













Hadoop 3的主要優(yōu)缺點(diǎn)
本文的目的是討論Hadoop 3.0的優(yōu)缺點(diǎn)。隨著Hadoop 3.0中引入了許多更改,它已成為更好的產(chǎn)品。
Hadoop 3的主要優(yōu)缺點(diǎn)
Hadoop旨在存儲(chǔ)和管理大量數(shù)據(jù)。Hadoop有許多優(yōu)點(diǎn),例如,它是免費(fèi)和開源的,易于使用的,其性能等。但是,另一方面,它也有一些缺點(diǎn)。因此,讓我們開始探索Hadoop的主要優(yōu)點(diǎn)和缺點(diǎn)。
Hadoop的優(yōu)勢(shì)
Hadoop易于使用,可擴(kuò)展且具有成本效益。在這里,我們將討論Hadoop的12大優(yōu)勢(shì)
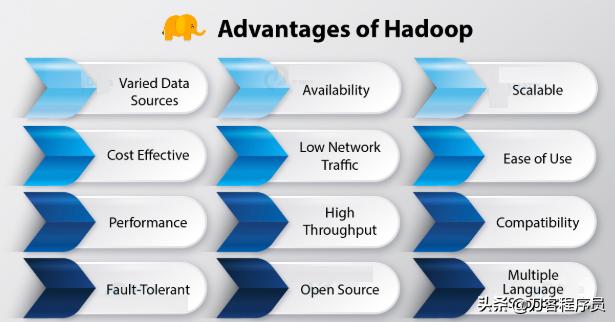
Hadoop的優(yōu)勢(shì)
1.各種數(shù)據(jù)源
Hadoop存儲(chǔ)各種數(shù)據(jù)。數(shù)據(jù)可以來(lái)自各種來(lái)源,并且可以是結(jié)構(gòu)化或非結(jié)構(gòu)化的形式。Hadoop可以從各種數(shù)據(jù)中獲取價(jià)值。Hadoop可以接受文本文件,XML文件,圖像,CSV文件等中的數(shù)據(jù)。
2.高性價(jià)比
Hadoop是一種經(jīng)濟(jì)的解決方案,因?yàn)樗褂眉簛?lái)存儲(chǔ)數(shù)據(jù)。而硬件是便宜的機(jī)器,因此將節(jié)點(diǎn)添加到框架的成本不是很高。在Hadoop 3.0中,只有50%的存儲(chǔ)開銷,而在Hadoop2.x中只有200%。由于冗余數(shù)據(jù)顯著減少,因此需要較少的機(jī)器來(lái)存儲(chǔ)數(shù)據(jù)。
3.表現(xiàn)
Hadoop及其分布式處理和分布式存儲(chǔ)體系結(jié)構(gòu)可高速處理大量數(shù)據(jù)。Hadoop甚至在2008年擊敗超級(jí)計(jì)算機(jī)成為最快的計(jì)算機(jī)。它將輸入數(shù)據(jù)文件劃分為多個(gè)塊,并將數(shù)據(jù)存儲(chǔ)在多個(gè)節(jié)點(diǎn)上的block塊中。它還將用戶提交的任務(wù)分為多個(gè)子任務(wù),這些子任務(wù)分配給包含所需數(shù)據(jù)的這些工作節(jié)點(diǎn),并且這些子任務(wù)并行運(yùn)行,從而提高了性能。
4.容錯(cuò)
在Hadoop 3.0中,擦除編碼提供了容錯(cuò)能力。例如,6個(gè)數(shù)據(jù)塊通過使用擦除編碼技術(shù)產(chǎn)生3個(gè)奇偶校驗(yàn)塊,因此HDFS總共存儲(chǔ)了這9個(gè)塊。如果任何節(jié)點(diǎn)發(fā)生故障,可以使用這些奇偶校驗(yàn)塊和其余數(shù)據(jù)塊來(lái)恢復(fù)受影響的數(shù)據(jù)塊。
5.高度可用
在Hadoop 2.x中,HDFS架構(gòu)具有一個(gè)活動(dòng)的NameNode和一個(gè)Standby NameNode,因此,如果NameNode發(fā)生故障,則我們可以依靠備用NameNode。但是Hadoop 3.0支持多個(gè)備用NameNode,從而使系統(tǒng)具有更高的可用性,因此如果兩個(gè)或多個(gè)NameNode崩潰,它可以繼續(xù)運(yùn)行。
6.低網(wǎng)絡(luò)流量
在Hadoop中,用戶提交的每個(gè)作業(yè)都被分為多個(gè)獨(dú)立的子任務(wù),并且這些子任務(wù)被分配給數(shù)據(jù)節(jié)點(diǎn),從而將少量代碼移動(dòng)到數(shù)據(jù)中,而不是將大量數(shù)據(jù)移動(dòng)到代碼中,從而導(dǎo)致低網(wǎng)絡(luò)流量。
7.高通量
吞吐量是指單位時(shí)間內(nèi)完成的工作。Hadoop以分布式方式存儲(chǔ)數(shù)據(jù),從而可以輕松地使用分布式處理。給定的作業(yè)分為多個(gè)小作業(yè),這些作業(yè)并行處理數(shù)據(jù)塊,從而提供高吞吐量。
8.開源
Hadoop是一種開源技術(shù),即其源代碼可免費(fèi)獲得。我們可以修改源代碼以適合特定要求。
9.可擴(kuò)展
Hadoop按照水平可伸縮性原理工作,即我們需要將整個(gè)計(jì)算機(jī)添加到節(jié)點(diǎn)群集中,而不要像添加RAM,磁盤等那樣更改計(jì)算機(jī)的配置,這被稱為垂直可伸縮性。可以將節(jié)點(diǎn)動(dòng)態(tài)添加到Hadoop集群,使其成為可擴(kuò)展的框架。
10.易于使用
Hadoop框架提供分布式編程模型,MapReduce的程序員只需按固定的模板編寫分布式計(jì)算程序,而不需要關(guān)心他們?nèi)绾螌?shí)現(xiàn)分布式處理,它是在后臺(tái)自動(dòng)完成。
11.相容性
大數(shù)據(jù)的大多數(shù)新興技術(shù)都與Hadoop兼容,例如Spark,F(xiàn)link等。它們具有在Hadoop上作為后端工作的處理引擎,即我們將Hadoop用作它們的數(shù)據(jù)存儲(chǔ)平臺(tái)。
12.支持多種語(yǔ)言
開發(fā)人員可以在Hadoop上使用多種語(yǔ)言(例如C,C ++,Perl,Python,Ruby和Groovy)進(jìn)行編碼。
Hadoop的缺點(diǎn)
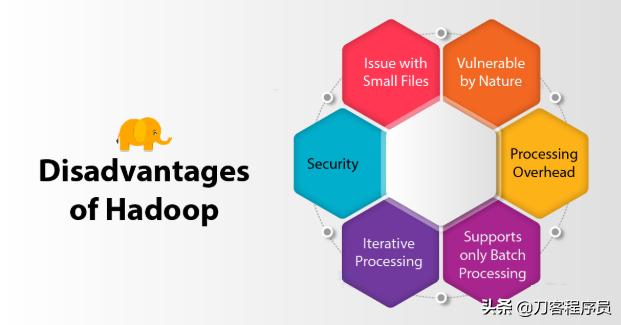
Hadoop的缺點(diǎn)
1.小文件問題
Hadoop適用于處理相對(duì)較大的文件,但是涉及到處理大量小文件的時(shí)(小文件比Hadoop的塊大小小得多的文件,默認(rèn)情況下,該塊大小可以為128MB或256MB),Hadoop效率不高。這些大量的小文件使Namenode過載,因?yàn)镹amenode存儲(chǔ)了系統(tǒng)的名稱空間,并使Hadoop難以運(yùn)行。
2.天生脆弱
Hadoop用Java編寫,Java是一種廣泛使用的編程語(yǔ)言,因此它容易被網(wǎng)絡(luò)犯罪分子利用,這使得Hadoop容易受到安全漏洞的攻擊。
3.處理費(fèi)用
在Hadoop中,數(shù)據(jù)是從磁盤讀取并寫入磁盤的,這在我們處理兆兆字節(jié)和PB級(jí)數(shù)據(jù)時(shí)使讀/寫操作非常昂貴。Hadoop無(wú)法執(zhí)行內(nèi)存中計(jì)算,因此會(huì)增加處理開銷。
4.僅支持批處理
Hadoop的核心是一個(gè)批處理引擎,該引擎在流處理方面效率不高。它不能以低延遲實(shí)時(shí)生成輸出。它僅適用于我們?cè)谔幚碇邦A(yù)先收集并存儲(chǔ)在文件中的數(shù)據(jù)。
5.迭代處理
Hadoop本身無(wú)法進(jìn)行迭代處理。機(jī)器學(xué)習(xí) 或迭代處理具有周期性的數(shù)據(jù)流,而Hadoop的數(shù)據(jù)是在多個(gè)階段鏈中流動(dòng)的,其中一個(gè)階段的輸出成為另一階段的輸入。
6.安全性
為了安全起見,Hadoop使用難以管理的Kerberos身份驗(yàn)證。它缺少存儲(chǔ)和網(wǎng)絡(luò)級(jí)別的加密,這是一個(gè)主要問題。
總結(jié)– Hadoop的優(yōu)缺點(diǎn)
業(yè)界使用的每種軟件都有其自身的缺點(diǎn)和好處。如果該軟件對(duì)業(yè)務(wù)至關(guān)重要,則可以利用其優(yōu)勢(shì)并采取措施以最大程度地減少故障。我們可以看到Hadoop的優(yōu)點(diǎn)大于缺點(diǎn),這使其成為滿足大數(shù)據(jù)需求的強(qiáng)大解決方案。















