數據可視化常用的后端技術
這篇文章大致講講需要用到的后端技術。其實如果只是小數據量,或者是一些小型的項目,研究型的項目,純前端就可以搞定,利用JS讀取數據,JS處理數據。
后端無非就是處理數據,提取用戶想要的數據。筆者最常用的就是python了,相對于java,c, c++,python簡直對初學者太友好,提供了豐富多彩的API接口,比如常見的降維聚類算法:PCA, t-SNE, MDS, k-means等。筆者曾經用c實現過PCA算法,應該有幾百行代碼吧,可是在python里,只需要三行代碼。下文將為大家介紹下如何用python實現對Iris數據集使用PCA算法,以及展示效果。
因此,筆者強烈建議新手使用python練手,操作門檻低,前期可以將更多的關注點集中在前端數據可視化上。到了后期,有經驗了就可以自由組合。筆者前期使用的是python,可是到了后期由于性能問題,python已經很難解決我項目所遇到的數據和算法復雜度。于是我將復雜度高的算法全部用C重寫了一遍,并用python調用這個模塊。這樣之前項目的項目代碼框架不變,不需要代碼全部重寫重構,只需在相應的地方調用相應的C模塊即可。
python使用PCA算法實戰
在講之前,用戶需要安裝python包,這里強烈建議新手安裝anaconda,anaconda集成了python以及在開發過程中一大堆第三方包,比如下文用到的sklearn包。
引入第三方庫的PCA算法,sklearn是pythonz中常用的機器學習第三方模塊,對常用的機器學習方法進行了封裝,包括回歸、降維、分類、聚類等方法。
- from sklearn.decomposition import PCA
加載python中自帶的Iris數據集,做機器學習的應該比較熟悉這個數據集。主要包含4個維度,三個類。
- from sklearn.datasets import load_iris
- irisData = load_iris()
對數據集使用PCA算法,將數據降到2維。
- pca = PCA(n_components=2)
- reducedData = pca.fit(irisData)
將結果在散點圖中畫出來。這里就不講具體python的繪制邏輯了,沒錯,python就是這么強大,也提供了可視化圖表的能力。但是更多還是以處理數據為目的,將數據傳給前端,讓前端繪制。感興趣的可以去了解下:matplotlib,這個是python的可視化繪圖庫。
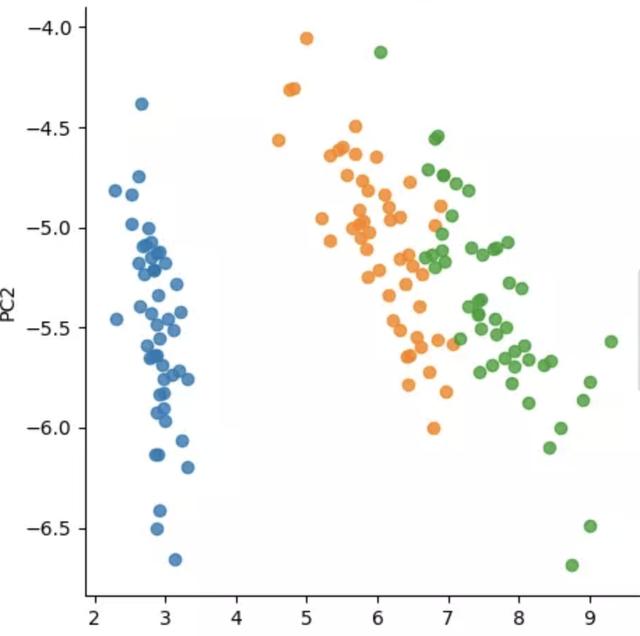
iris數據集降到二維