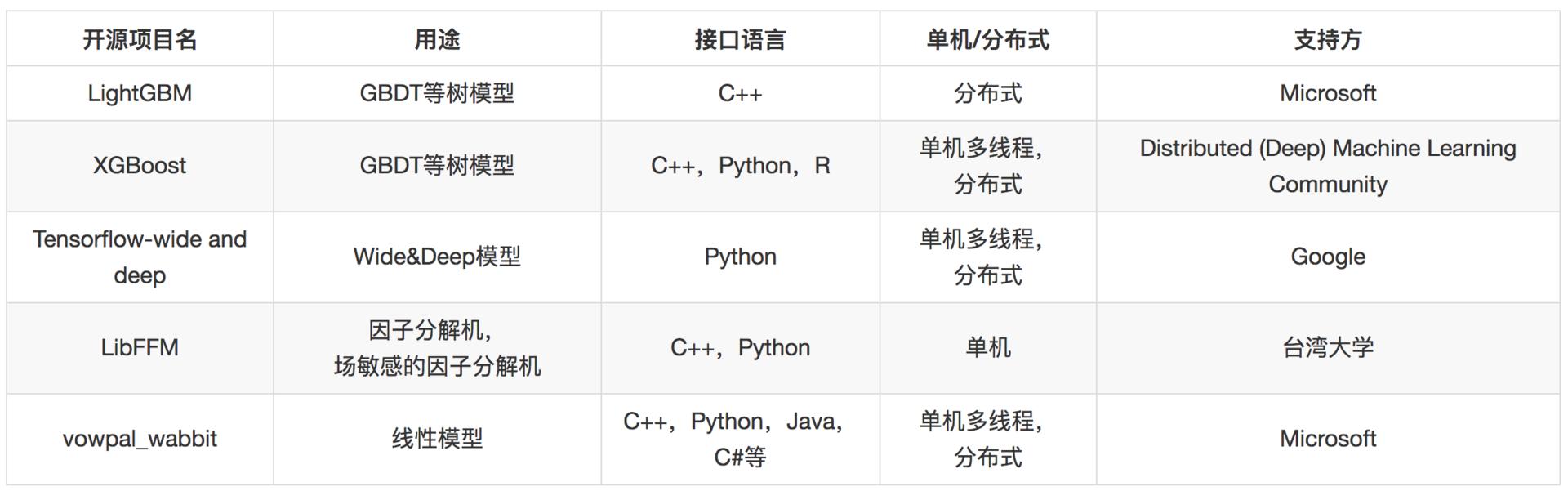
線性模型復雜在模型訓練部分,這部分可以離線批量進行,而線上預測部分則比較簡單,可以用開源的接口,也可以自己實現。
其他工具
Bandit 算法比較簡單,自己實現不難,這里不再單獨列舉。至于深度學習部分,則主要基于 TensorFlow 完成。
存儲、接口相關開源項目和其他互聯網服務開發一樣,也在對應章節文章列出,這里不再單獨列出了。
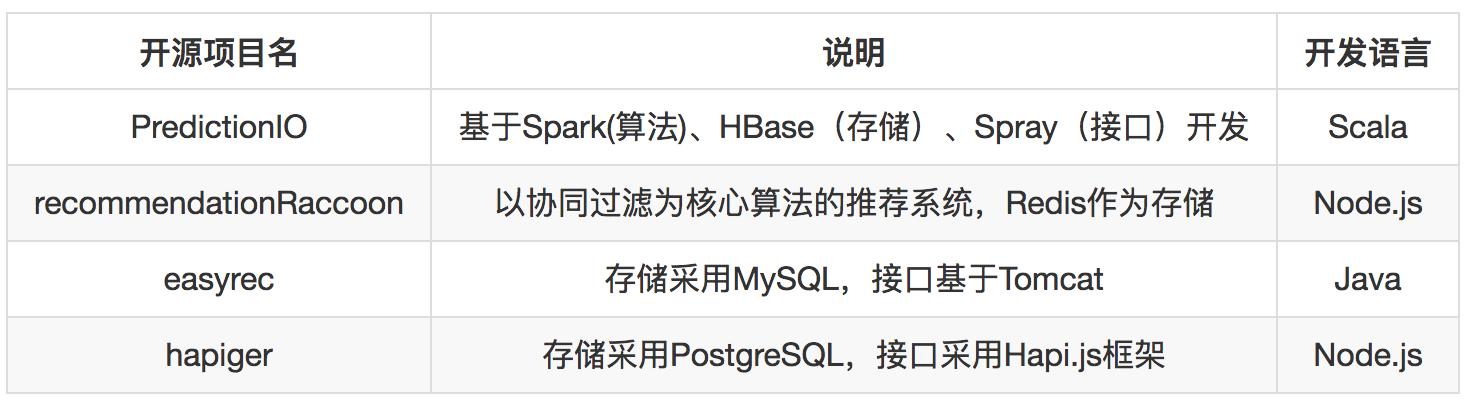
完整推薦系統
這里也梳理一下有哪些完整的推薦系統開源項目,可以作為學習和借鑒。 所謂完整的推薦系統是指:包含推薦算法實現、存儲、接口。
總結
你可能注意到了,這里的推薦系統算法部分以 Python 和 C++ 為主,甚至一些 Python 項目,底層也都是用 C++ 開發而成。
因此在算法領域,以 Python 和 C++ 作為開發語言會有比較寬泛的選擇范圍。
至于完整的推薦系統開源項目,由于其封裝過于嚴密,比自己將大模塊組合在一起要黑盒很多,因此在優化效果時,不是很理想,需要一定的額外學習成本,學習這個系統本身的開發細節,這個學習成本是額外的,不是很值得投入。
因此,我傾向于選擇各個模塊的開源項目,再將其組合集成為自己的推薦系統。這樣做的好處是有下面幾種。
1、單個模塊開源項目容易入手,學習成本低,性能好;
2、自己組合后更容易診斷問題,不需要的不用開發;
3、單個模塊的性能和效果更有保證。
當然,還是那句話,實際問題實際分析,也許你在你的情境下有其他考慮和選擇。