后端程序員必備:索引失效的十大雜癥
背景
最近生產(chǎn)爆出一條慢sql,原因是用了or和!=,導(dǎo)致索引失效。于是,總結(jié)了索引失效的十大雜癥,希望對(duì)大家有幫助,加油。
一、查詢(xún)條件包含or,可能導(dǎo)致索引失效
新建一個(gè)user表,它有一個(gè)普通索引userId,結(jié)構(gòu)如下:
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` int(11) NOT NULL,
- `age` int(11) NOT NULL,
- `name` varchar(255) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_userId` (`userId`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
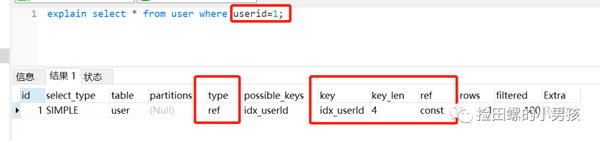
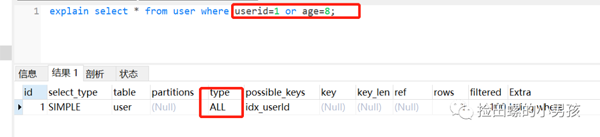
分析&結(jié)論:
- 對(duì)于or+沒(méi)有索引的age這種情況,假設(shè)它走了userId的索引,但是走到age查詢(xún)條件時(shí),它還得全表掃描,也就是需要三步過(guò)程:全表掃描+索引掃描+合并
- 如果它一開(kāi)始就走全表掃描,直接一遍掃描就完事。
- mysql是有優(yōu)化器的,處于效率與成本考慮,遇到or條件,讓索引失效,看起來(lái)也合情合理嘛。
注意: 如果or條件的列都加了索引,索引可能會(huì)走的,大家可以自己試一試。
二、如何字段類(lèi)型是字符串,where時(shí)一定用引號(hào)括起來(lái),否則索引失效
假設(shè)demo表結(jié)構(gòu)如下:
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` varchar(32) NOT NULL,
- `name` varchar(255) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_userId` (`userId`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
userId為字符串類(lèi)型,是B+樹(shù)的普通索引,如果查詢(xún)條件傳了一個(gè)數(shù)字過(guò)去,它是不走索引的,如圖所示:
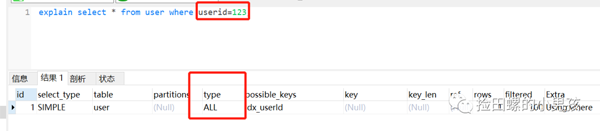
如果給數(shù)字加上'',也就是傳一個(gè)字符串呢,當(dāng)然是走索引,如下圖:
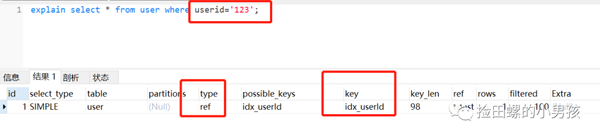
分析與結(jié)論:
為什么第一條語(yǔ)句未加單引號(hào)就不走索引了呢?這是因?yàn)椴患訂我?hào)時(shí),是字符串跟數(shù)字的比較,它們類(lèi)型不匹配,MySQL會(huì)做隱式的類(lèi)型轉(zhuǎn)換,把它們轉(zhuǎn)換為浮點(diǎn)數(shù)再做比較。
三、like通配符可能導(dǎo)致索引失效。
并不是用了like通配符,索引一定失效,而是like查詢(xún)是以%開(kāi)頭,才會(huì)導(dǎo)致索引失效。
表結(jié)構(gòu):
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` varchar(32) NOT NULL,
- `name` varchar(255) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_userId` (`userId`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
like查詢(xún)以%開(kāi)頭,索引失效,如圖:
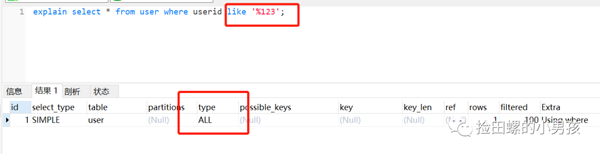
把%放后面,發(fā)現(xiàn)索引還是正常走的,如下:
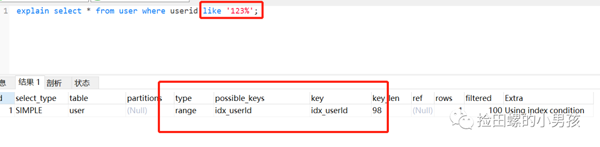
把%加回來(lái),改為只查索引的字段(覆蓋索引),發(fā)現(xiàn)還是走索引,驚不驚喜,意不意外
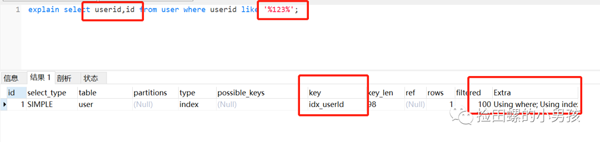
結(jié)論:
like查詢(xún)以%開(kāi)頭,會(huì)導(dǎo)致索引失效。可以有兩種方式優(yōu)化:
- 使用覆蓋索引
- 把%放后面
附: 索引包含所有滿足查詢(xún)需要的數(shù)據(jù)的索引,稱(chēng)為覆蓋索引(Covering Index)。
四、聯(lián)合索引,查詢(xún)時(shí)的條件列不是聯(lián)合索引中的第一個(gè)列,索引失效。
表結(jié)構(gòu):(有一個(gè)聯(lián)合索引 idx_userid_age, userId在前, age在后)
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` int(11) NOT NULL,
- `age` int(11) DEFAULT NULL,
- `name` varchar(255) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_userid_age` (`userId`,`age`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
在聯(lián)合索引中,查詢(xún)條件滿足最左匹配原則時(shí),索引是正常生效的。請(qǐng)看demo:
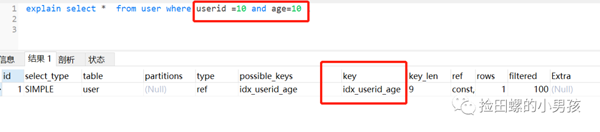

如果條件列不是聯(lián)合索引中的第一個(gè)列,索引失效,如下:

分析與結(jié)論:
- 當(dāng)我們創(chuàng)建一個(gè)聯(lián)合索引的時(shí)候,如(k1,k2,k3),相當(dāng)于創(chuàng)建了(k1)、(k1,k2)和(k1,k2,k3)三個(gè)索引,這就是最左匹配原則。
- 聯(lián)合索引不滿足最左原則,索引一般會(huì)失效,但是這個(gè)還跟Mysql優(yōu)化器有關(guān)的。
五、在索引列上使用mysql的內(nèi)置函數(shù),索引失效。
表結(jié)構(gòu):
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` varchar(32) NOT NULL,
- `loginTime` datetime NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_userId` (`userId`) USING BTREE,
- KEY `idx_login_time` (`loginTime`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
雖然loginTime加了索引,但是因?yàn)槭褂昧薽ysql的內(nèi)置函數(shù)Date_ADD(),索引直接GG,如圖:
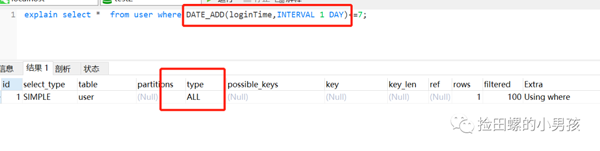
六、對(duì)索引列運(yùn)算(如,+、-、*、/),索引失效。
表結(jié)構(gòu):
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` varchar(32) NOT NULL,
- `age` int(11) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_age` (`age`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
雖然age加了索引,但是因?yàn)樗M(jìn)行運(yùn)算,索引直接迷路了。。。山重水復(fù)疑無(wú)路,算著算著腦瓜疼,索引就真的不認(rèn)識(shí)路了。如圖:
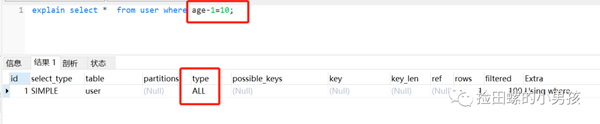
七、索引字段上使用(!= 或者 < >,not in)時(shí),可能會(huì)導(dǎo)致索引失效。
表結(jié)構(gòu):
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `userId` int(11) NOT NULL,
- `age` int(11) DEFAULT NULL,
- `name` varchar(255) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_age` (`age`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
雖然age加了索引,但是使用了!= 或者 < >,not in這些時(shí),索引如同虛設(shè)。如下:


八、索引字段上使用is null, is not null,可能導(dǎo)致索引失效。
表結(jié)構(gòu):
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `card` varchar(255) DEFAULT NULL,
- `name` varchar(255) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_name` (`name`) USING BTREE,
- KEY `idx_card` (`card`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
單個(gè)name字段加上索引,并查詢(xún)name為非空的語(yǔ)句,其實(shí)會(huì)走索引的,如下:

單個(gè)card字段加上索引,并查詢(xún)name為非空的語(yǔ)句,其實(shí)也會(huì)走索引的,如下:
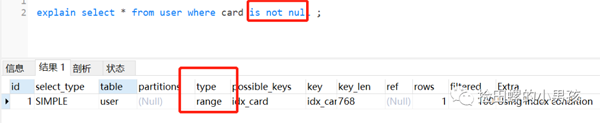
但是它們用or連接起來(lái),索引就失效了,如下:
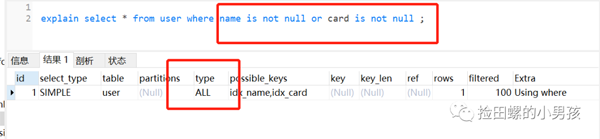
九、左連接查詢(xún)或者右連接查詢(xún)查詢(xún)關(guān)聯(lián)的字段編碼格式不一樣,可能導(dǎo)致索引失效。
新建兩個(gè)表,一個(gè)user,一個(gè)user_job
- CREATE TABLE `user` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
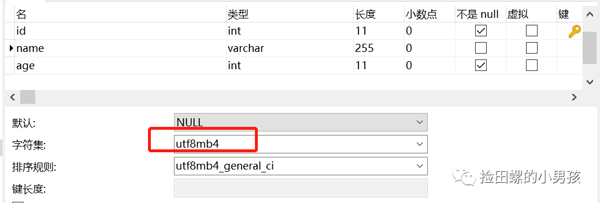
- `name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL,
- `age` int(11) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_name` (`name`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
- CREATE TABLE `user_job` (
- `id` int(11) NOT NULL,
- `userId` int(11) NOT NULL,
- `job` varchar(255) DEFAULT NULL,
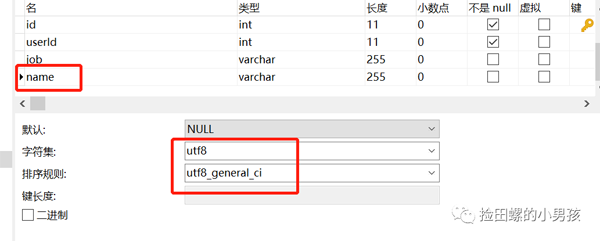
- `name` varchar(255) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_name` (`name`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
user 表的name字段編碼是utf8mb4,而user_job表的name字段編碼為utf8。
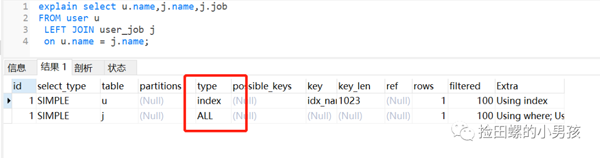
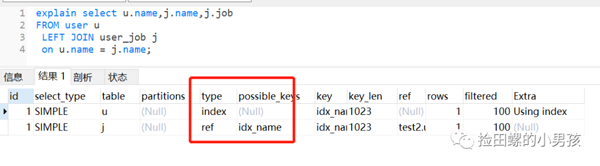
執(zhí)行左外連接查詢(xún),user_job表還是走全表掃描,如下:
如果把它們改為name字段編碼一致,還是會(huì)一路高歌,雄赳赳,氣昂昂,走向索引。
十、mysql估計(jì)使用全表掃描要比使用索引快,則不使用索引。
- 當(dāng)表的索引被查詢(xún),會(huì)使用最好的索引,除非優(yōu)化器使用全表掃描更有效。優(yōu)化器優(yōu)化成全表掃描取決與使用最好索引查出來(lái)的數(shù)據(jù)是否超過(guò)表的30%的數(shù)據(jù)。
- 不要給'性別'等增加索引。如果某個(gè)數(shù)據(jù)列里包含了均是"0/1"或“Y/N”等值,即包含著許多重復(fù)的值,就算為它建立了索引,索引效果不會(huì)太好,還可能導(dǎo)致全表掃描。
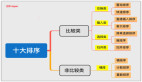
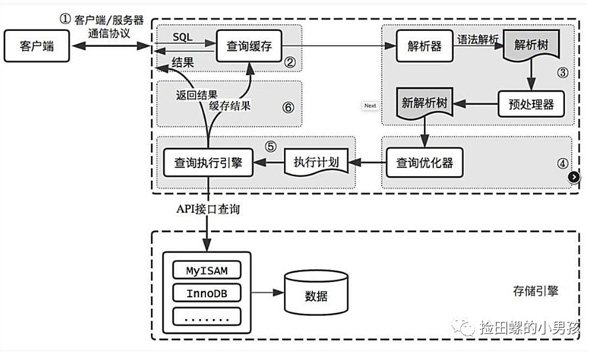
Mysql出于效率與成本考慮,估算全表掃描與使用索引,哪個(gè)執(zhí)行快。這跟它的優(yōu)化器有關(guān),來(lái)看一下它的邏輯架構(gòu)圖吧(圖片來(lái)源網(wǎng)上)
總結(jié)
總結(jié)了索引失效的十大雜癥,在這里來(lái)個(gè)首尾呼應(yīng)吧,分析一下我們生產(chǎn)的那條慢sql。模擬的表結(jié)構(gòu)與肇事sql如下:
- CREATE TABLE `user_session` (
- `user_id` varchar(32) CHARACTER SET utf8mb4 NOT NULL,
- `device_id` varchar(64) NOT NULL,
- `status` varchar(2) NOT NULL,
- `create_time` datetime NOT NULL,
- `update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
- PRIMARY KEY (`user_id`,`device_id`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- explain
- update user_session set status =1
- where (`user_id` = '1' and `device_id`!='2')
- or (`user_id` != '1' and `device_id`='2')
分析:
- 執(zhí)行的sql,使用了 or條件,因?yàn)榻M合主鍵( user_id, device_id),看起來(lái)像是每一列都加了索引,索引會(huì)生效。
- 但是出現(xiàn) !=,可能導(dǎo)致索引失效。也就是 or+ !=兩大綜合癥,導(dǎo)致了慢更新sql。
解決方案:
那么,怎么解決呢?我們是把 or條件拆掉,分成兩條執(zhí)行。同時(shí)給 device_id加一個(gè)普通索引。
最后,總結(jié)了索引失效的十大雜癥,希望大家在工作學(xué)習(xí)中,參考這十大雜癥,多點(diǎn)結(jié)合執(zhí)行計(jì)劃 expain和場(chǎng)景,具體分析,而不是按部就班,墨守成規(guī),認(rèn)定哪個(gè)情景一定索引失效等等。