不考慮可運維性的數(shù)據(jù)庫選型都應(yīng)該槍斃
概要
1、從職業(yè)發(fā)展看選型
2、選型原則一二三
3、選型路線圖
本次分享主要有三個大的方向,一是從職業(yè)規(guī)劃的角度看為什么我會認為數(shù)據(jù)庫選型很重要,第二個方向會根據(jù)這些經(jīng)驗說說選型的基本原則是什么,最后總結(jié)一下這些年數(shù)據(jù)庫選型的路線圖,希望能對大家以后做數(shù)據(jù)庫選型時有幫助,可以根據(jù)你們公司的場景進行套用,當然這不一定適合所有場景,主要還是提供思路以方便大家借鑒。
一、從職業(yè)發(fā)展看選型
DBA這個行業(yè)有很多年了,隨著時間的變化職業(yè)規(guī)劃也有著不同的變化。我放了一張DB-Engine的圖,這是DB的排名,前三的就不說了,老三位沒什么可聊的。但是看下面的排名,除了常見的數(shù)據(jù)庫,還有ES、HBase、Neo4j這些我們之前不太認為是DBA管理范疇內(nèi)的DB。
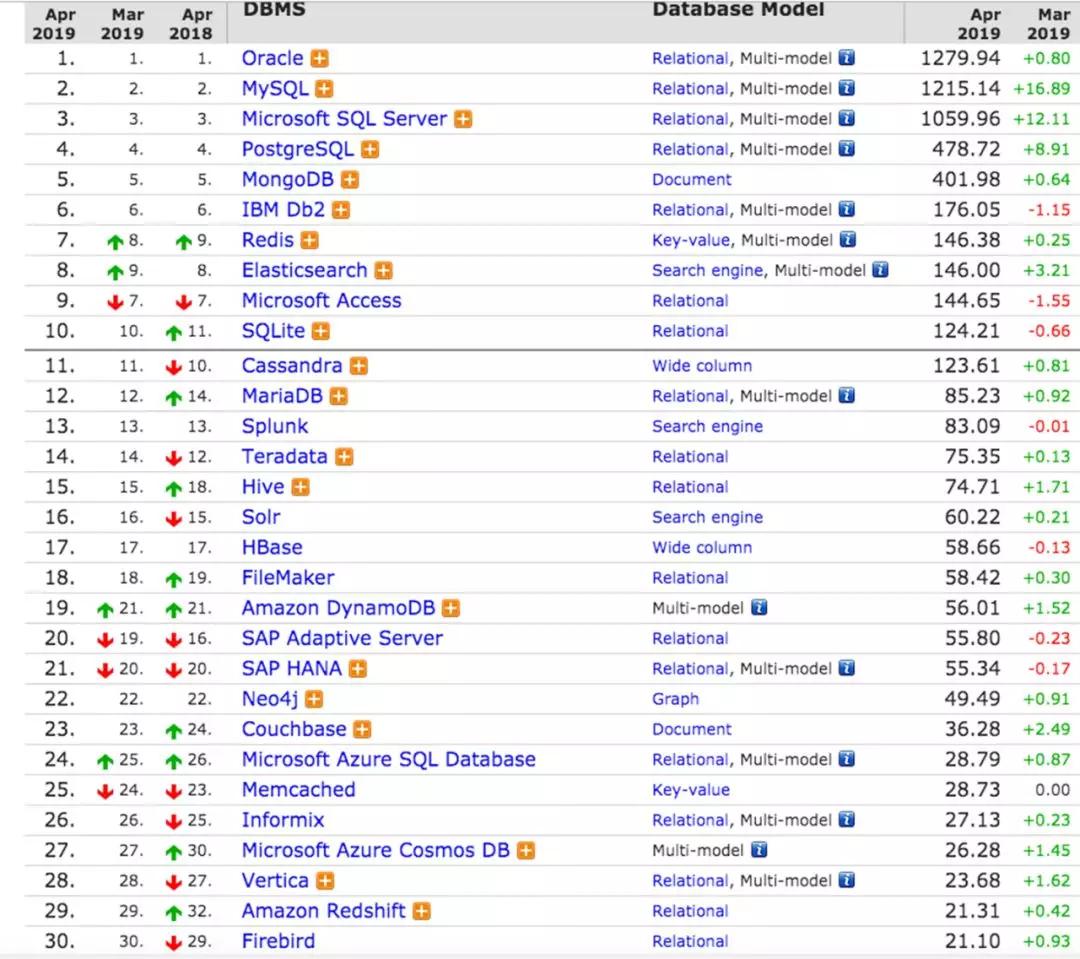
我經(jīng)常跟團隊小伙伴說咱們DBA的思維不要光局限于前面的老三位或者TOP5,我們是不是可以考慮到更多的數(shù)據(jù)庫也是DBA可以從事的行業(yè)。比如你可不可以做HBase?你可不可以管理ES?這些東西都體現(xiàn)在這張表里,我們可以擴展自己職業(yè)的領(lǐng)域,這也是職業(yè)發(fā)展方向的一種橫向擴展方式。
這張圖是我對比去年和今年變化的展示圖,去年關(guān)系型數(shù)據(jù)庫(藍色部分)占了半壁江山,今年關(guān)系型數(shù)據(jù)庫仍然是第一,但是已經(jīng)有很多份額被多用途的數(shù)據(jù)庫占去了。
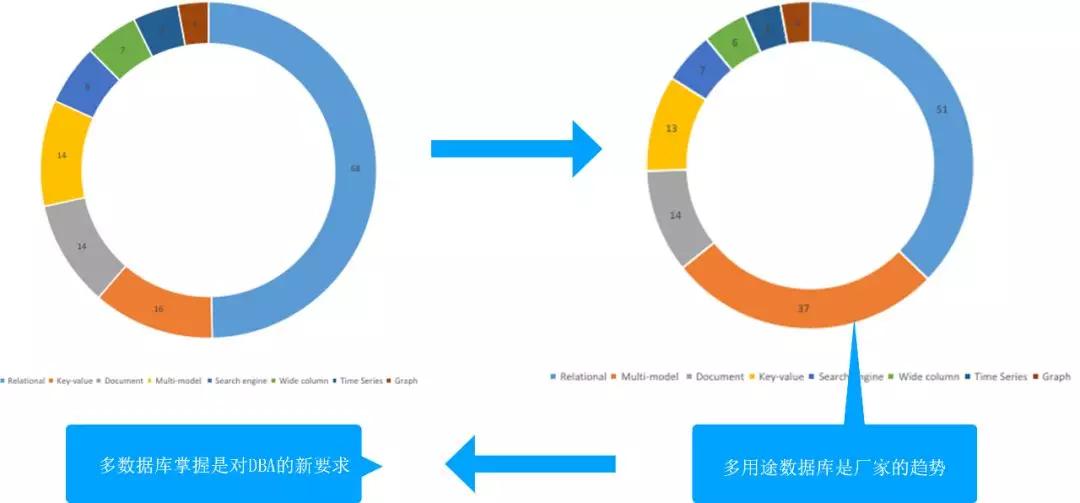
多用途數(shù)據(jù)庫是廠商選擇的趨勢,他們研發(fā)了越來越多支持多用途的數(shù)據(jù)庫。廠商為什么會這么做?供給側(cè)的改變來源于需求側(cè),因為有很多需求已經(jīng)不是單一的數(shù)據(jù)庫能解決的了。
在這種場景下,廠商迫于這種需求開發(fā)了很多能適應(yīng)更多場景的數(shù)據(jù)庫。這種趨勢對DBA來說意味著什么?這提醒我們,對多種數(shù)據(jù)庫的掌握是現(xiàn)在這個時代對DBA的要求。
這是一個必然的發(fā)展趨勢,因為你要解決的場景會越來越多,你需要掌握的數(shù)據(jù)庫領(lǐng)域也越來越廣,這就意味著之前「一招鮮」的玩法已經(jīng)落伍了。
我們再看現(xiàn)在崗位的設(shè)置,往前其實是純自建時代,現(xiàn)在的時代是云時代,這兩個時代有著本質(zhì)的區(qū)別。
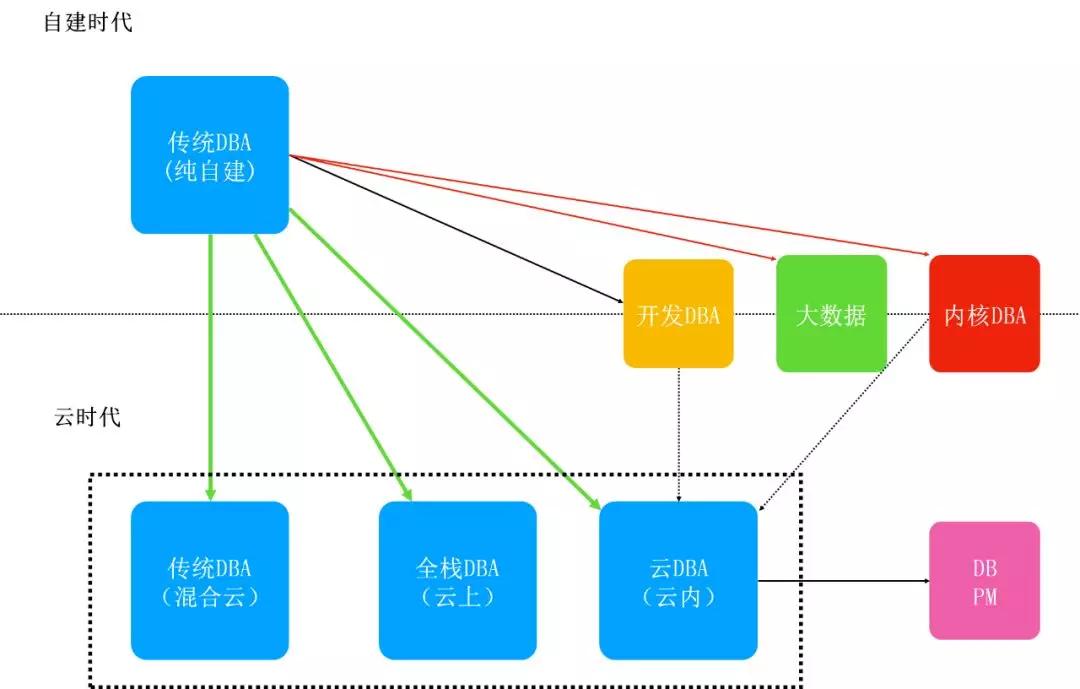
自建時代的DBA更多意義上是運維領(lǐng)域區(qū)分出來的一個更專業(yè)、門檻更高的職業(yè)領(lǐng)域,再往前都沒有DBA,都是Ops管理的。后來出現(xiàn)DBA,再慢慢演化到DBA做一些細分,出現(xiàn)了開發(fā)DBA、內(nèi)核DBA,還有部分同學轉(zhuǎn)去專門做大數(shù)據(jù),這就是在自建時代的整個狀態(tài)。
但是云時代會有一些什么樣的變化呢?其實自建時代的傳統(tǒng)DBA現(xiàn)在還存在,因為有混合云的存在。那么變化是什么?是無論如何都不可能完全不談云,一旦上云,自有的運維體系受到?jīng)_擊是其次,主要還是業(yè)務(wù)可以選擇的服務(wù)就多起來了。之前由于基礎(chǔ)設(shè)施導致需要業(yè)務(wù)適配數(shù)據(jù)庫的情況就會變成需要DBA掌握更多的數(shù)據(jù)庫類型來滿足業(yè)務(wù)了。
更有甚者是有的公司已經(jīng)全部上云了,之前賴以生存的工作都變成了云服務(wù),這時候的DBA要做什么轉(zhuǎn)變?最后還有一種變化是云內(nèi)DBA,作為云公司的DBA,孵化一個產(chǎn)品和提供對內(nèi)服務(wù)又完全不是一回事。未來基本上我認為DBA就是這三個領(lǐng)域里面打轉(zhuǎn)了(混合云DBA、云上DBA和云內(nèi)DBA),但是無論哪種都需要掌握更多的數(shù)據(jù)庫,這個是不變的。
綜上,這個時代對DBA的要求就是需要掌握的數(shù)據(jù)庫領(lǐng)域越來越多的,甭管你是在哪個線上的,都需要懂很多領(lǐng)域,至少精通一種,掌握N多種,這是我這次演講想傳遞給大家的一個概念。
二、選型原則一二三
原則1:不講場景的選型都是耍流氓
在座做過數(shù)據(jù)庫選型相關(guān)工作的都知道場景很重要,但不是所有人都能把這個概念深入到骨子里。比如這個場景,我相信大家應(yīng)該都有實際經(jīng)歷過。
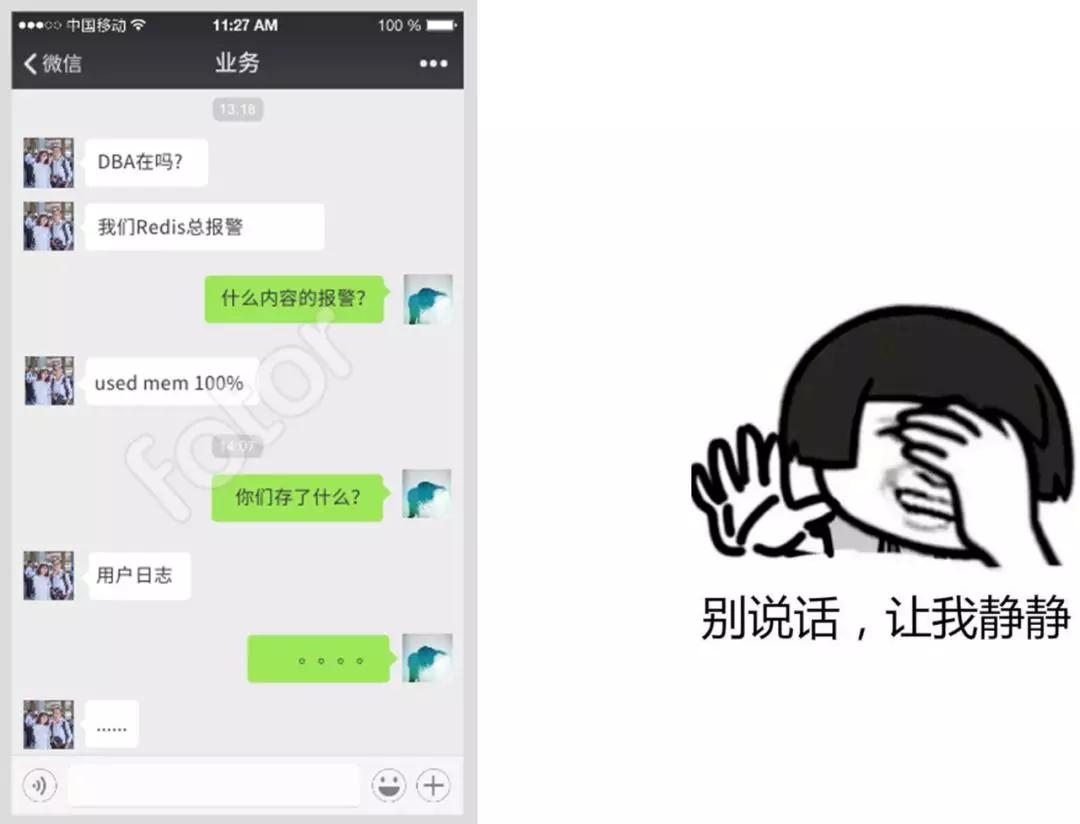
你的用戶對數(shù)據(jù)庫的了解是沒有DBA熟的,他的出發(fā)點跟你的出發(fā)點是不一樣的,你想要的是長治久安,他想要的是把功能搞定。

如果你要做業(yè)務(wù)選型一定要對場景進行劃分,如日志類、搜索類、離線需求等等,這些全部要跟線上分別開。業(yè)務(wù)模型是怎么樣的?活動型還是規(guī)律型的,你是多讀還是寫多的?然后數(shù)據(jù)增長方式是怎樣的,不能光滿足上線一剎那的需求,業(yè)務(wù)增長是日期型的還是用戶型的、位置型的?這些都需要跟你和業(yè)務(wù)聊清楚了,如果問不清楚,后期就面臨一個最嚴重的問題:數(shù)據(jù)遷移。而數(shù)據(jù)遷移本身就可以成為一個主題,這就意味著這個事情會花費巨大的成本,如果能從初期就避免掉盡量從初期避免。
原則2:沒有數(shù)據(jù)就沒得聊
沒法度量的東西就沒法管,放在數(shù)據(jù)領(lǐng)域一樣,沒有數(shù)據(jù)就沒法談。
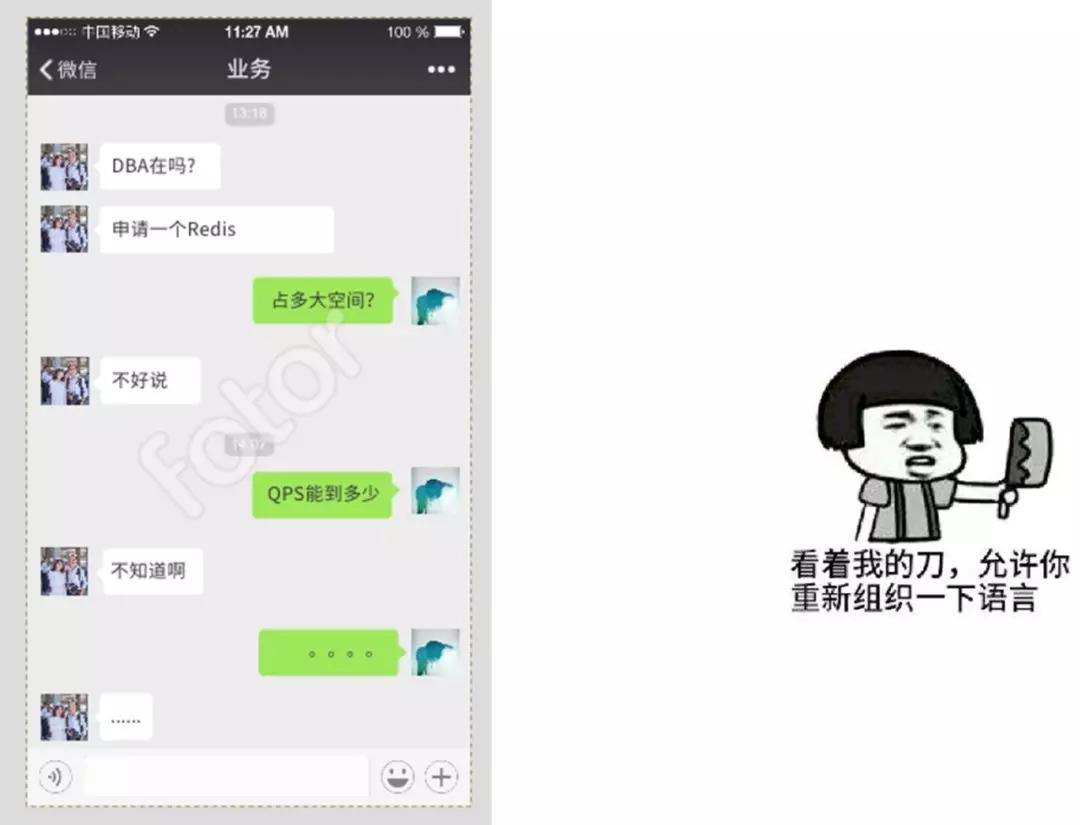
這是一個場景,你找業(yè)務(wù)聊天的時候一問三不知,經(jīng)常會遇到,業(yè)務(wù)也確實沒有辦法。但我想說的是我們一定要讓業(yè)務(wù)方拍出來的一個數(shù)據(jù),因為我們所有的決策都是基于這些數(shù)據(jù)的,沒有數(shù)據(jù)就沒法決策。
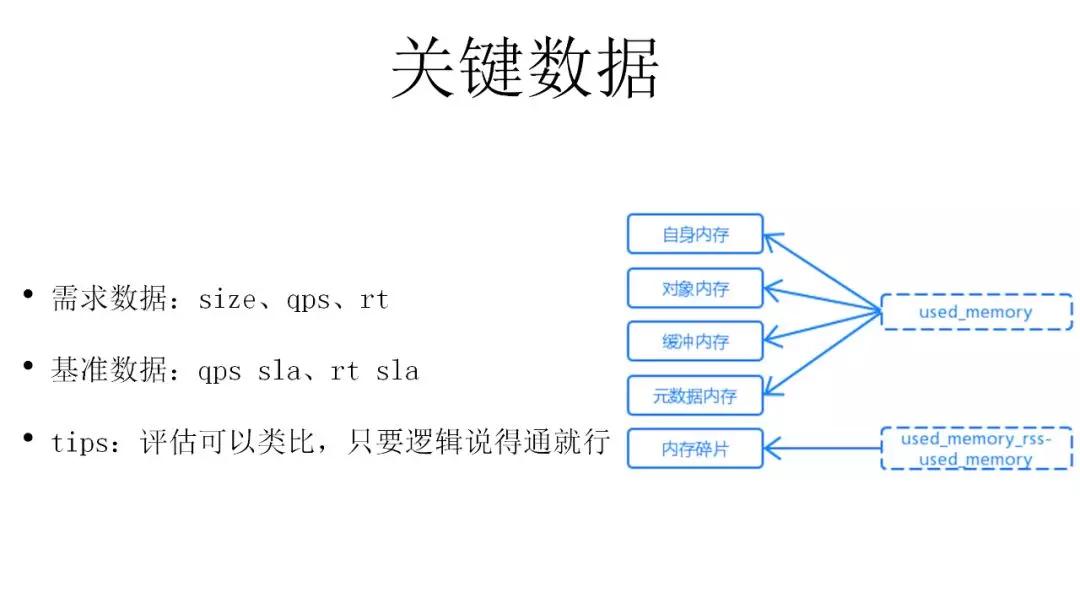
另外也期望可以讓整個業(yè)務(wù)鏈條的同學養(yǎng)成有數(shù)據(jù)的習慣,評估多了自然就能積攢下來一些方法論來解決「拍數(shù)」的問題。這其中關(guān)鍵的幾個點,也是最后選型圖上關(guān)鍵的點,一個是size,第二個是qps,還有一個是rt。
另外我們還需要提供一些基準數(shù)據(jù)。什么叫基準數(shù)據(jù),像剛才那個場景,你問業(yè)務(wù),他一問三不知,還有一種情況是業(yè)務(wù)問你MySQL能扛多久,你說我也不知道,咱們先跑再說,這肯定是不行的。
你如果管理一個類型的數(shù)據(jù)庫一定要對自己的東西有一個非常基準的認知,這個場景來了,我是給他做一主兩從還是分布式,要不要上來就千庫萬表,還是用分區(qū)表等等,這些都一定要門清的。
最后有一個tips,評估是可以類比,只要邏輯說得通就行。來了一個需求你也說不清楚到底是多大量,你就看之前這個部門做沒做過類似的活動,是在什么時間點做的,它跟你這個是什么樣的邏輯,是否是近似的邏輯,如果是近似的邏輯我們就往上套。比如上次熱點事件的峰值是多少,如果這個產(chǎn)品功能也可能和熱點頁面相關(guān)聯(lián),那么就按照上次熱點事件的峰值進行對應(yīng)的預估也算是符合邏輯的。
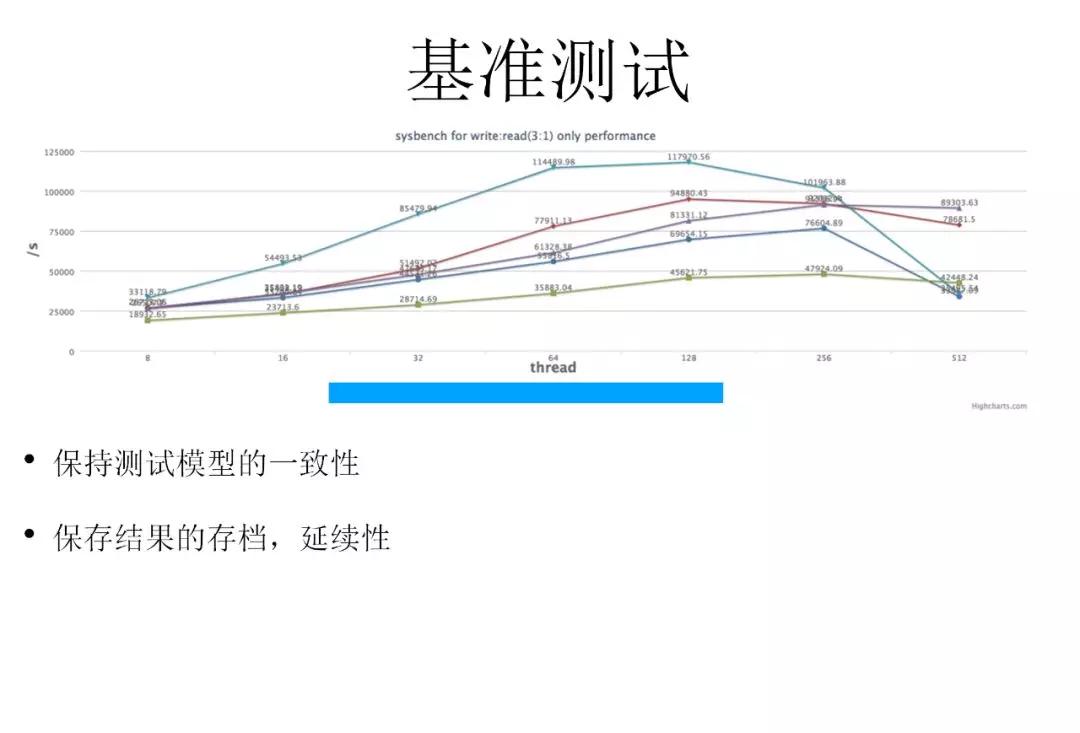
這里給大家展示一下基準測試,這是我們在做混合云運維解決方案時做的測試,因為我們需要用多家廠商的數(shù)據(jù),需要門兒清,我把這個服務(wù)部署到那家云上性能到底有什么樣的波動,也方便業(yè)務(wù)方對業(yè)務(wù)有更直觀的理解和認知。
原則3:不考慮可運維性的都應(yīng)該槍斃
最后一個原則跟前兩個區(qū)別比較大,前兩個原則基本都是知道的,但是難在落地。第三個原則其實很多DBA也不太關(guān)注,但真的是很重要的一個原則,那就是可運維性。
我開始說了,DBA跟業(yè)務(wù)方評估不一樣,你的KPI也不一樣,需求的點也不一樣,業(yè)務(wù)要求上線,你要求可運維性,這關(guān)系到你的幸福度,關(guān)系到你的起夜率。如圖的這個例子就很經(jīng)典,業(yè)務(wù)和DBA雙方根本沒有在一個頻道上溝通,最后只可能是不歡而散。
我認為的可運維性是什么?有四個方面:

一個是社區(qū)活躍度,社區(qū)活躍度決定著你獲取信息的難易程度。獲得信息的難易程度決定了什么?關(guān)系到你出現(xiàn)了故障的定位速度甚至是能不能定位出來,如果社區(qū)很活躍,自然就能得到更多的幫助。
第二個是有沒有USER CASE,最好是自己認識的人,因為眼見為實,耳聽為虛,認識的人往往能告訴你一些真實的「坑」,而不是宣傳用的「功能」。
第三個是自身團隊的情況、上手成本。你這個團隊有多大,團隊具備了什么樣技術(shù)儲備?畢竟你開辟一個新的戰(zhàn)場,每一種數(shù)據(jù)庫都不是這么簡單的,可能三四個人都不見的搞得定,但是實際業(yè)務(wù)到底使用多少卻說不清楚,這就很麻煩了。
最后一個是很隱性的事情,所謂的市場人才情況,這是可持續(xù)的成本。你如果選擇了一種數(shù)據(jù)庫,但如果市場對應(yīng)的人才很少,那么一旦出現(xiàn)人員流失,就會讓這種數(shù)據(jù)庫處于無人維護的情況,這對于公司來說是絕對不允許發(fā)生的事情。
三、選型路線圖
最后給大家聊一下選型路線圖,如果你沒有一個專門的DBA團隊,云就是最好的選型,沒有了。至于這幾家之間他們到底誰好,我認為根據(jù)投資關(guān)系選更合適一點,至于原因你懂的。
再講講這個技術(shù)選型路線圖,這是我根據(jù)這么多年團隊經(jīng)驗做的一個選型路線圖:
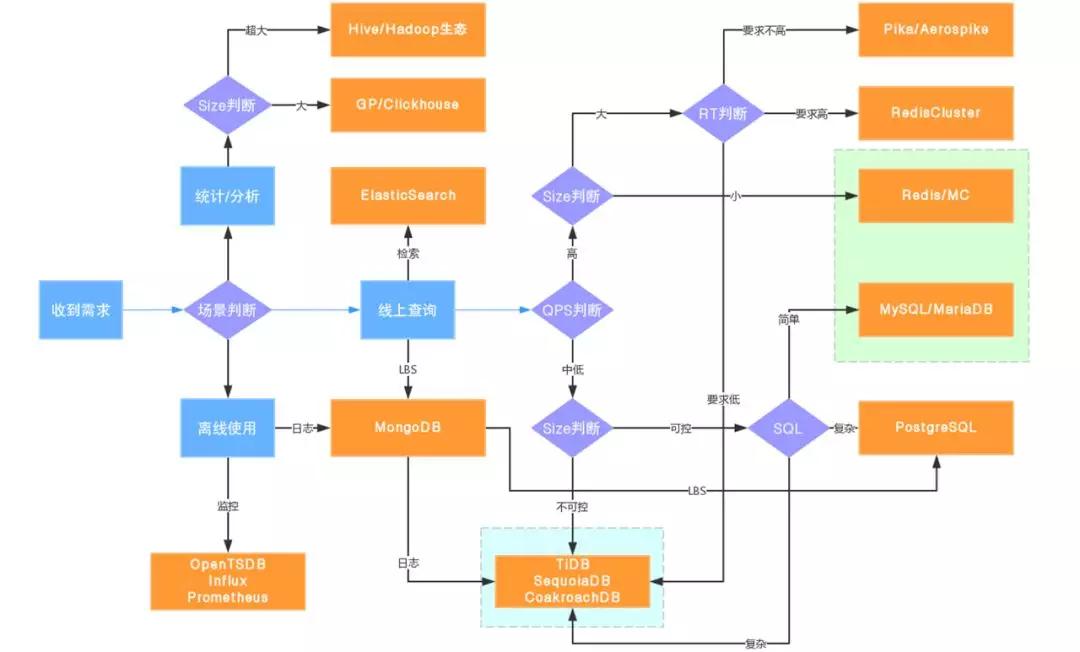
首先一定要做場景分析,到底是線上業(yè)務(wù)、離線業(yè)務(wù)還是統(tǒng)計類業(yè)務(wù)必須分出來,如果是離線的那么走hadoop生態(tài),如果是統(tǒng)計監(jiān)控類的可以走專門的時序數(shù)據(jù)庫或者ES等,即使不走也要嚴格和線上的區(qū)分。
然后是線上,特殊需求走特殊的數(shù)據(jù)庫更合適,如果是一個純粹線上TOC端的產(chǎn)品需求,我們需要進行QPS的判斷。如果是中低的QS那往下面走,根據(jù)size來判斷擴展性,如果有高擴展需求那么選目前比較火的分布式數(shù)據(jù)庫是個好選擇,如果不高,那么再往下看SQL復雜程度,一般簡單的互聯(lián)網(wǎng)應(yīng)用MySQL足以,如果是用了很多存儲過程或者復雜大查詢的,那么PG更適合一些。
返回剛才的分叉,如果QPS高的話,那么基本就是kv數(shù)據(jù)庫的天下了,我們需要先根據(jù)size來判斷,如果可控那么純內(nèi)存的kv數(shù)據(jù)庫是最佳選擇。接下來是基于RT的判斷,如果size也大、rt要求也高,那就只有分布式內(nèi)存kv數(shù)據(jù)庫(RedisCluster)選,如果對于rt要求不那么高,那么Pika/Aerospike都是比較好的節(jié)省成本的選擇。

最后說一下我們目前的最佳實踐,我們目前常規(guī)需求都使用MySQL+Cache的方案解決,特殊需求交給云RDS去解決(比如PG、MongoDB等),并且選擇了一種HTAP的分布式數(shù)據(jù)庫來解決擴展性問題。
Q & A
Q:現(xiàn)在所謂的云原生DB比較流行,但是我們目前還沒有使用到。一些宣傳上說云原生DB是可以擴展的,并且和傳統(tǒng)數(shù)據(jù)庫也是類似的,我想問一下對于傳統(tǒng)數(shù)據(jù)庫來說它的不足在哪里?
A:這個不足點就是它要求升高了,分布式數(shù)據(jù)庫的門檻變高了,對業(yè)務(wù)來說,在功能、擴展性上它現(xiàn)在是全面是超過了傳統(tǒng)的數(shù)據(jù)庫。但是對于DBA的要求來說,有非常高的門檻,這對我們之前的問題分析、調(diào)優(yōu)、故障定位思路都會有很大的沖擊。

講師介紹
肖鵬,前新浪微博研發(fā)中心技術(shù)副總監(jiān),主要負責微博數(shù)據(jù)庫(MySQL、Reids、HBase、Memcached)相關(guān)的業(yè)務(wù)保障、性能優(yōu)化、架構(gòu)設(shè)計,以及周邊的自動化系統(tǒng)建設(shè)。經(jīng)歷了微博數(shù)據(jù)庫各個階段的架構(gòu)改造,包括服務(wù)保障及SLA體系建設(shè)、微博多機房部署、微博平臺化改造等項目。10年互聯(lián)網(wǎng)數(shù)據(jù)庫架構(gòu)和管理經(jīng)驗,專注于數(shù)據(jù)庫的高性能和高可用技術(shù)保障方向。