面試官:簡歷上說精通垃圾收集器?來吧,挨個給我說一遍
面試官:你認識到的收集器都有哪些啊?
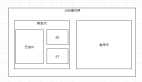
答:Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1;
面試官:為什么HotSpot虛擬機需要這么多收集器?
答:HotsSpot垃圾是分代收集的,所以不用的分代收集器也不同,即使是同一年代里收集器也會不同,因為每個收集器特點和性能不同也就有了收集器的多樣性,所以各個收集器互相組合使用才能適應不同場景。
面試官:那你說一下每個收集器都有什么特點吧!
新生代收集器:Serial、ParNew、Parallel Scavenge;
老年代收集器:Serial Old、Parallel Old、CMS;
整堆收集器:G1;
開始之前我們了解一個概念
Minor GC
又稱新生代GC,指發生在新生代的垃圾收集動作;
因為Java對象大多是朝生夕滅,所以Minor GC非常頻繁,一般回收速度也比較快;
Full GC
又稱Major GC或老年代GC,指發生在老年代的GC;
出現Full GC經常會伴隨至少一次的Minor GC(不是絕對,Parallel Sacvenge收集器就可以選擇設置Major GC策略);
Major GC速度一般比Minor GC慢10倍以上;
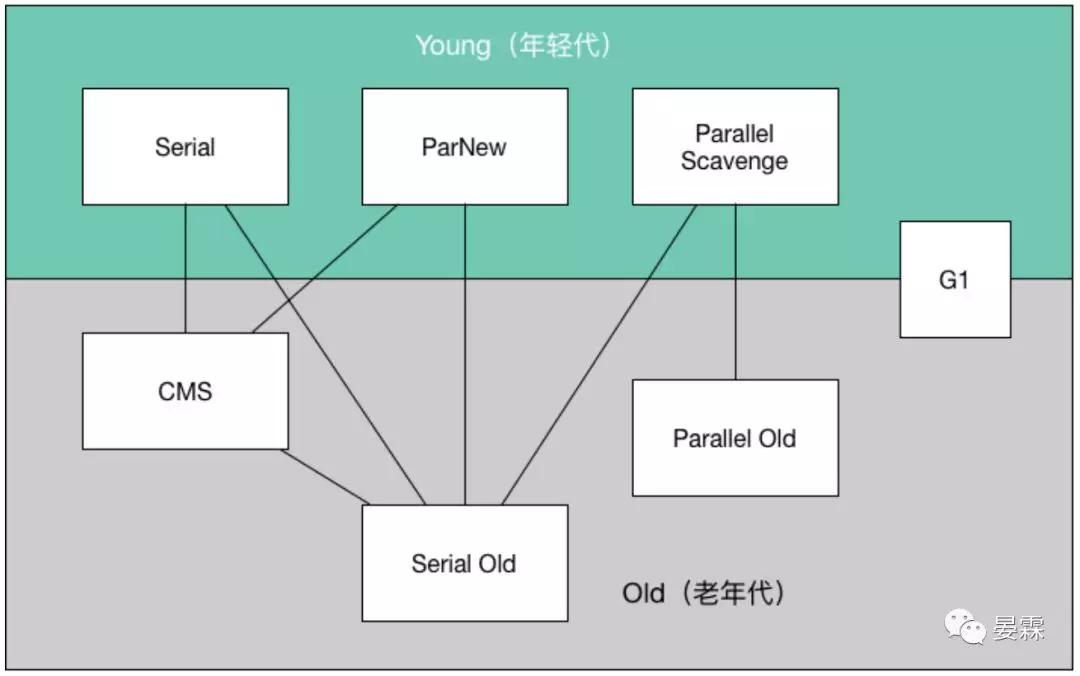
Serial收集器
這個收集器是最基本的,也是歷史最悠久的收集器,目前基本不會用了,想當年那也是新生代的唯一選擇,但是這么多年過去了,HotSpot也沒有說過河拆橋把它廢了,“老而無用、食之無味棄之可惜”。
他是一個單線程收集器,他在工作的時候,必須暫停其他所有的工作線程,直到收集結束。這里要知道一個很嚴重的問題就是,暫停一切線程的結果就是當前運行在這個JDK的所有程序里的用戶線程全部暫停,也就是說這一瞬間都是死掉的,用戶看到的現象就是頁面無任何響應,如果這種現象出現的時間長且頻繁用戶就崩潰了。
這里埋下了一個伏筆,越優秀的收集器,他的停頓時間一定越短,這也是所有收集器共同追求的目標。
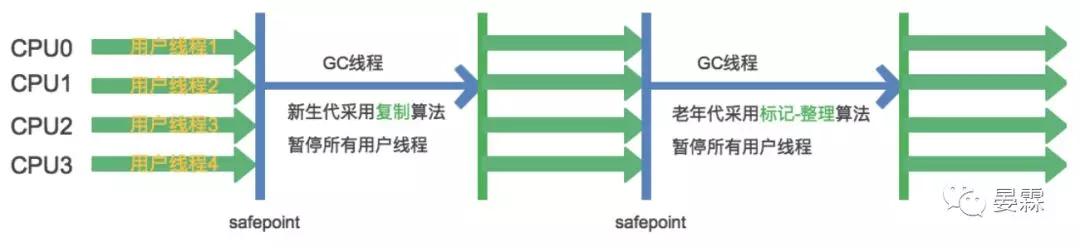
ParNew收集器
他是Serial收集器多線程版本,其所有控制參數、收集算法、對象分配規則、回收策略等都與Serial完全一樣。下面是ParNew收集器工作的過程。
他的重要之處在于,除了多線程提高了性能之外,他還可以與CMS收集器(下面介紹)搭配使用的原因。
在單CPU環境下ParNew的性能沒辦法超過Serial,但是隨著CPU數量增多他的優勢就會越來越明顯。
Parallel Scavenge收集器
他也是一款新生代收集器,使用的是復制算法,并且是并行對線程收集器。可以看到收集器的進步都是保留上一代之長,彌補上一代之短。
很多收集器關注用戶線程的停頓時間,但是Parallel Scavenge則關注吞吐量。所謂吞吐量就是CPU用于運行用戶代碼的時間與CPU總消耗時間的比值,即吞吐量=運行用戶代碼時間/(運行用戶代碼時間+垃圾收集時間),例:虛擬機運行100分鐘,其中垃圾收集時間用了1分鐘,那吞吐量就是99%。
他是怎樣控制吞吐量呢?
使用參數控制最大垃圾收集停頓時間 -XX:MaxGCPauseMillis ,以及直接設置吞吐量大小 -XX:GCTimeRatio參數。
MaxGCPauseMillis參數是一個大于0的毫秒數,收集器一次工作盡可能不超過設定的這個值,但是設置太小GC停頓時間縮短,造成了垃圾收集頻率變快。如果你設定停頓100毫秒,10秒收集一次的頻率,改成70毫秒的停頓時間,那么頻率就可能變成5秒一次。停頓時間下降,吞吐量也會下降,GC還會變得更頻繁。
XX:GCTimeRatio參數設置垃圾收集時間占總時間的比率,0
GCTimeRatio相當于設置吞吐量大小;
垃圾收集執行時間占應用程序執行時間的比例的計算方法是:1 / (1 + n)
例如,選項-XX:GCTimeRatio=19,設置了垃圾收集時間占總時間的5%--1/(1+19);
默認值是1%--1/(1+99),即n=99;
看來找準最優的臨界點真的是Parallel Scavenge收集器比較配置的。
不要擔心,HotSpot又提供了一個參數 XX:+UseAdptiveSizePolicy幫助我們實現GC自適應的調節策略,他會根據當前系統運行情況收集性能監控信息,動態調整這些參數,以提供最合適的停頓時間或最大的吞吐量。
這個參數開啟,JVM就可以動態分配新生代的大小(-Xmn)、Eden與Survivor區的比例(-XX:SurvivorRation)、晉升老年代的對象年齡(-XX:PretenureSizeThreshold)等;
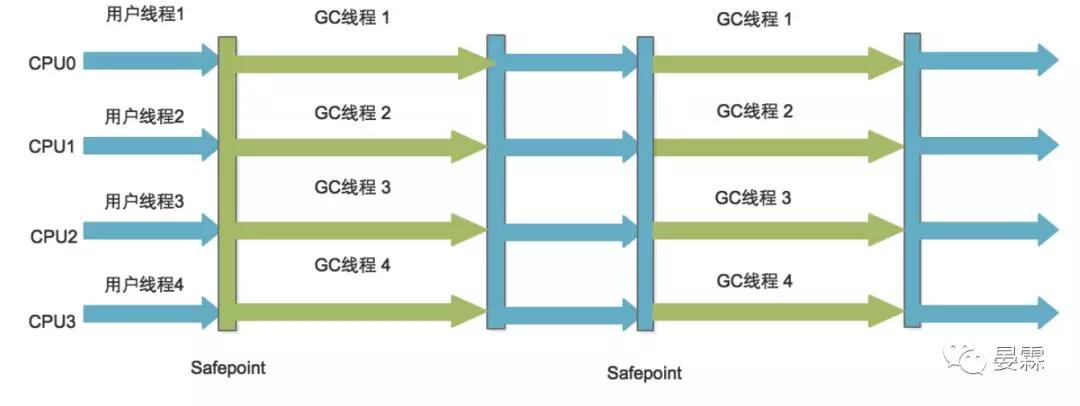
這里插入一個筆者的經歷:當時面試有人問我,Eden與Survivor區的比例可以變化嗎?
看到這里童鞋們就可以回答:Parallel Scavenge收集器開啟 XX:+UseAdptiveSizePolicy可以動態分配。
這也是Parallel Scavenge收集器優越于ParNew收集器一個重要點。
Serial Old收集器
Serial Old是 Serial收集器的老年代版本,也是繼承Serial收集器單線程的特點。
工作模型圖在Serial收集器中展示了。
Parallel Old收集器
Parallel Old垃圾收集器是Parallel Scavenge收集器的老年代版本,繼承了Parallel New多線程對特點,在JDK1.6及之后用來代替老年代的Serial Old收集器;
參數"-XX:+UseParallelOldGC":指定使用Parallel Old收集器;
工作模型圖在Parallel New收集器中展示了。
接下來講解CMS于G1收集器,在將之前要理解一個概念
可能前面也提到過,不過在這里了解以下也不晚
并行(Parallel)
指多條垃圾收集線程并行工作,但此時用戶線程仍然處于等待狀態;
如ParNew、Parallel Scavenge、Parallel Old;
并發(Concurrent)
指用戶線程與垃圾收集線程同時執行(但不一定是并行的,可能會交替執行);
用戶程序在繼續運行,而垃圾收集程序線程運行于另一個CPU上;
如CMS、G1(也有并行);
CMS收集器
并發標記清理收集器也稱為并發低停頓收集器或低延遲垃圾收集器;他的宗旨是:低停頓。
HotSpot在JDK1.5推出的第一款真正意義上的并發(Concurrent)收集器;
他采用的是“標記-清除算法",因此會生大量的空間碎片。為了解決這個問題,CMS可以通過配置以下兩種參數解決:
- -XX:+UseCMSCompactAtFullCollection:參數,強制JVM在FGC完成后対老年代迸行圧縮,執行一次空間碎片整理,但是空間碎片整理階段也會引發STW。為了減少STW次數,CMS還可以通過配置。
- -XX:+CMSFullGCsBeforeCompaction=n :參數,在執行了n次FGC后, JVM再在老年代執行空間碎片整理
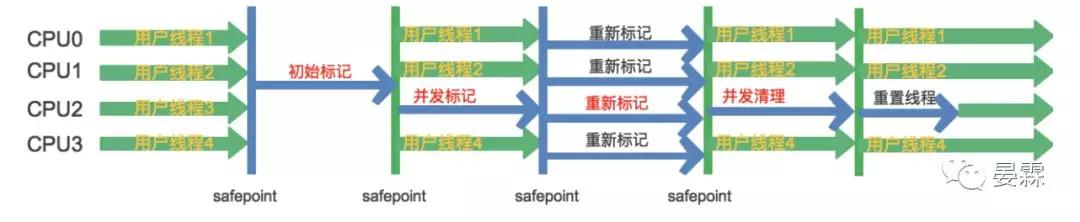
初始標記 (Initial Mark)
停止一切用戶線程,僅使用一條初始標記線程對所有與GC Roots直接相關聯的 老年代對象進行標記,速度很快
并發標記 (Concurrent Marking Phase)
使用多條并發標記線程并行執行,并與用戶線程并發執行.此過程進行可達性分析,標記所有這些對象可達的存貨對象,速度很慢
重新標記 ( Remark)
因為并發標記時有用戶線程在執行,標記結果可能有變化
停止一切用戶線程,并使用多條重新標記線程并行執行,重新遍歷所有在并發標記期間有變化的對象進行最后的標記.這個過程的運行時間介于初始標記和并發標記之間
并發清除 (Concurrent Sweeping)
只使用一條并發清除線程,和用戶線程們并發執行,清除剛才標記的對象
這個過程非常耗時
G1收集器
G1(Garbage-First)是JDK7-u4才推出商用的收集器;他比CMS更高級了,他是并行與并發,能充分利用多CPU、多核環境下的硬件優勢;
G1以下特點
并行與并發
能充分利用多CPU、多核環境下的硬件優勢;
可以并行來縮短"Stop The World"停頓時間;
也可以并發讓垃圾收集與用戶程序同時進行;
分代收集,收集范圍包括新生代和老年代
能獨立管理整個GC堆(新生代和老年代),而不需要與其他收集器搭配;
能夠采用不同方式處理不同時期的對象;
雖然保留分代概念,但Java堆的內存布局有很大差別;
將整個堆劃分為多個大小相等的獨立區域(Region);
新生代和老年代不再是物理隔離,它們都是一部分Region(不需要連續)的集合;
結合多種垃圾收集算法,空間整合,不產生碎片
從整體看,是基于標記-整理算法;
從局部(兩個Region間)看,是基于復制算法;
這是一種類似火車算法的實現;
都不會產生內存碎片,有利于長時間運行;
可預測的停頓:低停頓的同時實現高吞吐量
G1除了追求低停頓處,還能建立可預測的停頓時間模型;
可以明確指定M毫秒時間片內,垃圾收集消耗的時間不超過N毫秒;
如:在堆大小約6GB或更大時,可預測的暫停時間可以低于0.5秒;
用來替換掉JDK1.5中的CMS收集器;
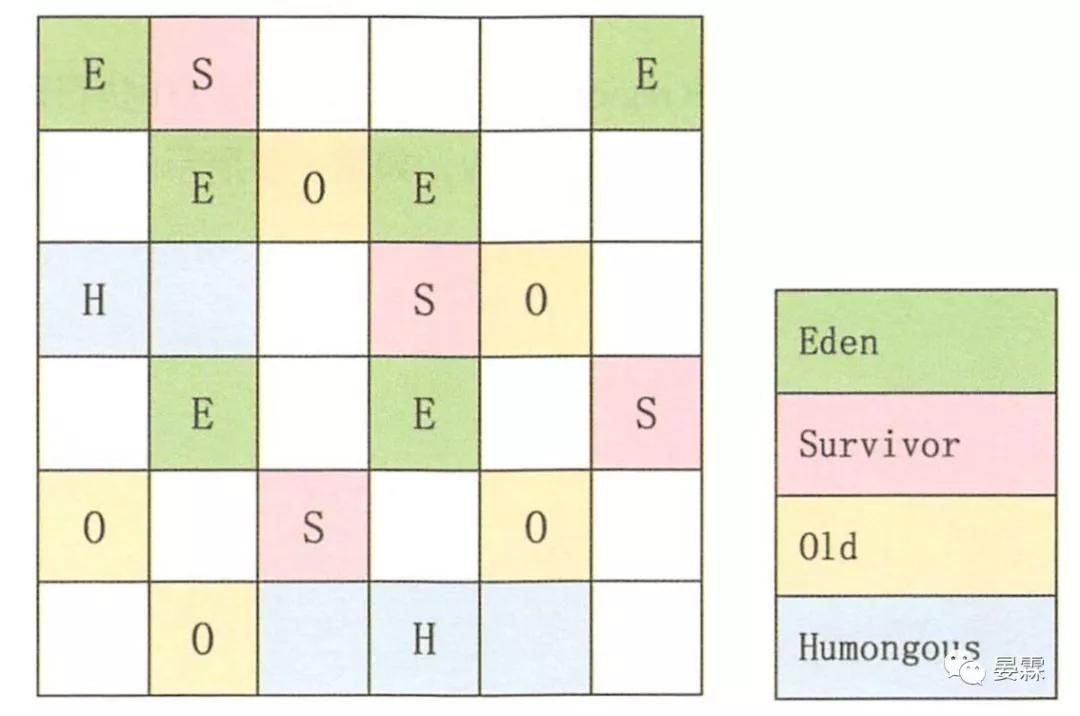
上面提到Region 概念,肯定都不會理解,讓我們看一下G1的內存模型
G1將Java堆空間分割成了若干相同大小的區域,即region
Humongous是特殊的Old類型,專門放置大型對象
在JDK11中,已經將G1設為默認垃圾回收器
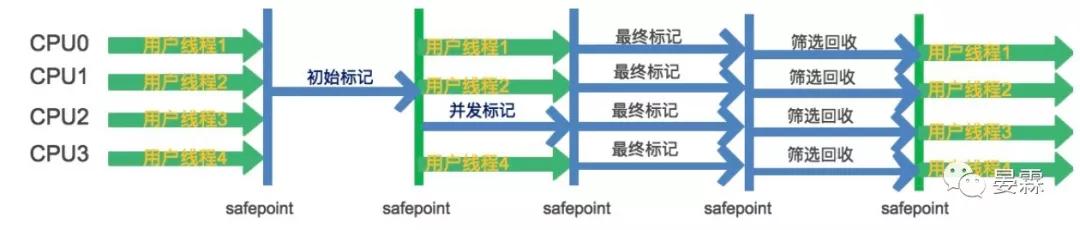
G1垃圾收集過程
初始標記
標記與GC Roots直接關聯的對象,停止所有用戶線程,只啟動一條初始標記線程,這個過程很快。
并發標記
進行全面的可達性分析,開啟一條并發標記線程與用戶線程并行執行.這個過程比較長。
最終標記
標記出并發標記過程中用戶線程新產生的垃圾.停止所有用戶線程,并使用多條最終標記線程并行執行。
篩選回收
回收廢棄的對象.此時也需要停止一切用戶線程,并使用多條篩選回收線程并行執行。
題外話:我們知道目前為止JDK8是應用最廣泛對版本,并且JDK9、10是一個過度版,企業應用效果不好,JDK11是一個里程碑版本,重要程度相當于現在JDK8,并且JDK11默認使用G1收集器,G1的性能在早些年就突出于CMS并且官方對性能測試結果也是這樣說明的。
本文轉載自微信公眾號「 晏霖」,可以通過以下二維碼關注。轉載本文請聯系 晏霖公眾號。