一文幫你選擇開源消息中間件
現代開源消息中間件對比:
- NATS,
- RabbitMQ,
- Apache Kafka,
- Synapse,
- NSQ
- Pulsar
#NATS:
https://nats.io/
https://github.com/nats-io/nats-streaming-serverNATS 最初是使用Ruby構建的,每秒可實現150k消息的消費速度。 該團隊用Go中重寫了它,現在您可以每秒神奇地發送8-11百萬條消息。 它可以用作發布-訂閱引擎,但是您也可以把它用于綜合排隊。
優點:口號:始終可用,撥號音簡潔,設計低CPU消耗,快速:高速通信總線,高可用性,高可擴展性,輕巧:體積很小,只有3MB Docker映像!
缺點:忘卻,沒有持久性:NATS不進行持久性消息傳遞; 如果您處于離線狀態,則不會收到消息。 沒有事務,沒有增強的交付方式,沒有企業排隊。
總的來說,NATS和Redis更適合較小的消息(遠低于1MB),其中延遲通常在不到毫秒的時間內達到四個9. NATS不是HTTP,它是擁有它自己的非常簡單的基于文本的協議,類似于RPC 。 因此,它不會在郵件信封中添加任何標題。
NATS沒有復制,分片或整體訂購。 使用NATS,隊列可以有效地按節點分片。 如果節點死亡,則其消息將丟失。 到活動節點的傳入消息仍將傳遞給已連接的訂戶,并且訂戶應重新連接到可用節點池。 一旦先前死掉的節點重新加入,它將開始接收消息。在這種情況下,NATS會替換HAProxy之類的內容; 一個簡單的內存路由器,用于請求后端。
NATS的用戶包括Buzzfeed,Tinder,Stripe,Rakutan,Ericsson,HTC,Siemens,VMware,Pivotal,GE和Baidu。一個用例:“我們使用NATS進行同步通信,每秒通過它發送約1萬條消息。 。 必須說,即使負載更大(超過10MB),穩定性也很高。 我們已經在生產環境中運行了幾周,并且沒有任何問題。 主要限制是沒有大規模集群。 您可以擁有一個非常強大的集群,但是每個節點只能轉發一次,這是有限制的。”
#RabbitMQ:
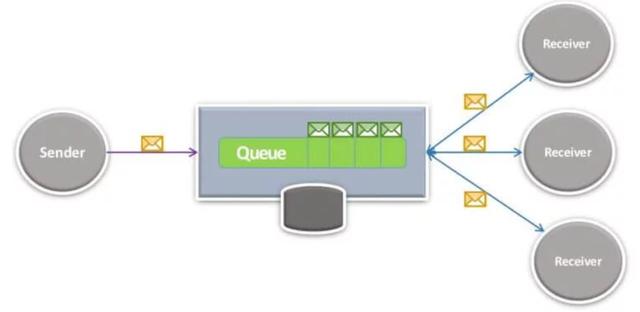
RabbitMQ是遵循AMQP 0.9.1標準的代理消息傳遞引擎。 它遵循標準的存儲轉發模式,您可以選擇將數據存儲在RAM中,在磁盤上,或是在這兩者中。 它支持各種消息路由范例。 RabbitMQ可以以集群方式進行部署以提高性能,而可以通過鏡像方式進行部署,以實現高可用性。 消費者直接在隊列上偵聽,但是發布者只知道“交換”。這些交換通過綁定(指定路由范式)與綁定鏈接到隊列。 綁定隊列和事務傳遞語義。 因此,RabbitMQ是一種更為“重量級”的排隊解決方案,并為此付出額外的費用。
缺點:RabbitMQ的高可用性支持非常糟糕。 無論您如何轉動,它都是單點故障,因為它無法合并因為分區情況而導致的沖突隊列。 分區不僅會在網絡中斷時發生,還會在高負載情況下發生。RabbitMQ不會將消息持久保存到磁盤。
#Kafka:
基于Scala
使用Kafka,您可以進行實時處理和批處理。 Kafka在JVM上運行(具體來說是Scala)。 攝取大量數據,通過發布-訂閱(或排隊)路由。 Broker對消費者幾乎一無所知。 真正存儲的只是一個“偏移”值,該值指定使用者在日志中保留的位置。 與許多假定消費者主要在線的集成代理不同,Kafka可以成功保存大量數據并支持“重播”方案。 該體系結構非常獨特。 主題按分區排列(用于并行性),分區跨節點復制(以實現高可用性)。
與Kafka相比,NATS是一個很小的基礎架構,獨角獸初創公司,物聯網,健康和大型金融組織(LinkedIn,FB,Netflix,GE,美國銀行,房利美,大通銀行等)都使用Kafka。與Nats相比,Kafka更成熟,并且在巨大的數據流中表現出色。NATSServer相比Kafka具有部分功能,因為它專注于狹窄的用例集。 NATS被設計用于以下場景:高性能和低延遲至關重要,但是如果需要,可以丟失一些數據,以跟上數據的步伐-NATS文檔將其描述為“一勞永逸”。從結構上講,這是因為NATS沒有持久性層可用于持久存儲數據,而Kafka卻具有持久性層(使用群集中的存儲)。為了完全確保消息不會丟失,它看起來像您需要將隊列聲明為持久+將您的消息標記為持久+使用發布者確認。這花費了數百毫秒的延遲。
對于分區而言,相對安全的唯一隊列或發布/訂閱系統是Kafka。 當您需要5至50臺服務器時,Kafka就是一個非常可靠的工程。 擁有那么多服務器,您每秒可以處理數百萬條消息,這通常對于中型公司而言已經足夠。
由于多種原因,Kafka完全不適合RPC。 首先,它的數據模型將隊列中的數據分片,每個分區只能由一個使用者使用。 假設我們有分區1和2。P1為空,P2有大量消息。 現在,當C2工作時,您將擁有一個空閑的使用者C1。 C1無法承擔C2的任何工作,因為它只能處理自己的分區。 換句話說:一個緩慢的使用者可以阻塞隊列的很大一部分。 Kafka專為快速(或至少表現均勻)的消費者而設計。
- NATS與Kafka的關系
NATS最近加入了CNCF(托管Kubernetes,Prometheus等項目-在這里查看Golang的優勢!)協議-Kafka是基于TCP的二進制文件,而不是NATS是簡單文本(也基于TCP)的消息傳遞模式-兩者都支持發布/訂閱和隊列,但是NATS也支持請求-應答(同步和異步)。NATS具有隊列的概念(當然具有唯一的名稱),并且掛接到同一隊列的所有訂戶最終都成為一部分屬于同一隊列組。 (可能多個)訂閱者中只有一個收到消息。多個此類隊列組也將接收同一組消息。這使其成為混合的發布-訂閱(一對多)和隊列(點對點)。 Kafka通過消費者組支持相同的事物,這些用戶組可以從一個或多個主題中提取數據。流處理— NATS不像Kafka那樣對Kafka Streams提供一流的功能,因此不支持流處理。相對于NATS,NATS提取消息的方式與服務器本身將消息路由到客戶端的NATS(內部維護興趣圖)相對。NATS可以采取敏感措施,因為它可以切斷不符合生產速度的消費者,以及不響應心跳請求的客戶。消費者活躍度檢查也由Kafka執行。這是從客戶端本身完成/啟動的,因此可能會導致復雜的情況(例如,當您處于消息處理循環中且未輪詢時)。有很多配置參數(在客戶端上)可調整此行為。
- 交付語義-NATS支持最多一次(At most once)(并且NATS流至少支持一次),而Kafka則支持僅一次(Exactly once)( NATs似乎沒有像Kafka那樣對分區/分片消息的概念,在NATS情況下沒有外部依賴性。 Kafka要求Zookeeper,NATS Streaming似乎與Kafka功能集相似,但是使用Go構建并且看起來更易于設置. NATS目前不支持復制(或實際上沒有任何高可用性設置)。與Kafka相比,這是一個主要的缺失功能。
#NSQ:
易于設置NSQ似乎更靈活,它支持消息持久性,并且在持久性要求不高的情況下,還提供類似于NATS的臨時通道。 它配備了NATS缺少的閃亮的管理儀表板。 當優先考慮原始性能時,NATS很有用.NATS和NSQ隊列均支持按消息TTL,以修剪時間敏感消息。
Kafka很復雜,但保證不會丟失任何數據。 適合訂購日志。 NSQ缺乏持久性和復制能力。 大規模操作非常簡單。Kafka的性能和增強的保證以難以操作為代價。有了Kafka,除了Kafka經紀人,您還需要一個Zookeeper集群。 Kafka需要考慮分區和偏移量,最好將Kafka視為分布式日志服務,而不是消息傳遞代理,例如數據庫中的預寫日志而不是printf語句。
NSQ是一種更為傳統的緩沖消息系統。 它具有文件持久性,但僅作為 a)優化以防止一旦內存用完就會丟失消息,以及b)作為使用者檔案。 但是,節點的嚴重丟失意味著尚未傳遞的那些消息可能會丟失,因為無法保證它們會在其他地方發布。 此外,不能保證發布到主題和頻道的消息順序是消費者接收到的消息順序。 使用NSQ,有一個內置實用程序nsq_to_file,它成為您將每個消息主題歸檔到磁盤時的另一個使用方。 它提供了簡單的郵件存檔功能,但不提供任何本地重播功能。
#Apache Pulsar(pulsar.incubator.apache.org):
基于Java
它是雅虎公司設計的,是一種高性能,低延遲,可擴展的持久解決方案,用于發布訂閱消息和消息排隊。 Apache Pulsar將高性能流(Apache Kafka追求)和靈活的傳統排隊(RabbitMQ追求)結合在一起,成為統一的消息傳遞模型和API。 Pulsar使用統一的API為您提供具有相同高性能的流和排隊系統。 總而言之,Kafka的目標是高吞吐量,Pulsar的目標是低延遲。
Pulsar 優點
- 豐富—持久性/非持久性主題,多租戶,ACL,多DC復制等。
- 更易于使用的更靈活的客戶端API(包括CompletableFutures,流暢的接口等)。
- Java客戶端組件是線程安全的,消費者可以確認來自不同的線程的消息
Pulsar 缺點
- Java客戶端幾乎沒有Javadoc
- Small社區-當前有8個stackoverflow問題
- 與BookKeeper綁定的MessageId
- 與連續數字序列的Kafka偏移量相比,消費者無法輕松地將自己定位在主題上。讀者無法輕松閱讀關于該主題的最后一條消息。
- 沒有事務支持。
- 更高的操作復雜性— Zookeeper + Broker節點+ BookKeeper —所有clusterLatency都可疑— Broker節點與BookKeeper之間有一個額外的遠程調用(與Kafka相比)
Kafka 優點
- 非常豐富和有用的JavaDoc
- Kafka Streams 成熟和廣泛的社區
- 在生產中易于操作-更少的組件-代理節點還提供storage
- 事務-主題內的原子讀取和寫入偏移形成連續序列-消費者可以輕松地尋找到最后一條消息
Kafka 缺點
- Consumer無法確認來自其他線程的消息
- 沒有多租戶
- 沒有健壯的Multi-DC復制-(在Confluent Enterprise中提供)
- 在云環境中的管理很困難。